Package Version Citation
1 base 4.2.2 @base
2 cowplot 1.1.1 @cowplot
3 datawizard 0.8.0.4 @datawizard
4 easystats 0.6.0.8 @easystats
5 ggdist 3.2.0 @ggdist
6 knitr 1.41 @knitr2014; @knitr2015; @knitr2022
7 pacman 0.5.1 @pacman
8 rmarkdown 2.14 @rmarkdown2018; @rmarkdown2020; @rmarkdown2022
9 supernova 2.5.6 @supernova
10 tidyverse 1.3.2 @tidyverse
11 tigerstats 0.3.2 @tigerstatsMonsters, Models, and Normal Distributions
Princeton University
2023-10-02
What is a model?
Models are simplifications of things in the real world

What is a model?
Distributions
Models as Monsters
- The Golem of Prague
- The golem was a powerful clay robot
- Brought to life by writing emet (“truth”) on its forehead
- Obeyed commands literally
- Powerful, but no wisdom
- In some versions, Rabbi Judah Loew ben Bezalel built a golem to protect
- But he lost control, causing innocent deaths

Choosing a Statistical Model
- Cookbook approach
- Do Smarties make us smarter?
- Take 200 7-year-olds
- Randomly assign to 2 groups
- Control: Normal breakfast
- Treatment: Normal breakfast + 1 packet of Smarties
- Outcome: Age-appropriate general reasoning test
- Randomly assign to 2 groups
- Take 200 7-year-olds
- Do Smarties make us smarter?
Choosing a Statistical Model
Cookbook approach
Every one of these tests is the same model
The general linear model (GLM)
- The cookbook approach makes it hard to think clearly about relationship between our question and the statistics
Building a Model - Notation
Greek letters
Population parameters
Unobservable parameters
μ
mu
- “mew” - Used to describe means
σ
Sigma
Used to describe a standard deviation

