Package Version Citation
1 base 4.2.2 @base
2 cowplot 1.1.1 @cowplot
3 infer 1.0.3 @infer
4 knitr 1.41 @knitr2014; @knitr2015; @knitr2022
5 moderndive 0.5.4 @moderndive
6 pacman 0.5.1 @pacman
7 rmarkdown 2.14 @rmarkdown2018; @rmarkdown2020; @rmarkdown2022
8 tidyverse 1.3.2 @tidyverse
9 xaringan 0.26 @xaringan
10 xaringanExtra 0.7.0 @xaringanExtra
11 xaringanthemer 0.4.1 @xaringanthemerStatistical Inference: Populations, Sampling Distributions, and Uncertainty
Princeton University
2023-10-07
Population
Entire collection of units interested in studying
- Clearly defined
- Typically large

Sample
Smaller subsets of population

Statistical Inference
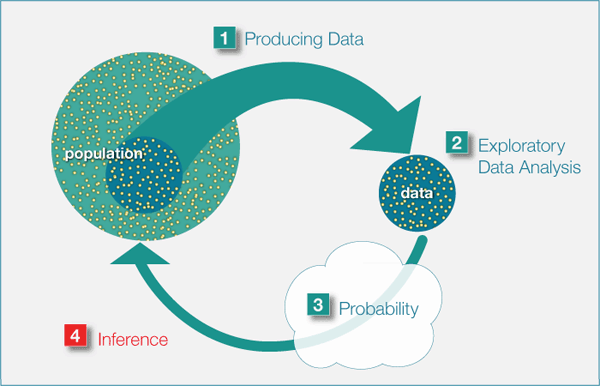
Estimation
Parameters and Statistics
Parameter
- Characteristics of the population
Statistics: Estimates of population parameters
- This is a random variable! We can create a sampling distribution from this
