Package Version Citation
1 base 4.2.2 @base
2 correlation 0.8.4 @
3 easystats 0.6.0.8 @easystats
4 ggstatsplot 0.9.4 @ggstatsplot
5 knitr 1.41 @knitr2014; @knitr2015; @knitr2022
6 pacman 0.5.1 @pacman
7 rmarkdown 2.14 @rmarkdown2018; @rmarkdown2020; @rmarkdown2022
8 see 0.8.0.2 @see
9 tidyverse 1.3.2 @tidyverse
10 xaringan 0.26 @xaringan
11 xaringanExtra 0.7.0 @xaringanExtra
12 xaringanthemer 0.4.1 @xaringanthemerNHST and p-values (Everything you ever wanted to know about p-values)
Princeton University
2023-10-09
Recap
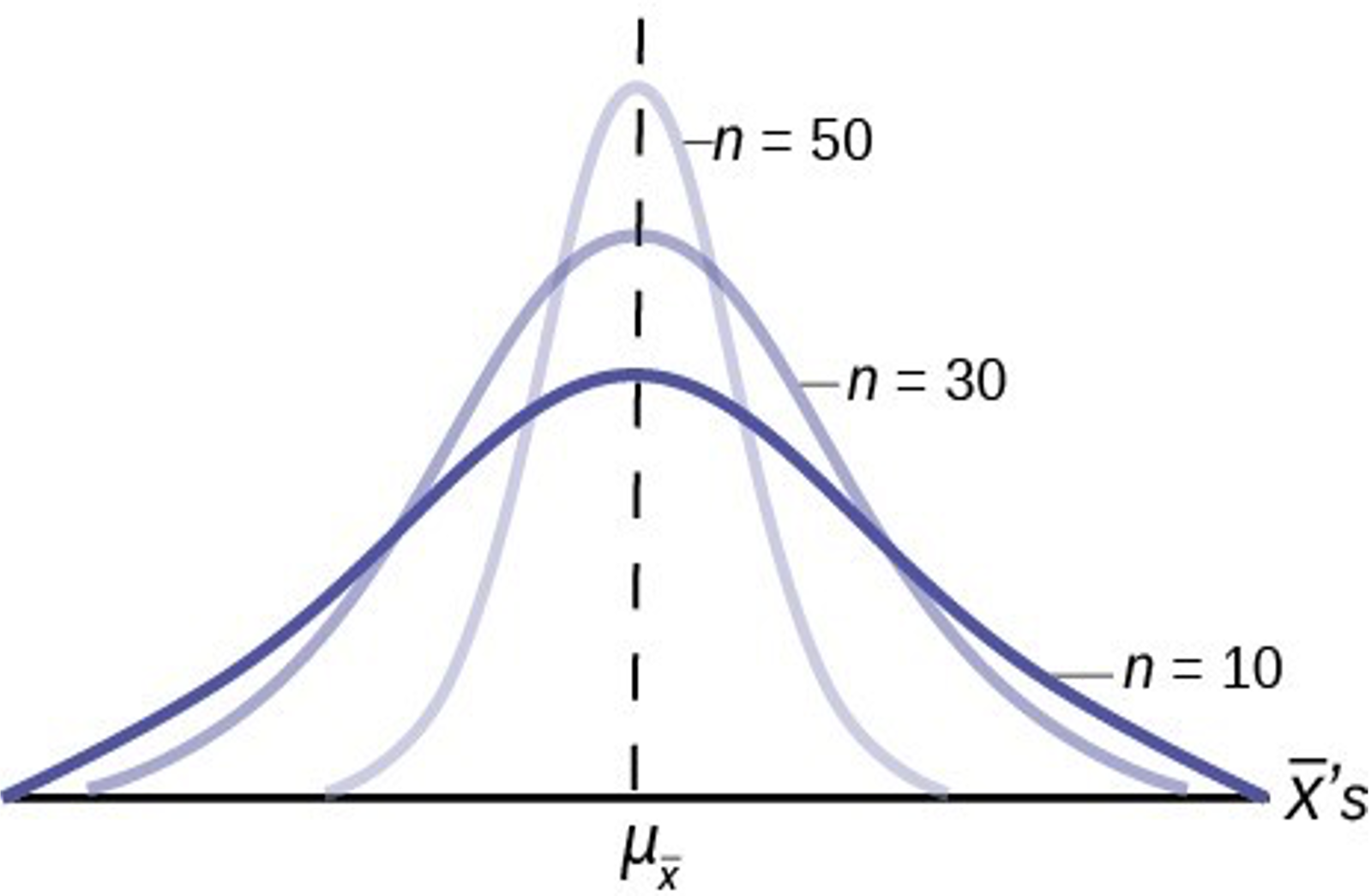
- As n increases we become more confident (less spread) of our estimate of the population mean
Recap: t distribution