10,000 Times
ggplot(virtual_prop_red, aes(x = prop_red)) +
geom_histogram(binwidth = 0.05, boundary = 0.4, color = "white") +
geom_vline(xintercept =.37, colour="green", linetype = "longdash")+
labs(x = "Proportion of 50 balls that were red",
title = "Distribution of 10,000 proportions red") +
theme_minimal(base_size = 16)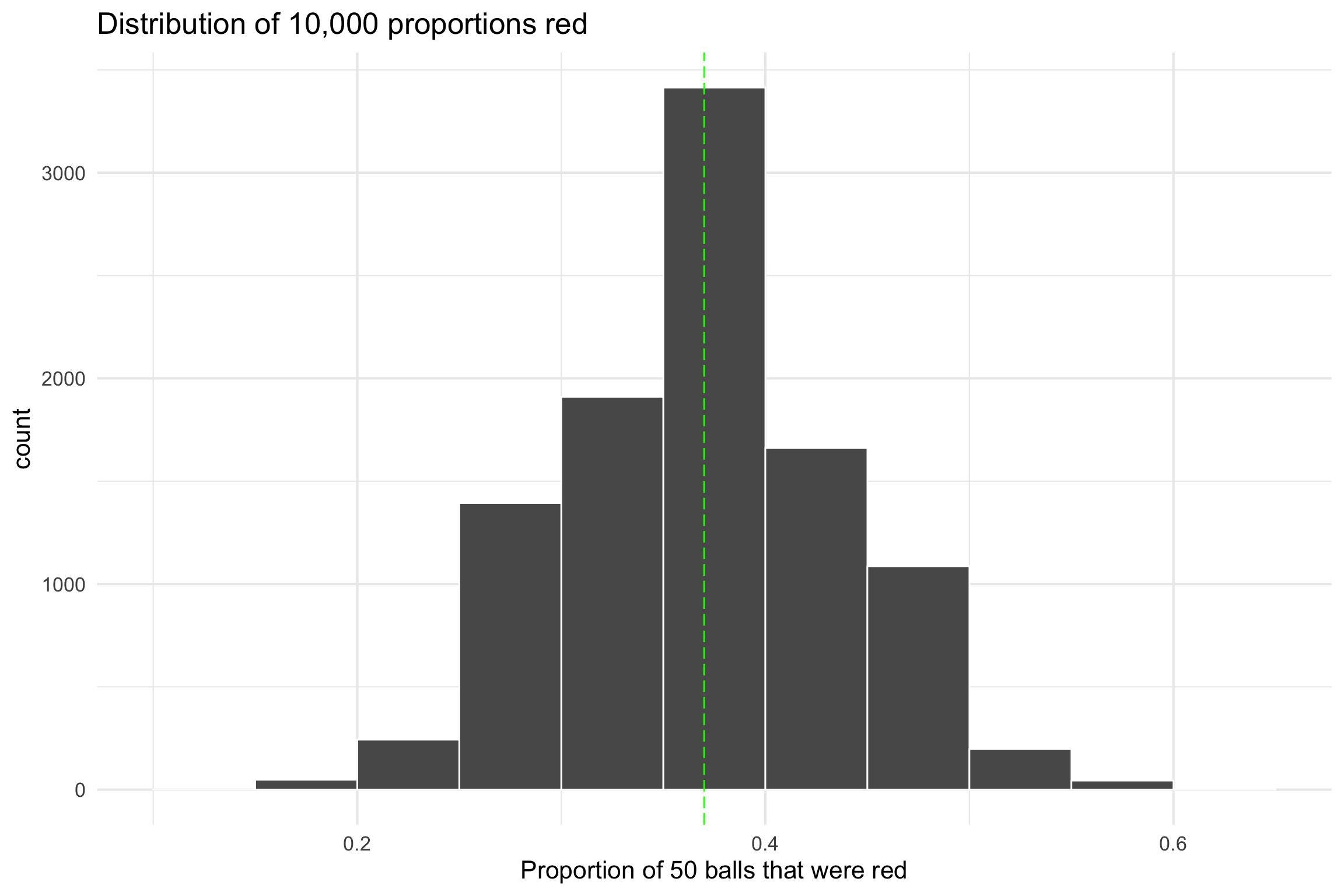
Example: Sampling Distribution of the Mean
- Scores on a statistics test