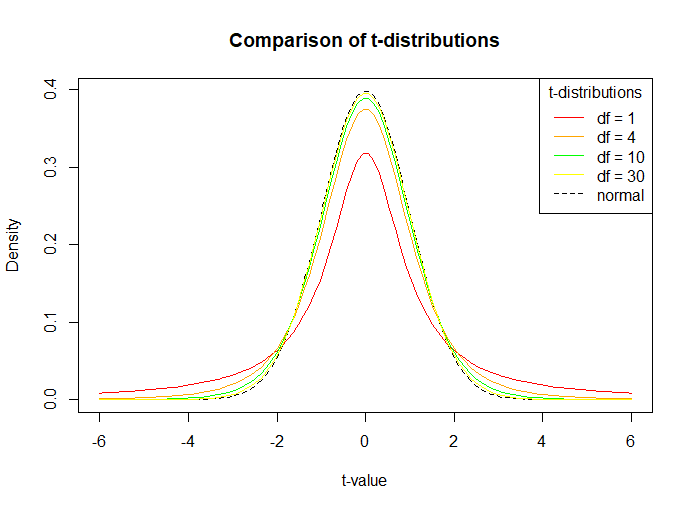
if \(\sigma\) unknown, we need to use t distribution
Similar to normal, but fatter tails (more conservative) for lower DF
Two Tailed Test
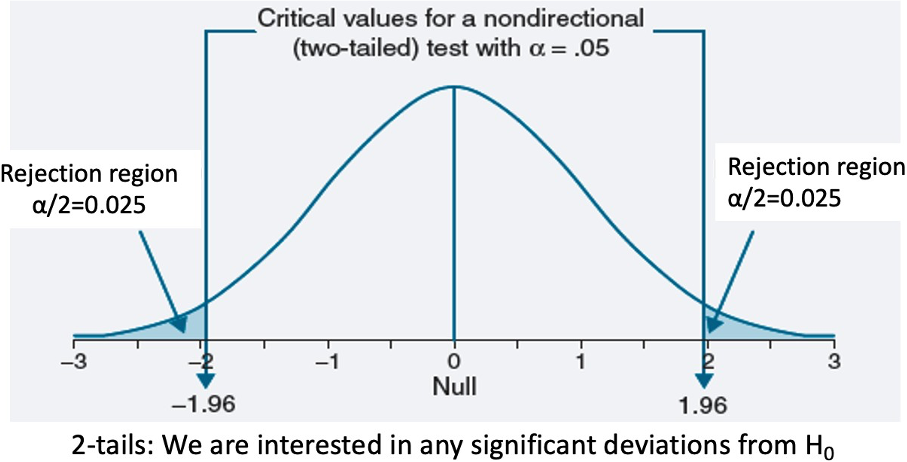
The sum of the tails sums to α (0.025 in each tail for a two-tailed when α = 0.05)
See where the statistic lies relative to a ‘critical score’ that depends on defined alpha (same procedure used to calculate confidence intervals)
For the right and left tail, if the test statistic > 1.96 or less than -1.96 (critical value) reject null & accept alternative
One Tailed Test
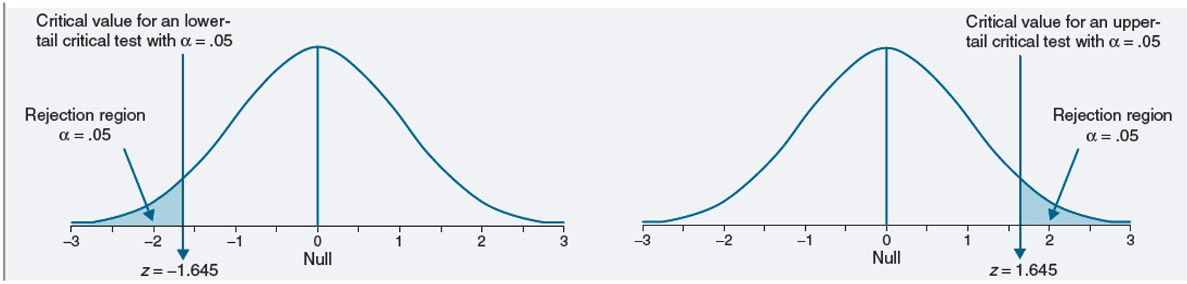
0.05 in each tail
If statistic within rejection region = reject null & accept alternative