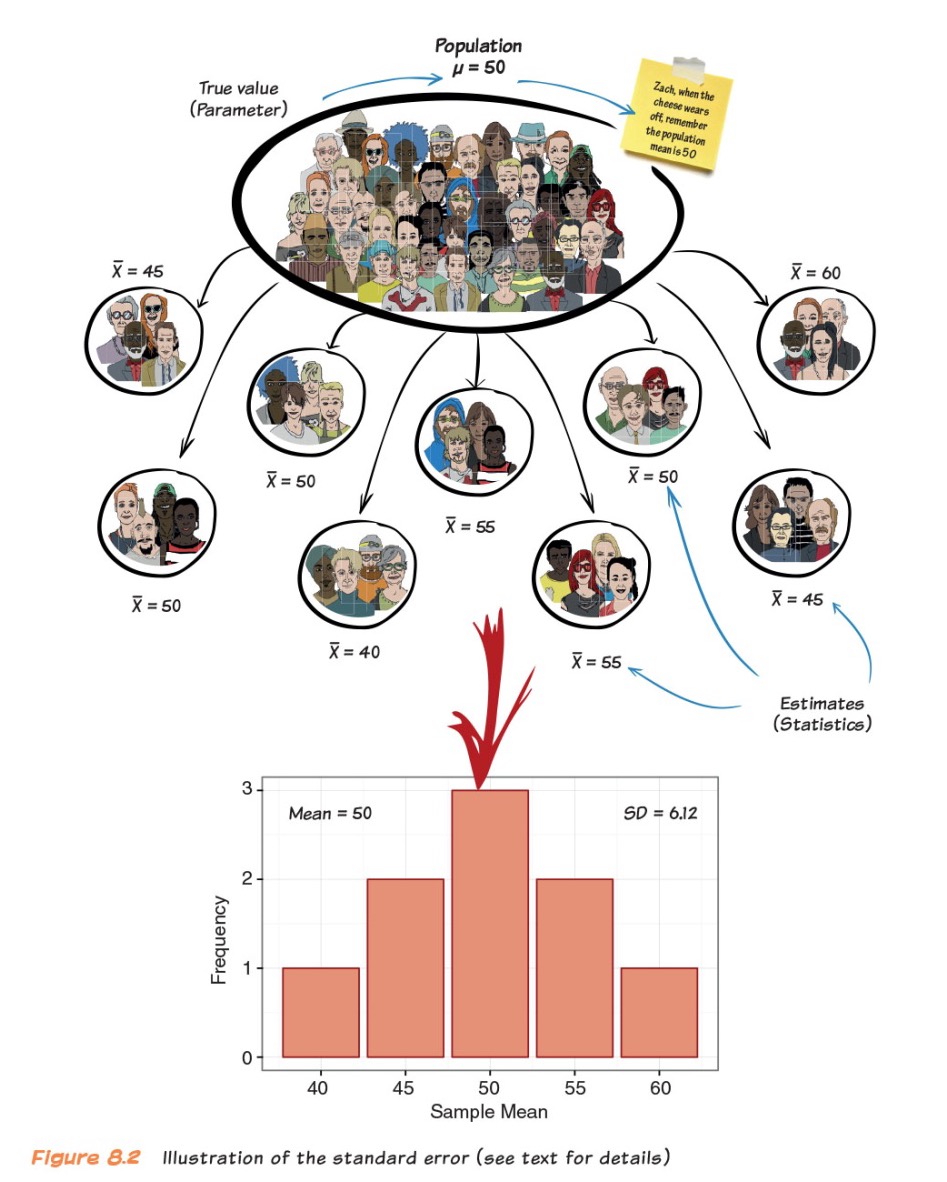
Taken from Andy Field’s “Adventures in Statistics”
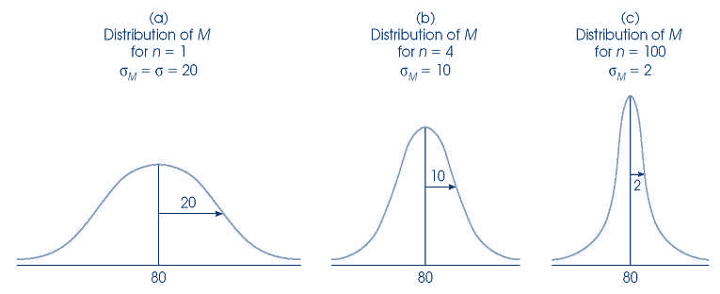
Sampling Error (Standard Error)
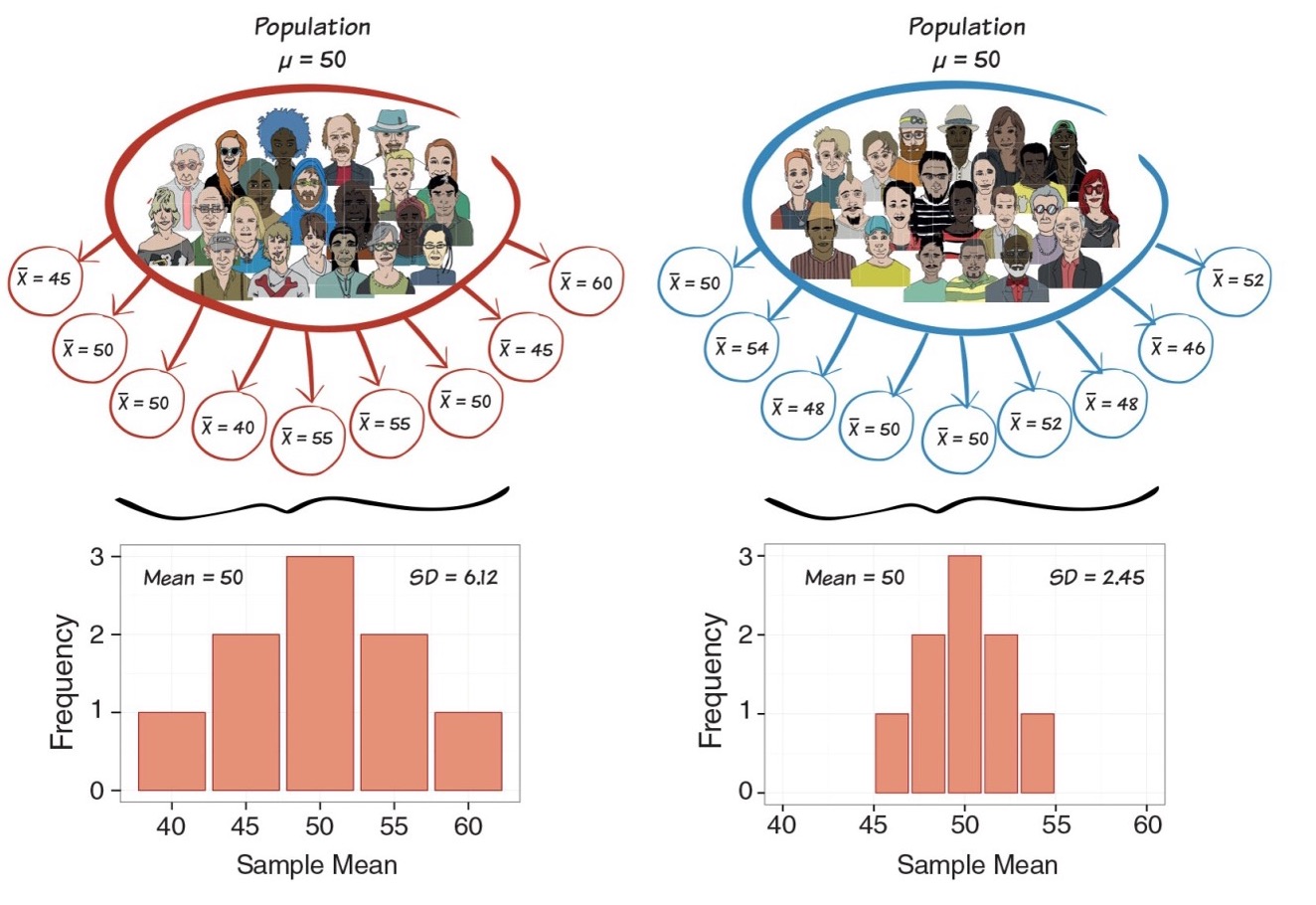
SEM
- What does smaller SEM tell us about our estimate?
- Estimate is likely to be closer to population mean
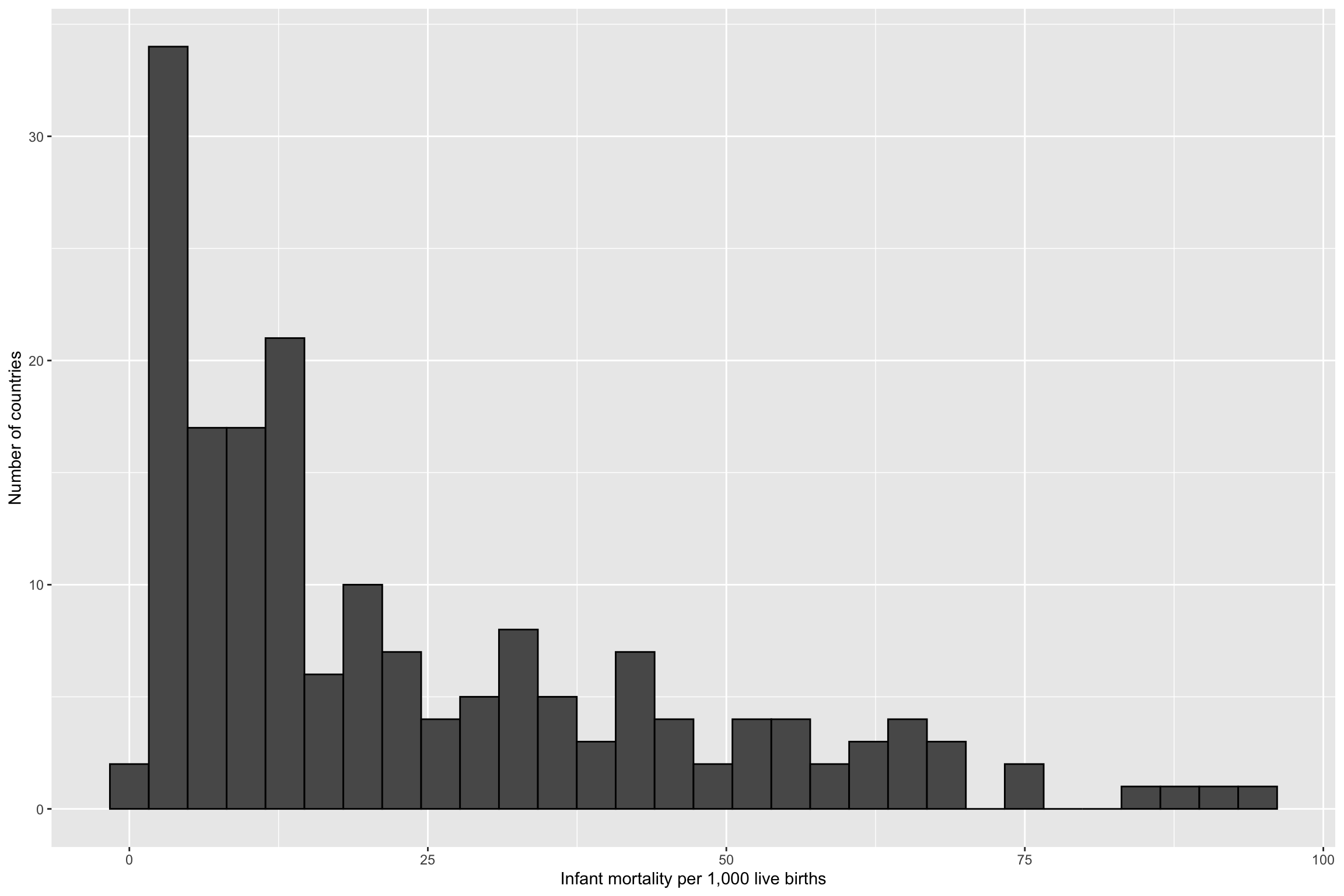
Real Data
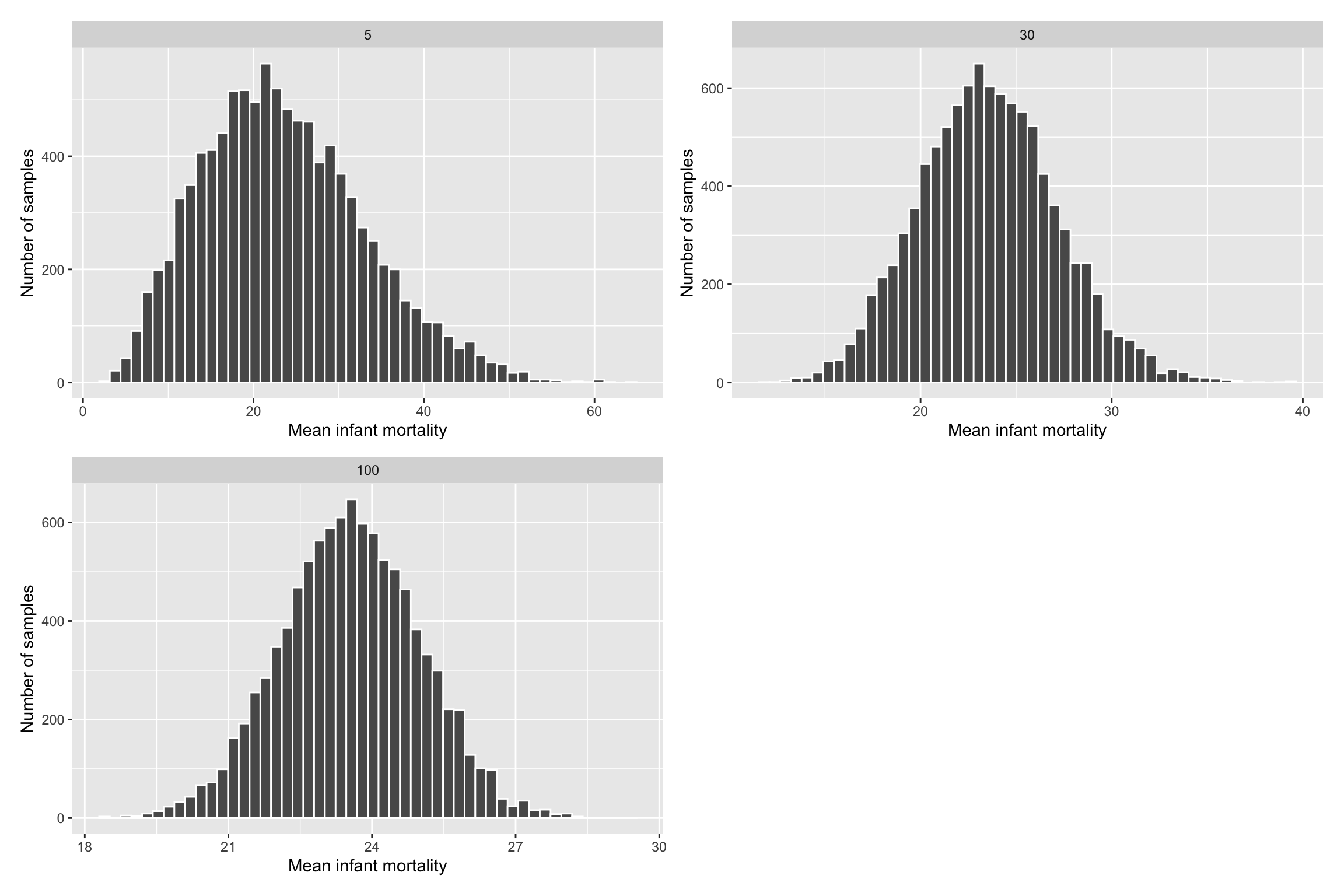
Larger N Equates Better Normal Approximation
Estimation Error and MOE
Combining Estimates Precision
CIs
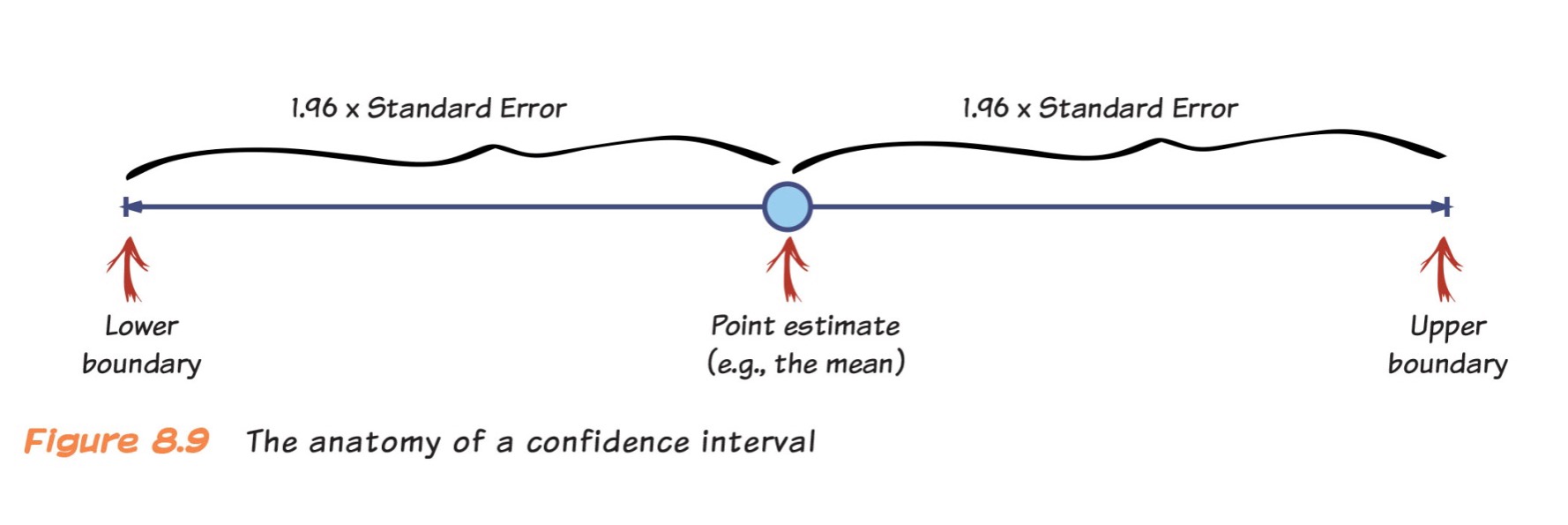
Range of values that are likely to include the true value of the parameter
Allows us to provide point estimate with precision (SE)
Anatomy of a Confidence Interval
Public support for Proposition A is 53%
- 53% support, 95% CI [51, 55]
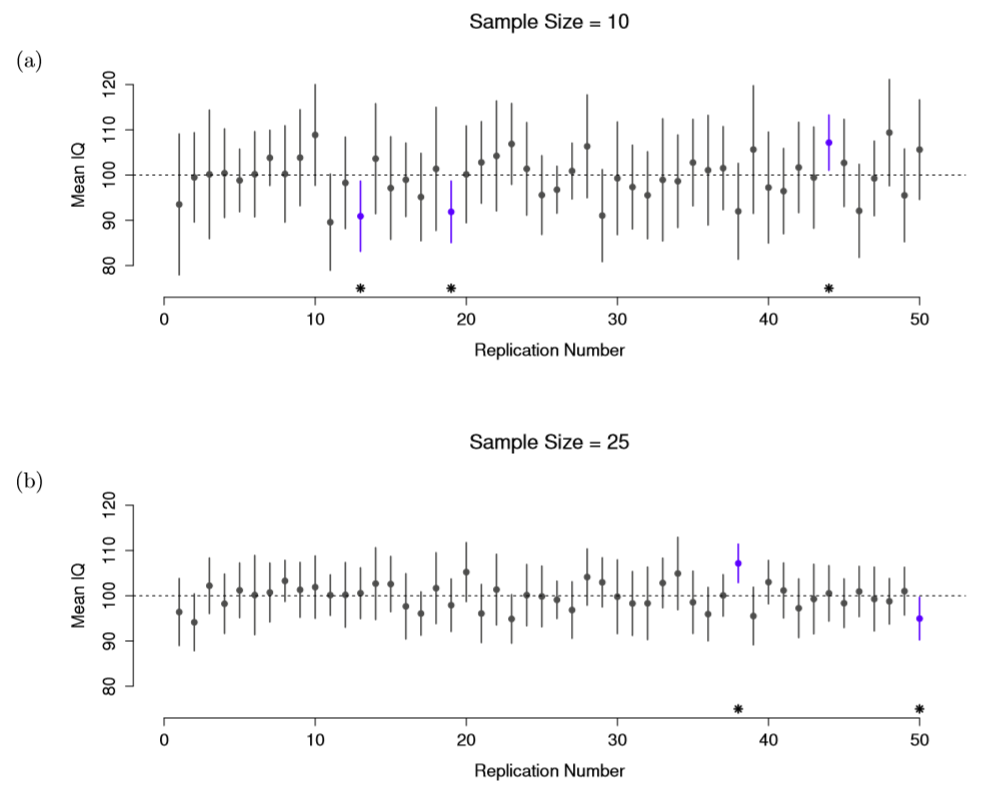
Andy Field’s ‘Adventures in Satistics’
CIs