Do you see why you get power with a one-sided / directional hypothesis?
P-worship

P-hacking
P-hacking: trying lots of analyses until you get desired outcome

p-value
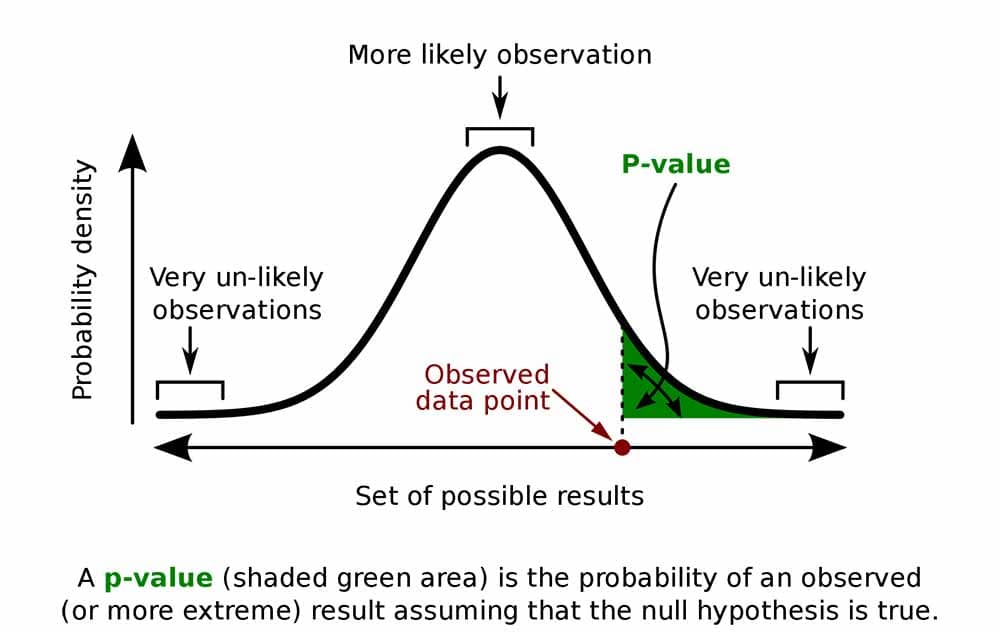
p-value Conventions
- Conventions:
- p < 0.05: significant evidence against \(H_0\)
- p > 0.10: non-significant evidence against \(H_0\)
- 0.05 < p < 0.10: marginally significant evidence against \(H_0\)

p-value conventions

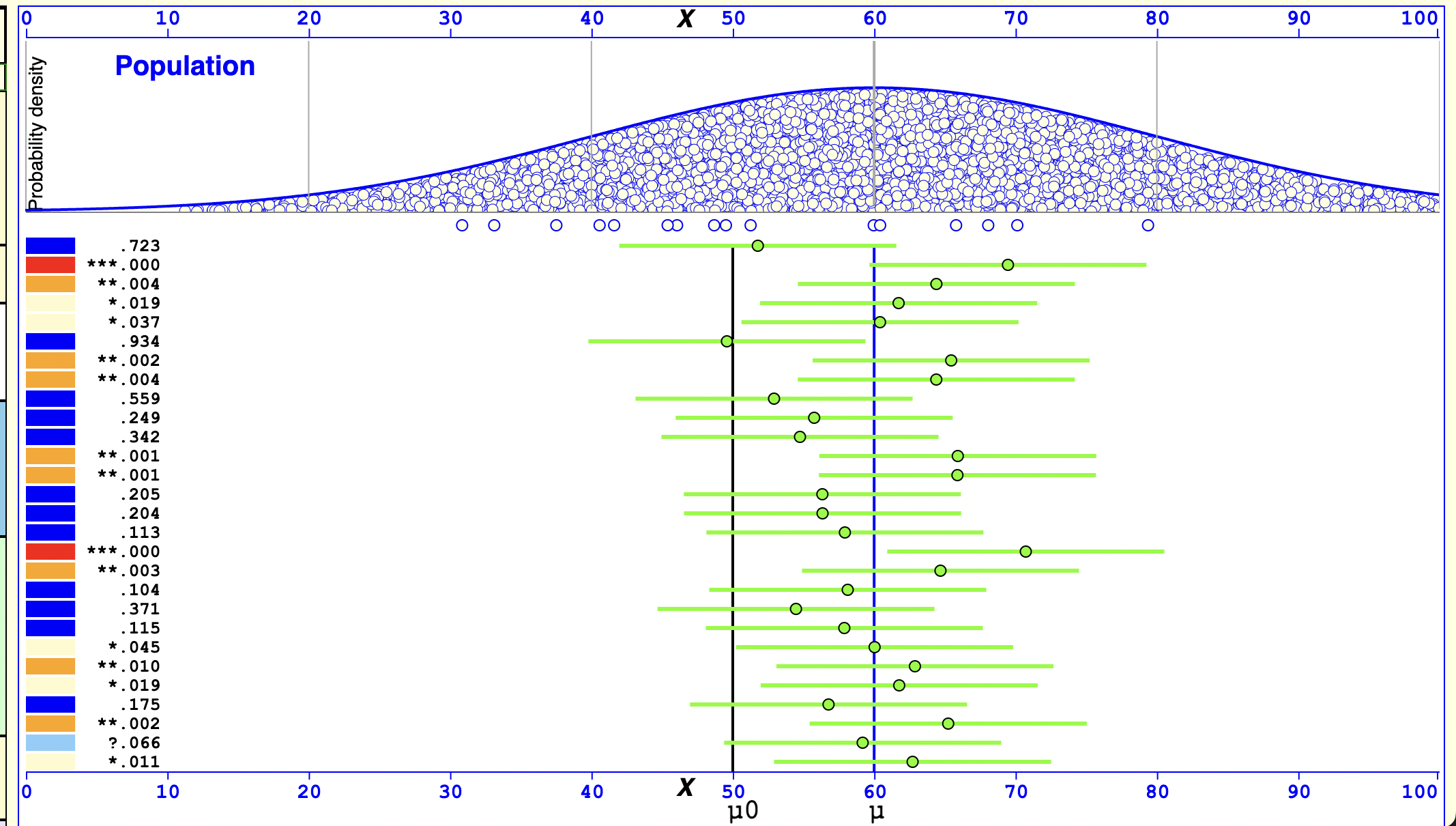
Which p-values can you expect?
- Which p-values can you expect to observe if there is a true effect, and you repeat the same study 100000 times?
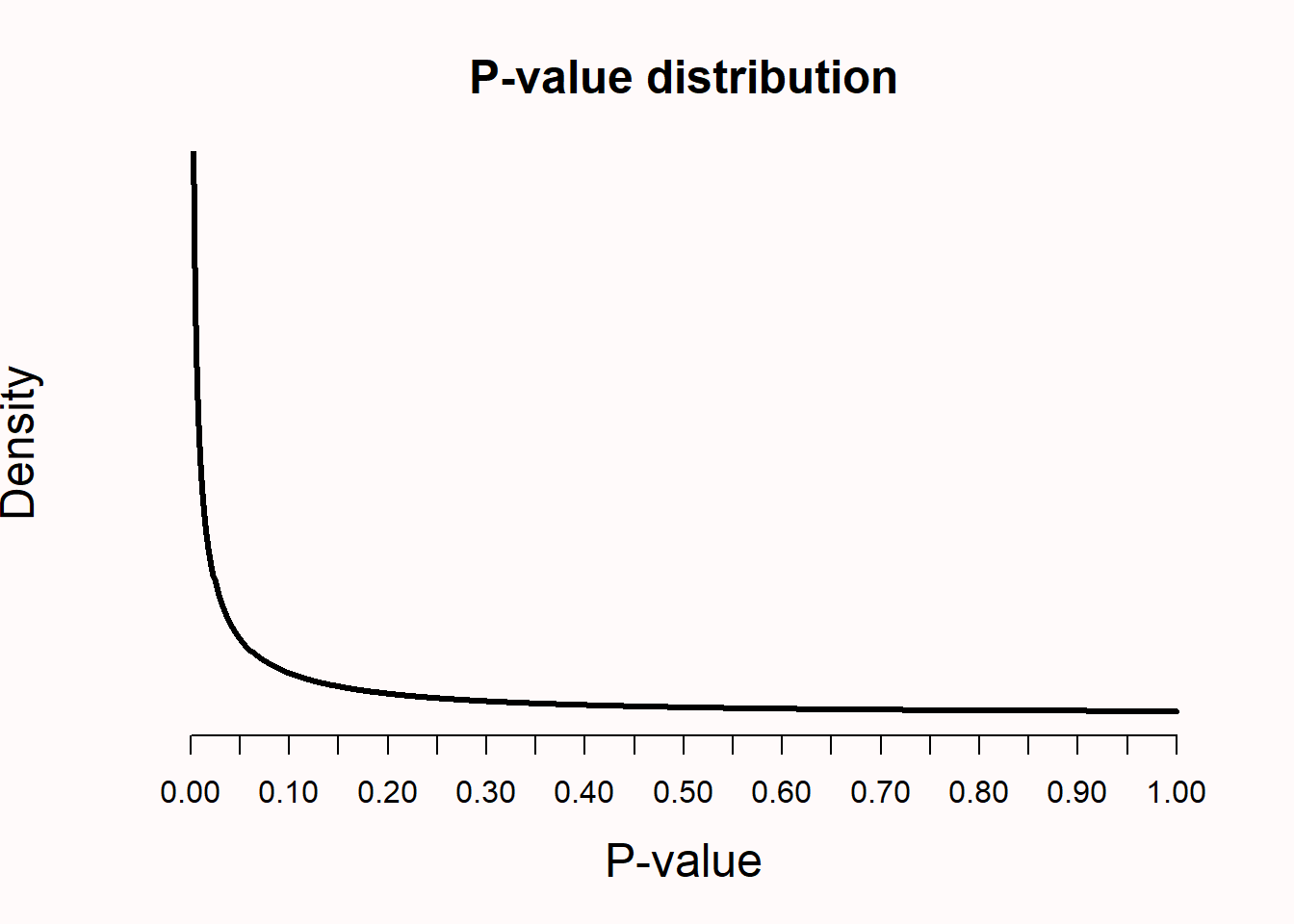
Lakens
Which p-values can you expect?