- Sample size
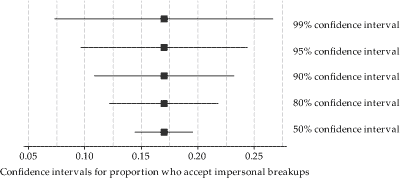
CIs
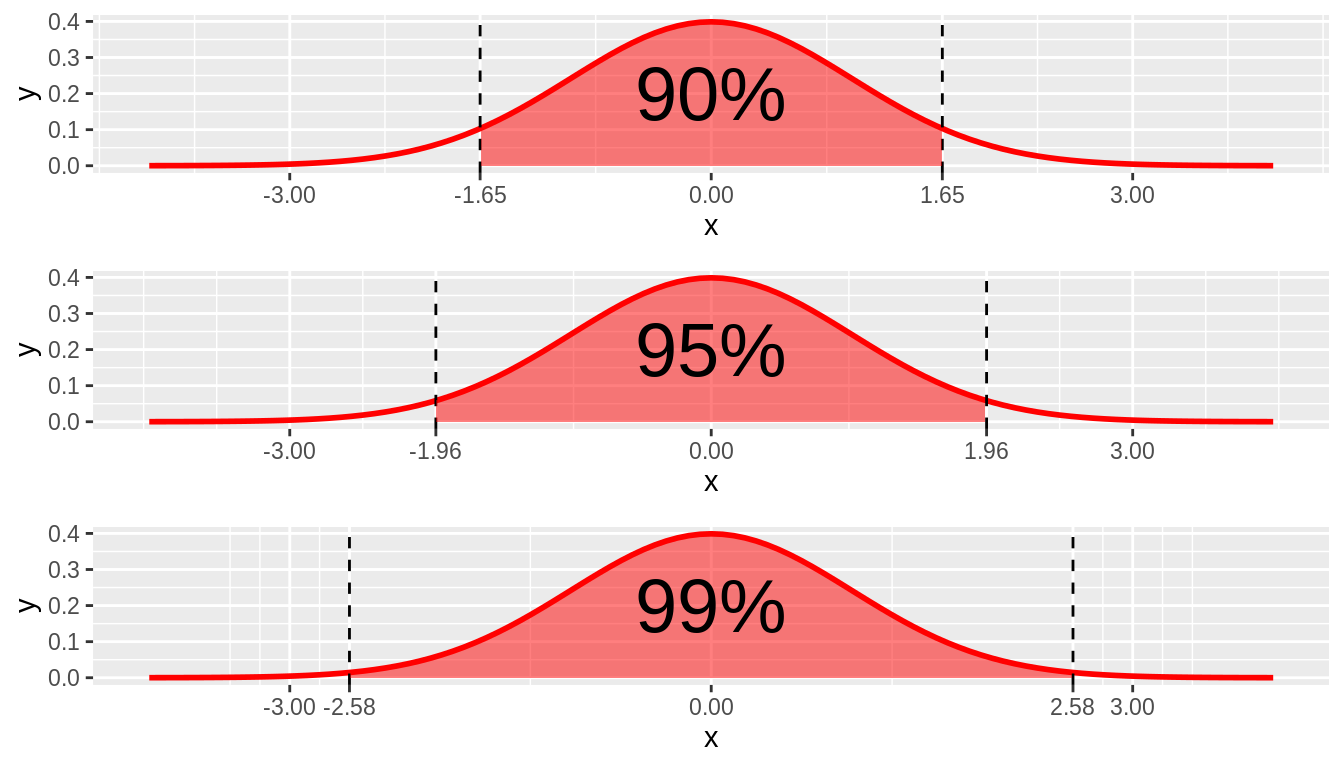
95 is referred to as confidence level
- i.e., How confident CI includes \(\mu\)
Does not only have to be 95!
- Greater C = longer CI
The \(t\) Distribution
Small samples: more conservative test
t-distribution has fatter tails
Coverage is more conservative
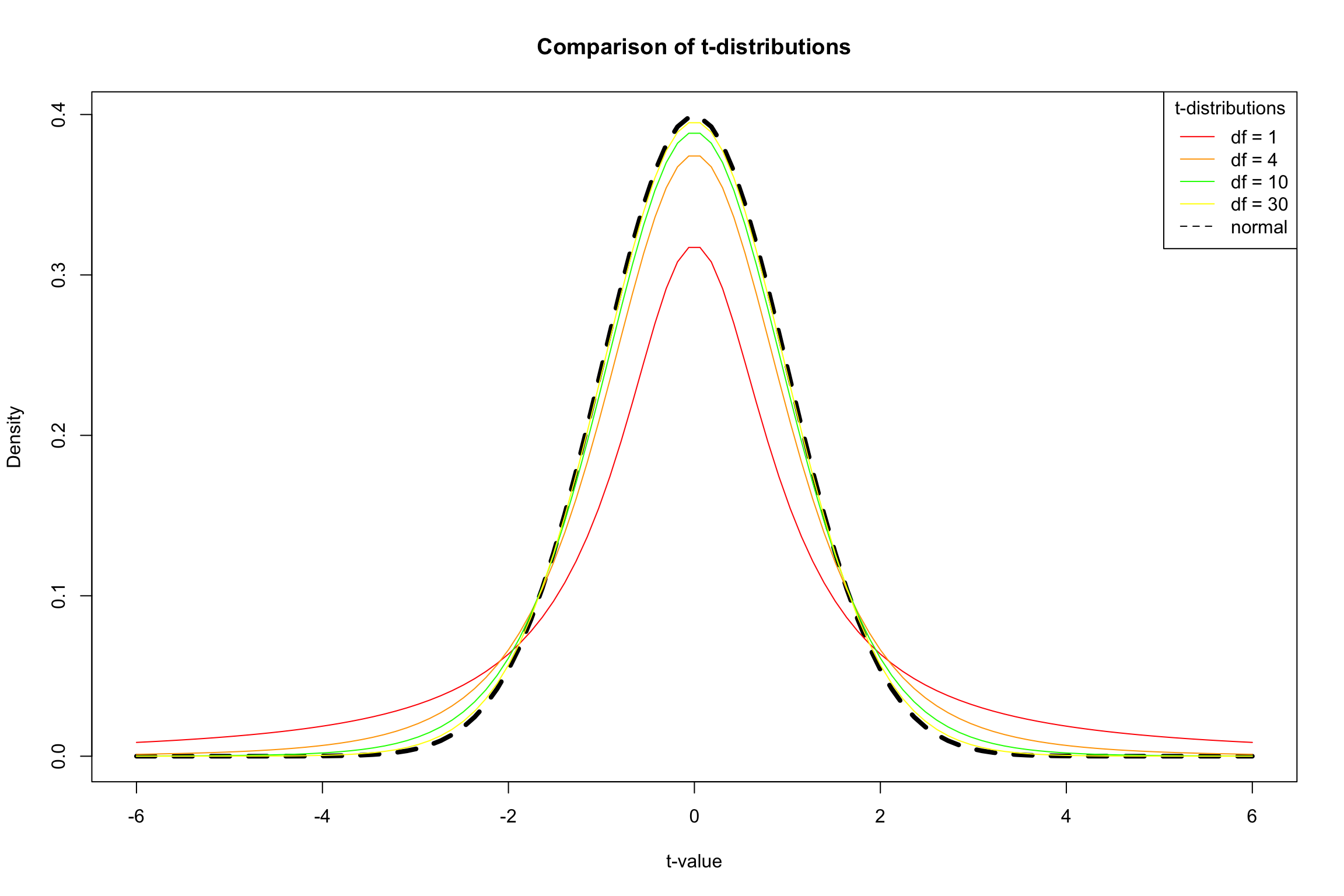
Degrees of Freedom
df = (N-1)
What is DF you ask?