- Which p-values can you expect if there is no true effect, and you repeat the same study 100000 times?
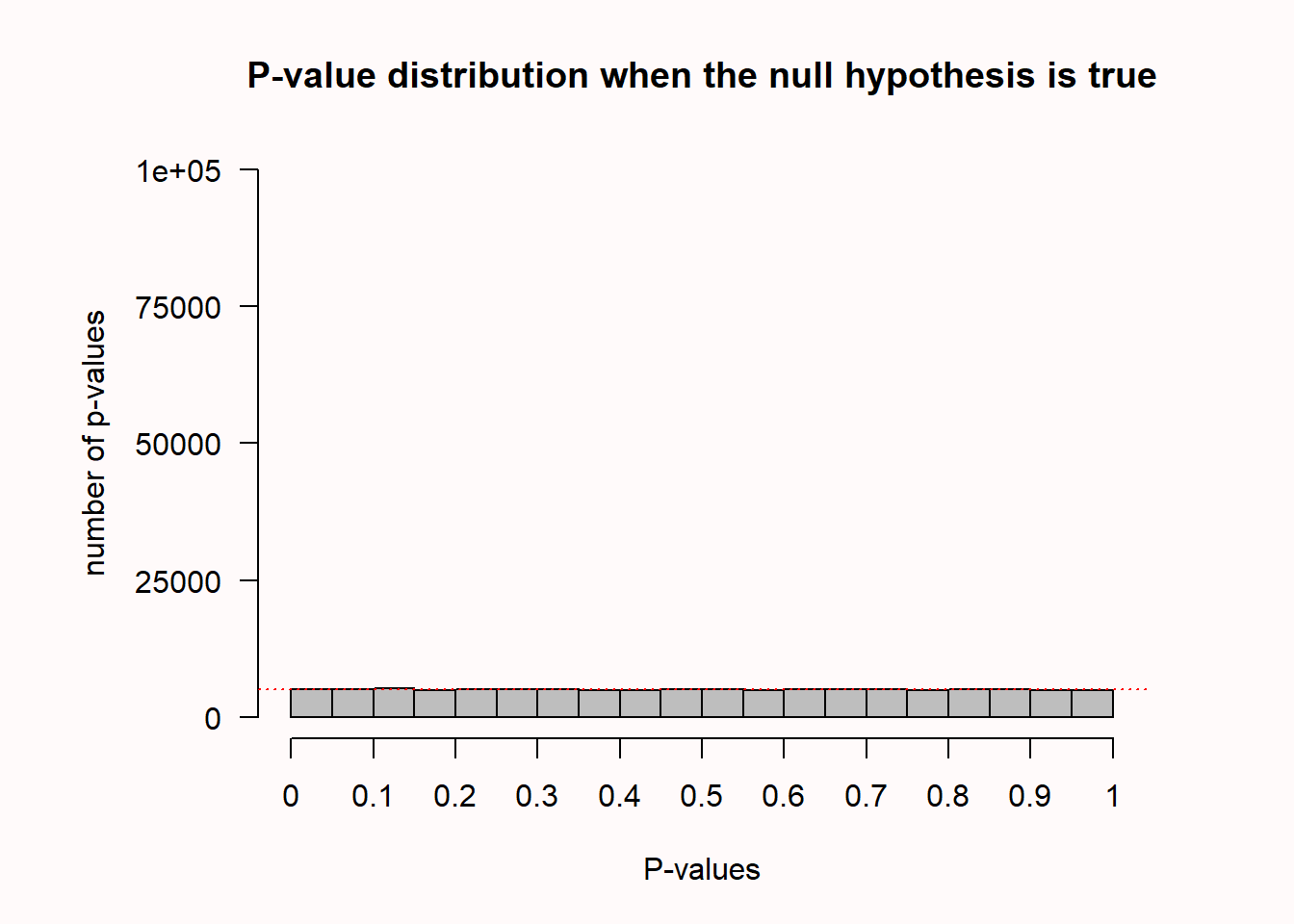
Lakens
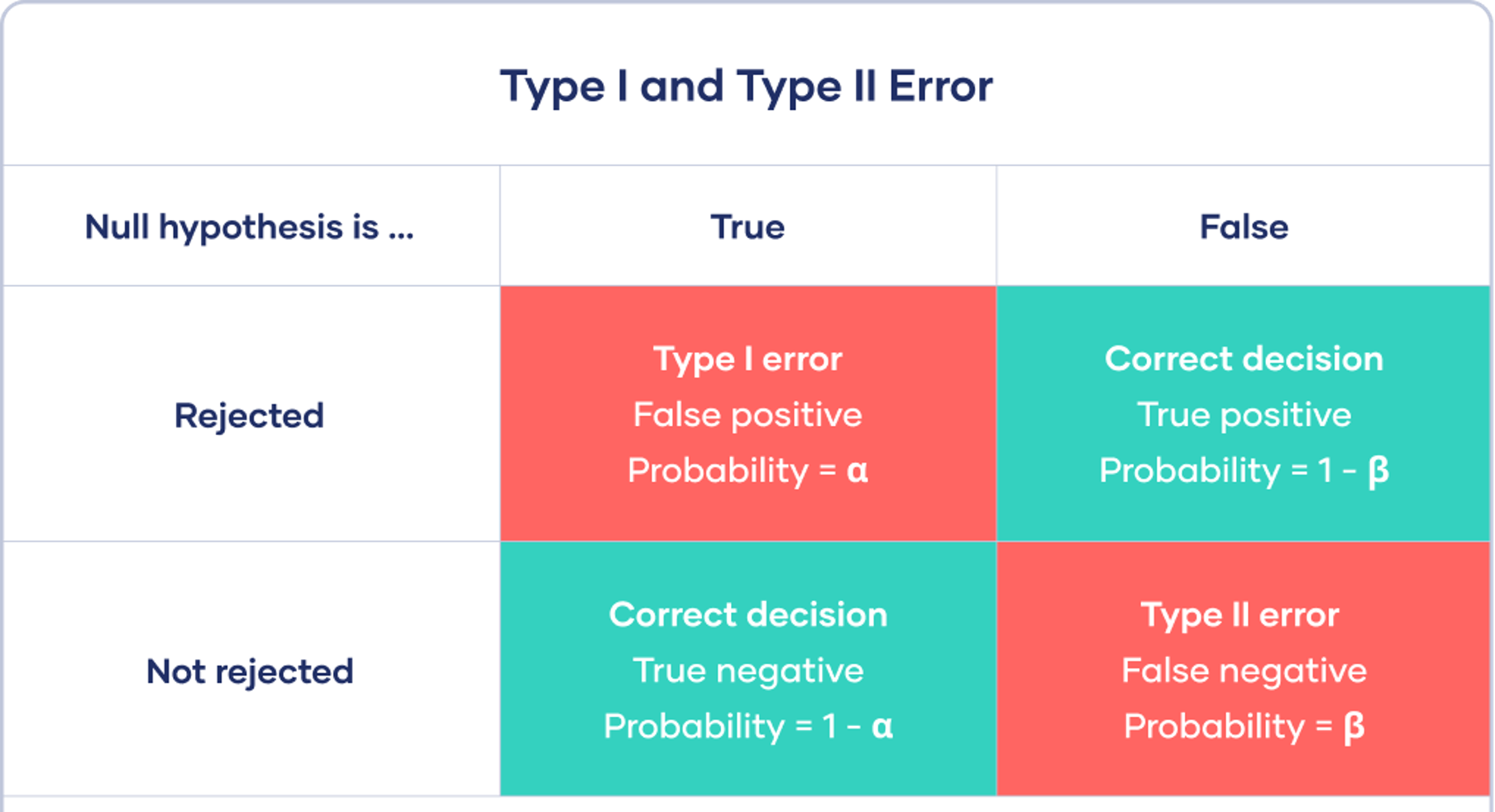
Type 1 and Type 2 Error Rates
- You think the manipulation worked, but it really doesn’t
- Type 1 error
- You don’t think the manipulation worked, but it really does