- Number of separate independent pieces that can vary

Candy Experiment Revisited
- Let’s get the means for each condition
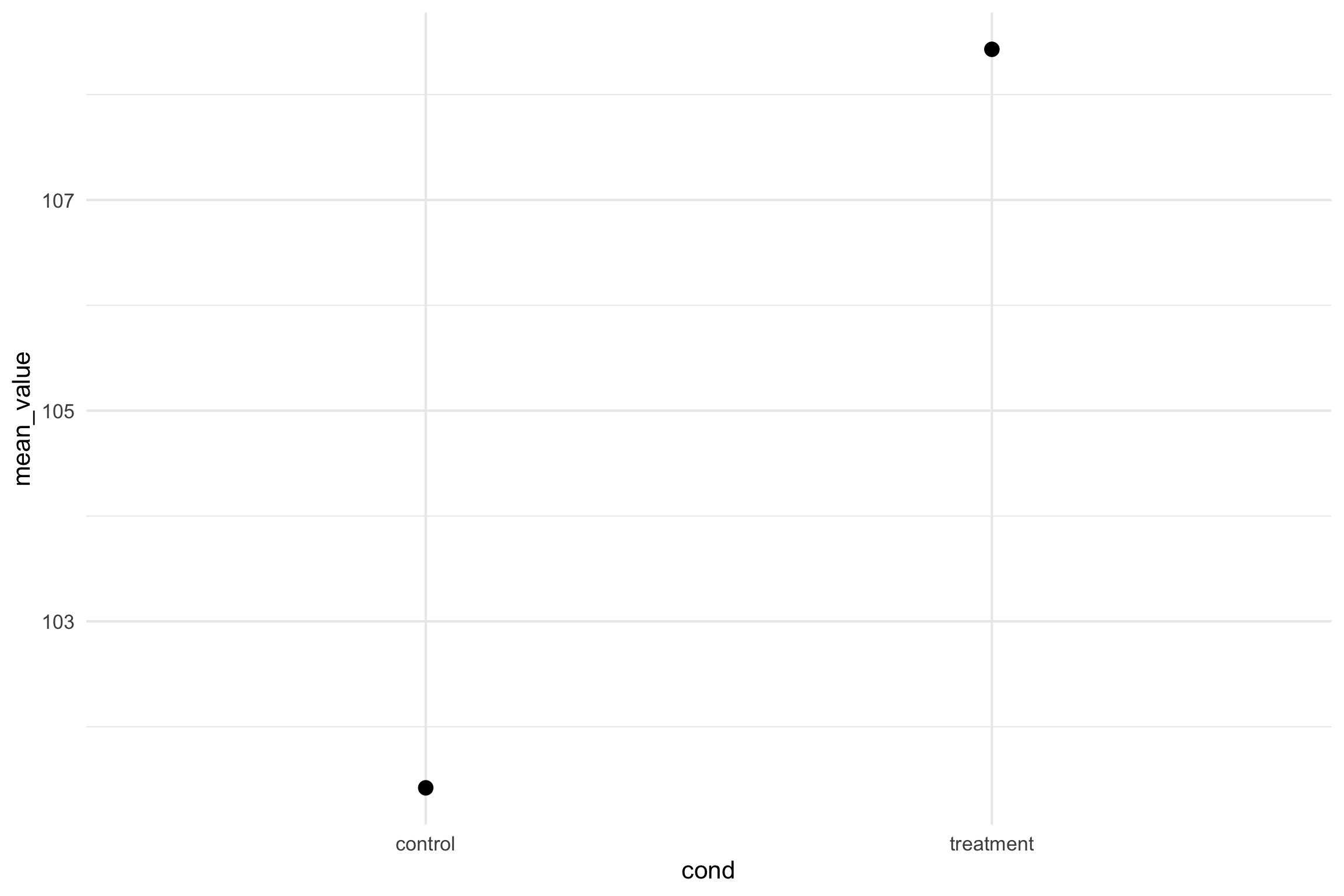
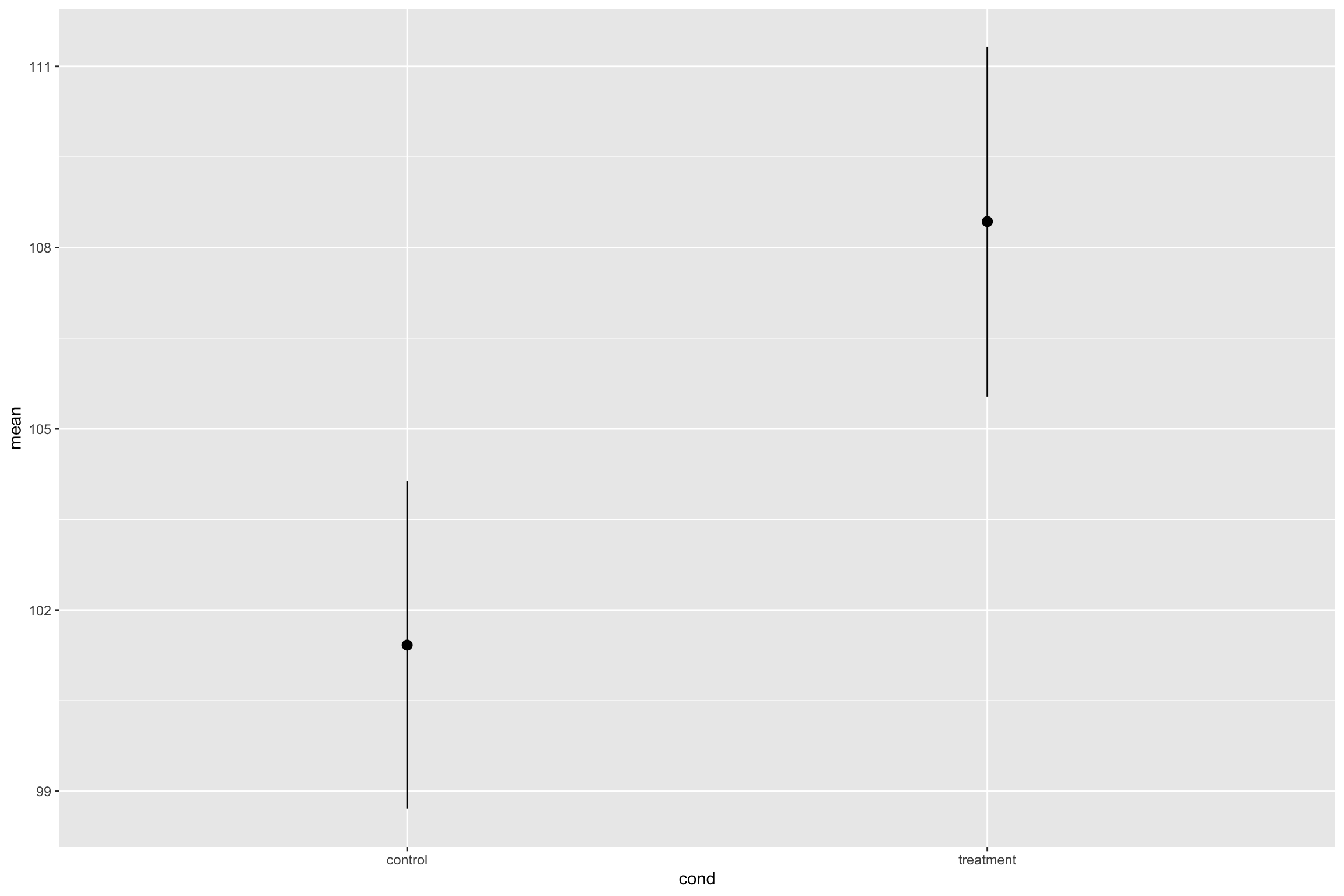
Candy Experiment Revisited
- Let’s plot our CIs
- Summary
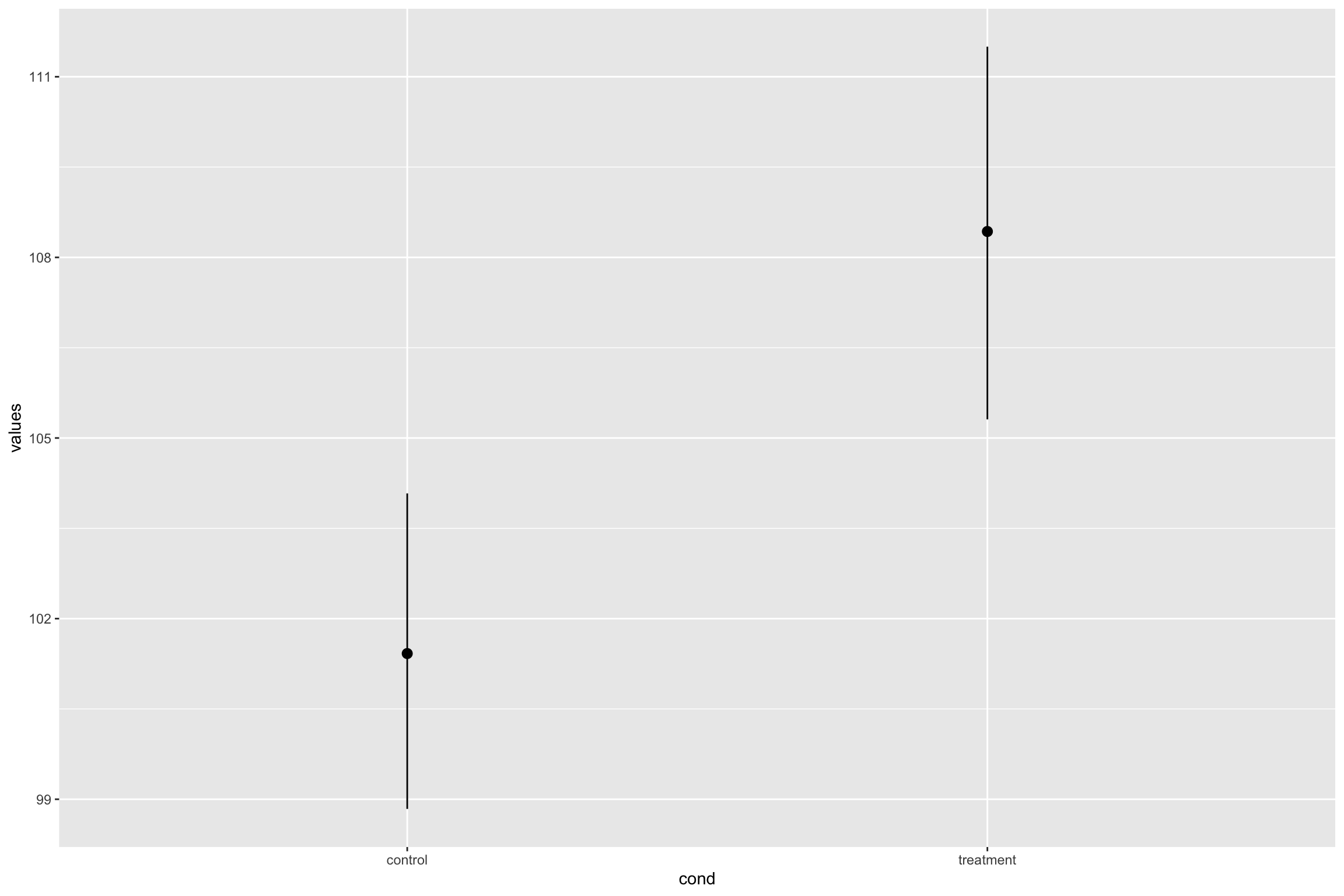
Candy Experiment Revisited
- CIs with Raw data
The New Statistics

Talk last year in PSY505