- Type 2 error

Type 1 and Type 2 Error Rates
p-value misconceptions (Lakens)
Misconception 1: A non-significant p-value means that the null hypothesis is true
Common to say:
p > .05, the null hypothesis is true
p > .05, there is no effect
p-value Misconceptions (Lakens)
Misconception 2: A significant p-value means that the null hypothesis is false
Common to use:
p < .05, the null hypothesis is false or the alternative is true
p < .05, there is an effect
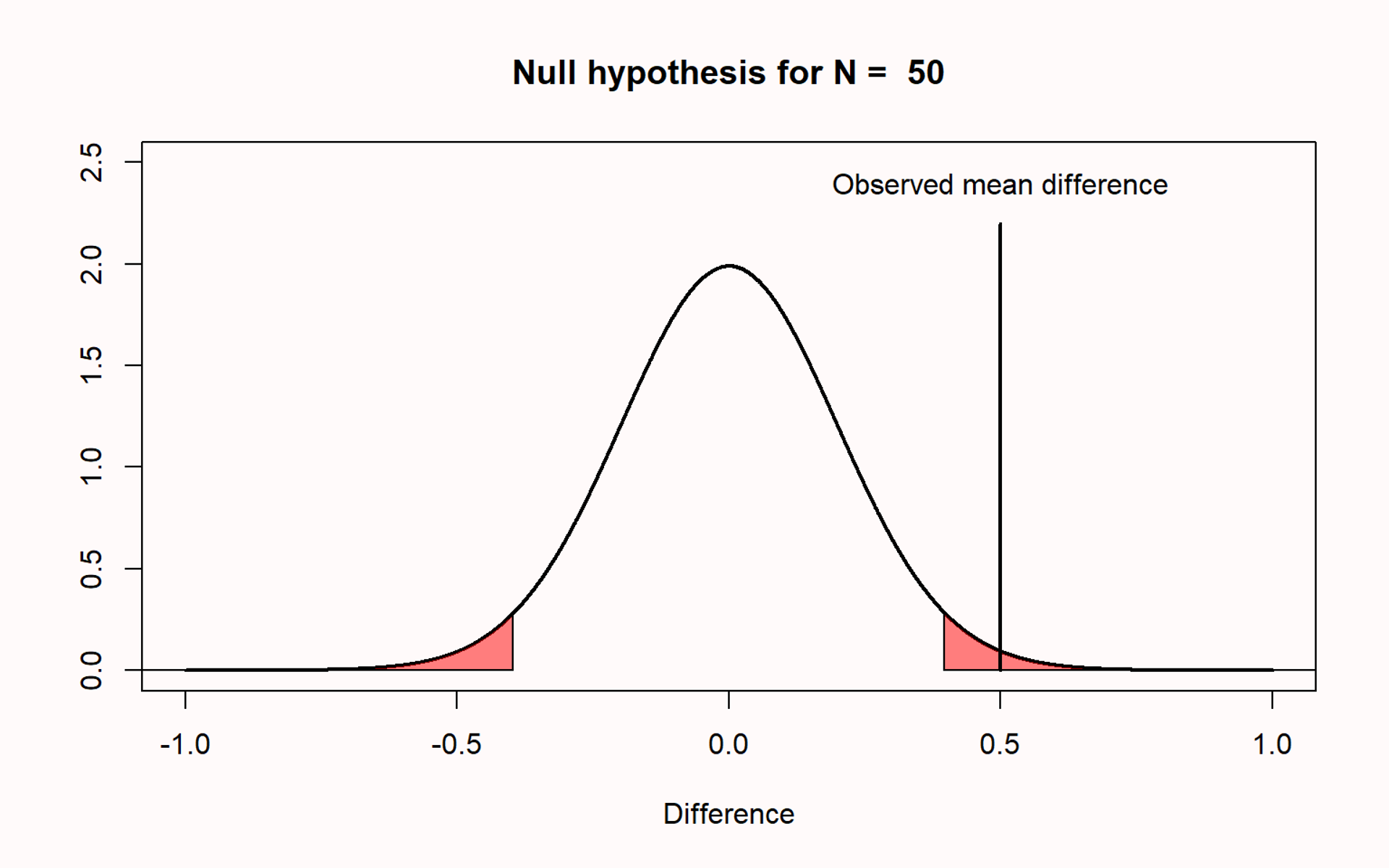
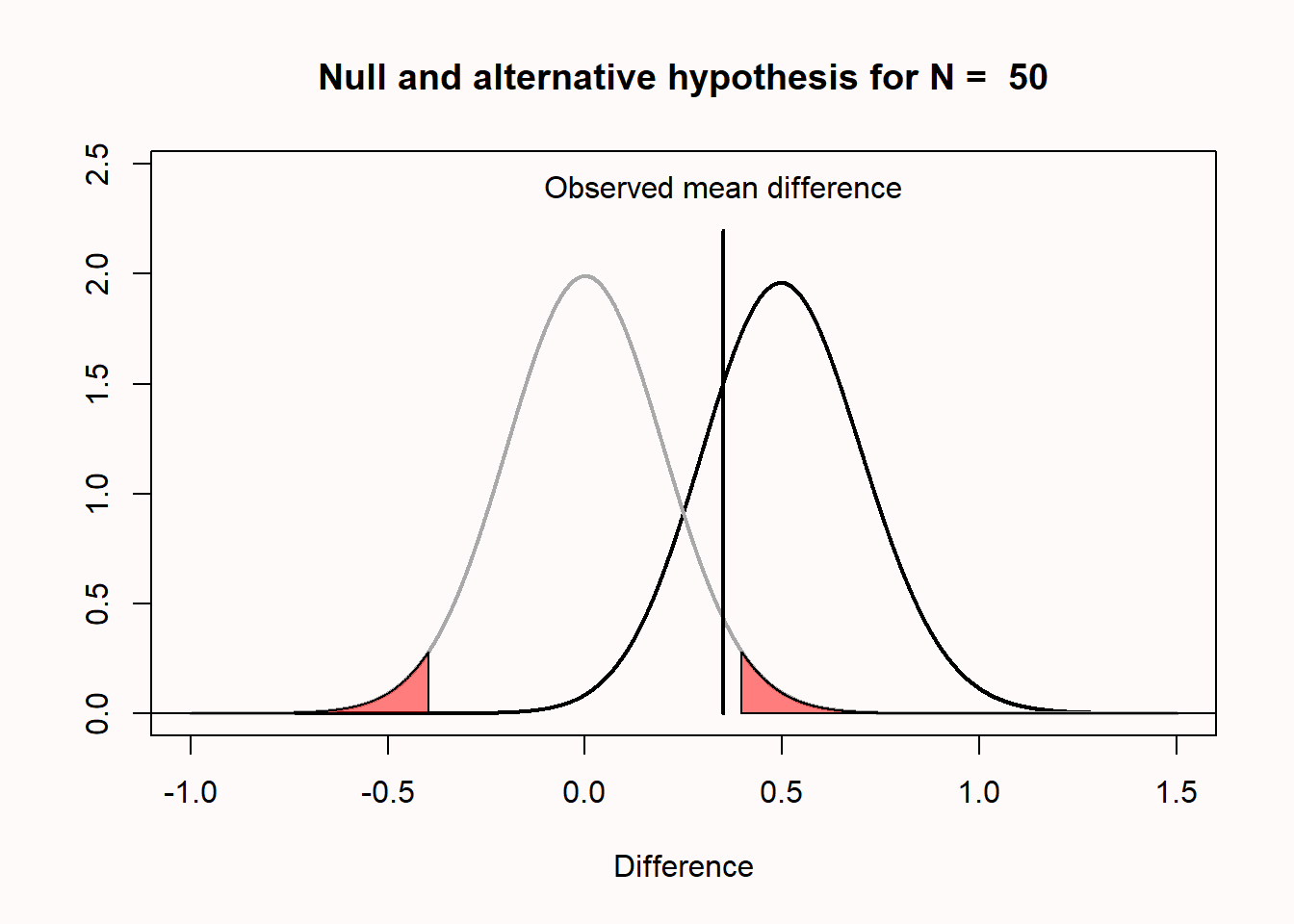
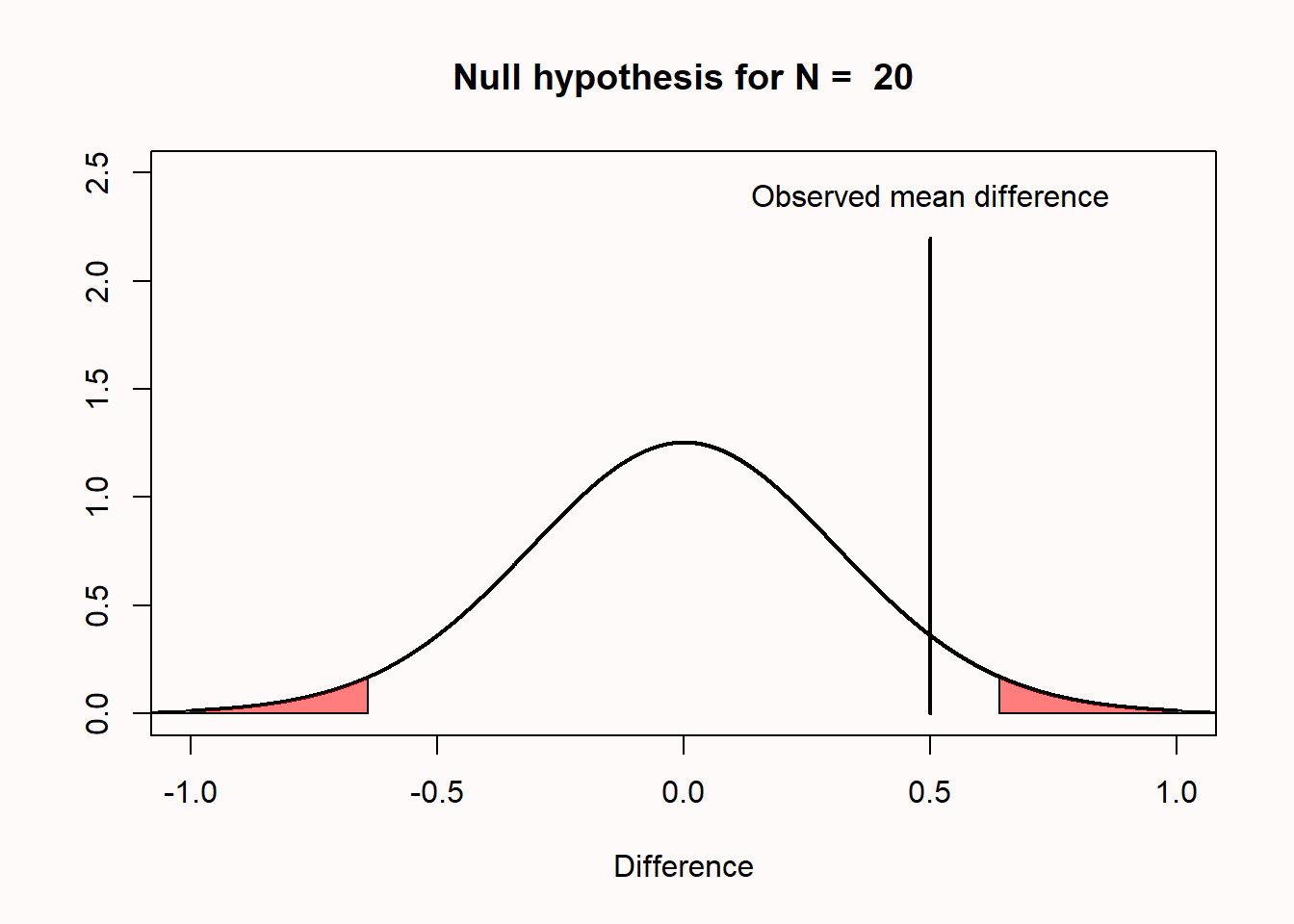
p-value Misconceptions (Lakens)
Misconception 4: If you have observed a significant finding, the probability that you have made a Type 1 error (a false positive) is 5%
Type 1 error rate references all studies we will perform in the future where the null hypothesis is true
Not more than 5% of our observed mean differences will fall in the red tail areas
![]()
p value Misconceptions (Lakens)
Misconception 5: One minus the p-value is not the probability of observing another significant result when the experiment is replicated
- The dance of the ps
Dataset
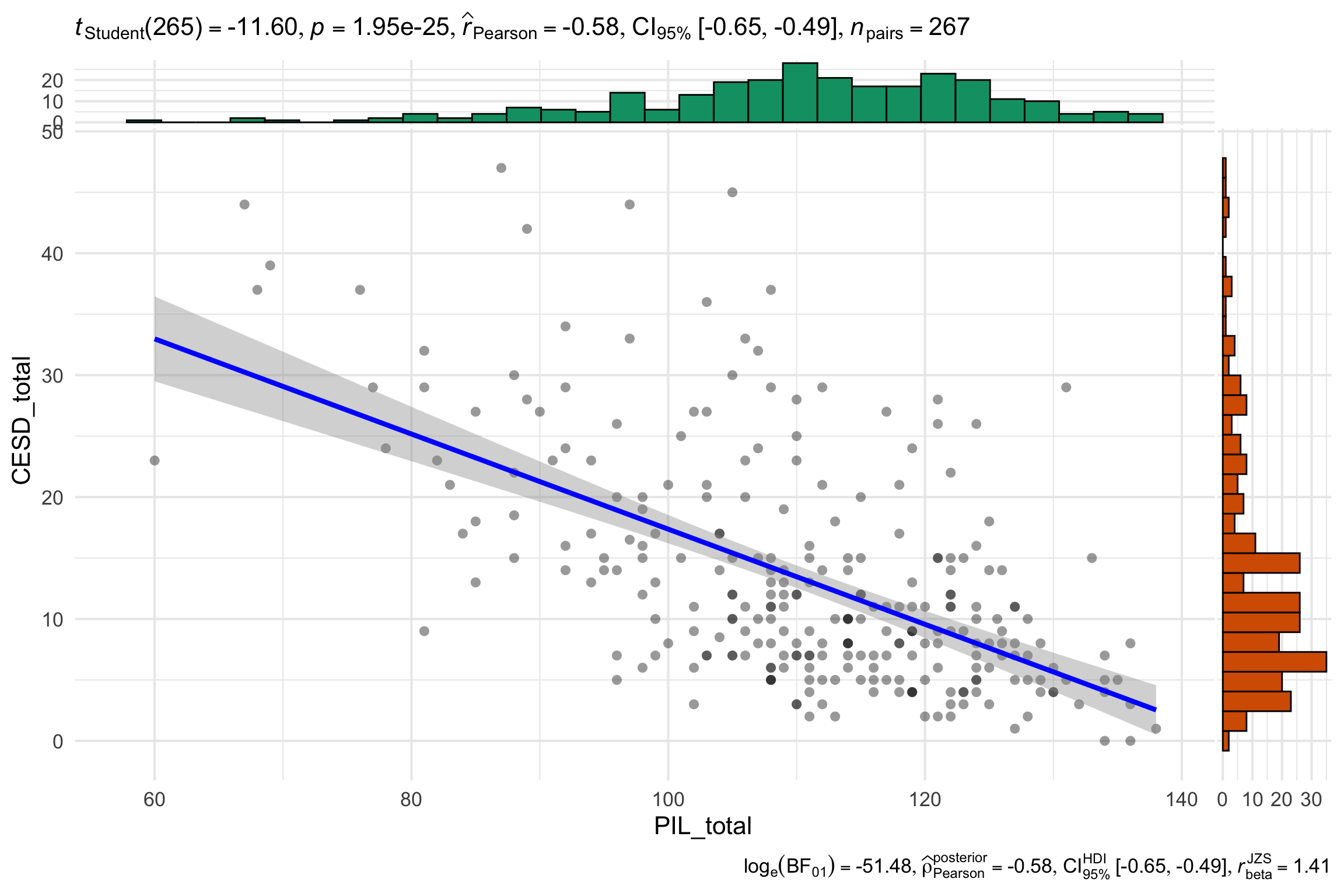
Correlations
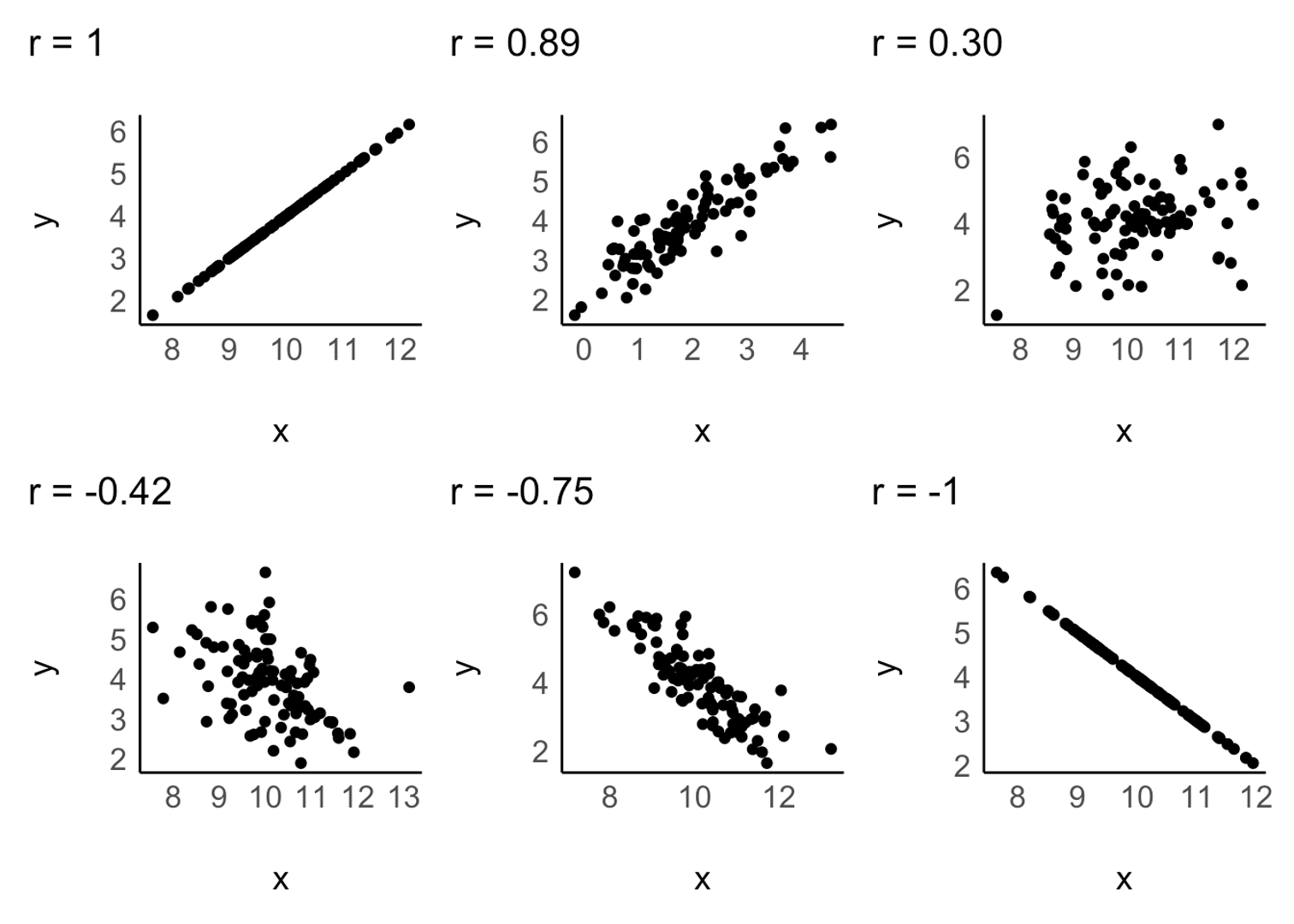
Scatter plot
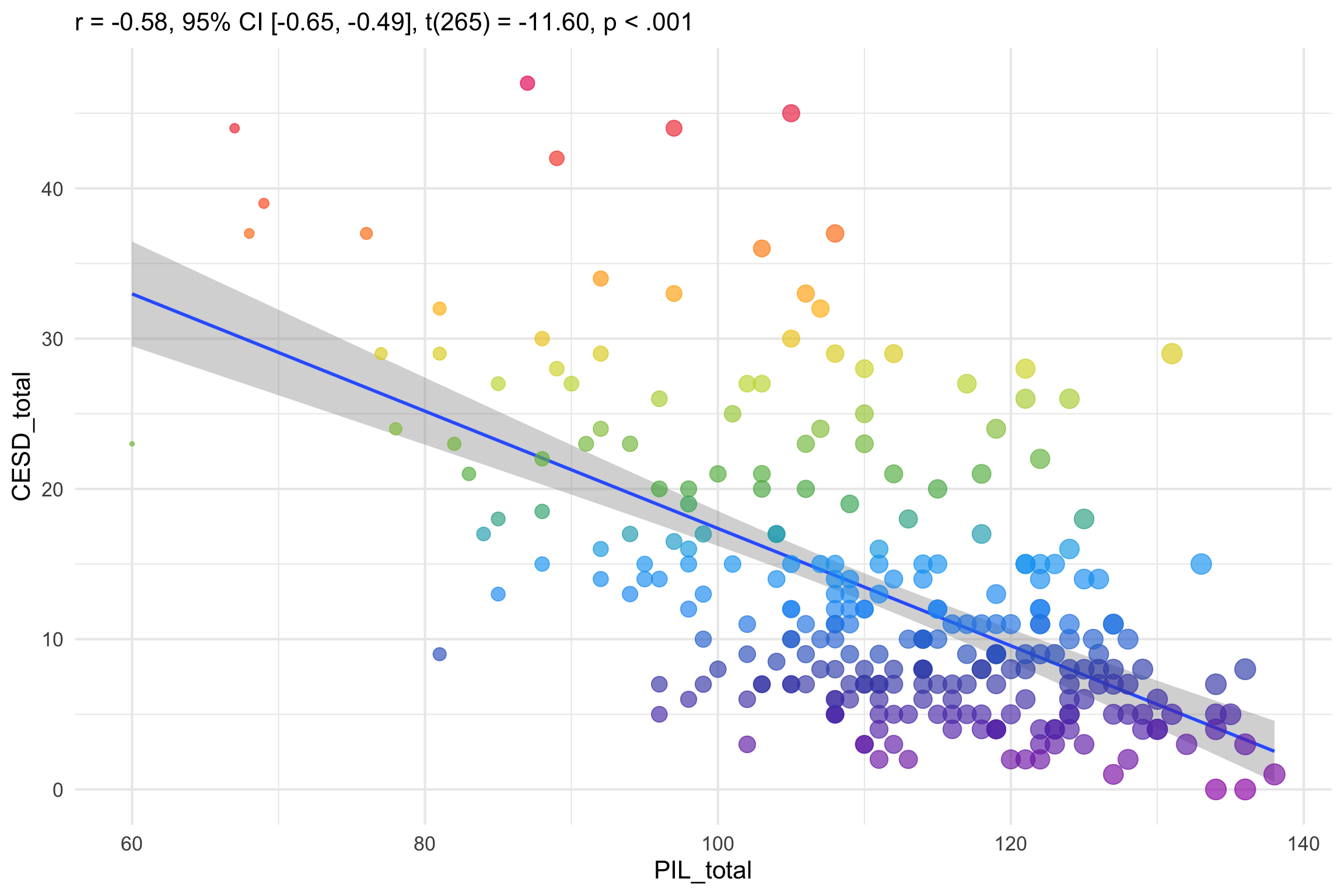
Scatter plot