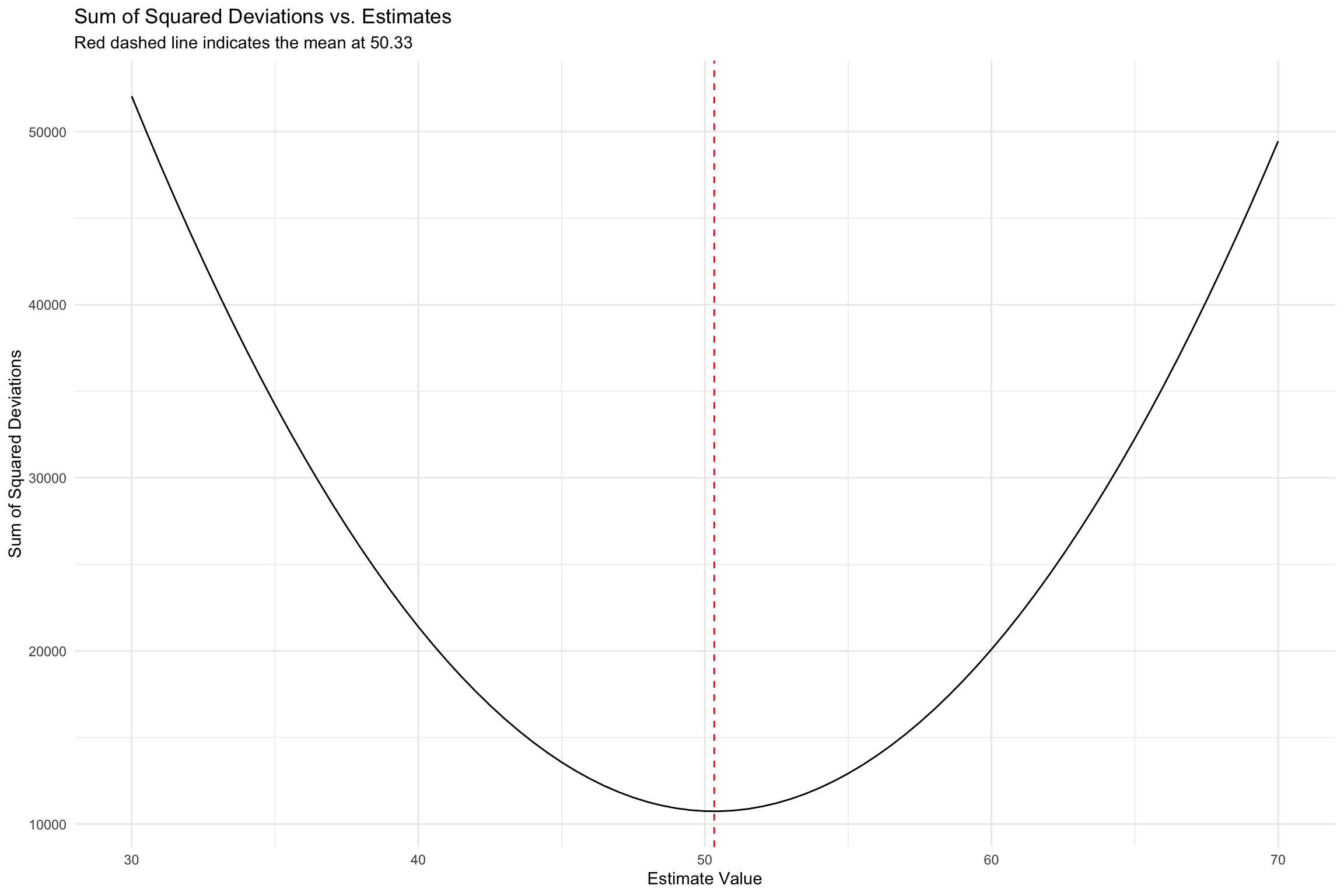
Figuring out \(b_0\)
- Goal of any model is to find an estimator that minimizes the error
- How we define error will determine the best estimator
SSR minimized at mean
Statistical Modeling: A Concrete Example
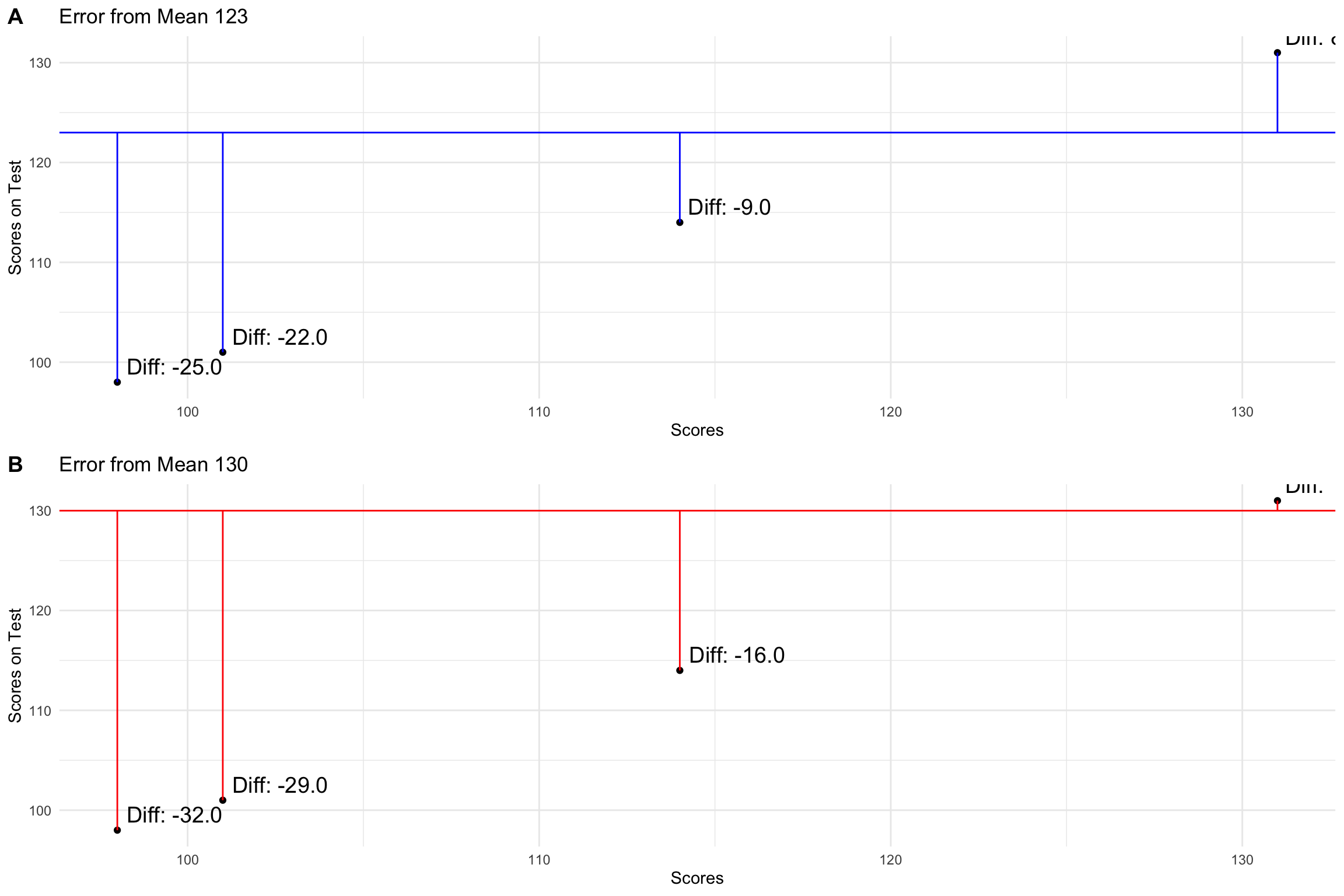
- Let’s look at general reasoning scores
Building a model - Concrete Example

Building a model - Concrete example
- Predictions from the model
A More Complex Model
- Do you think the empty model is a good model?
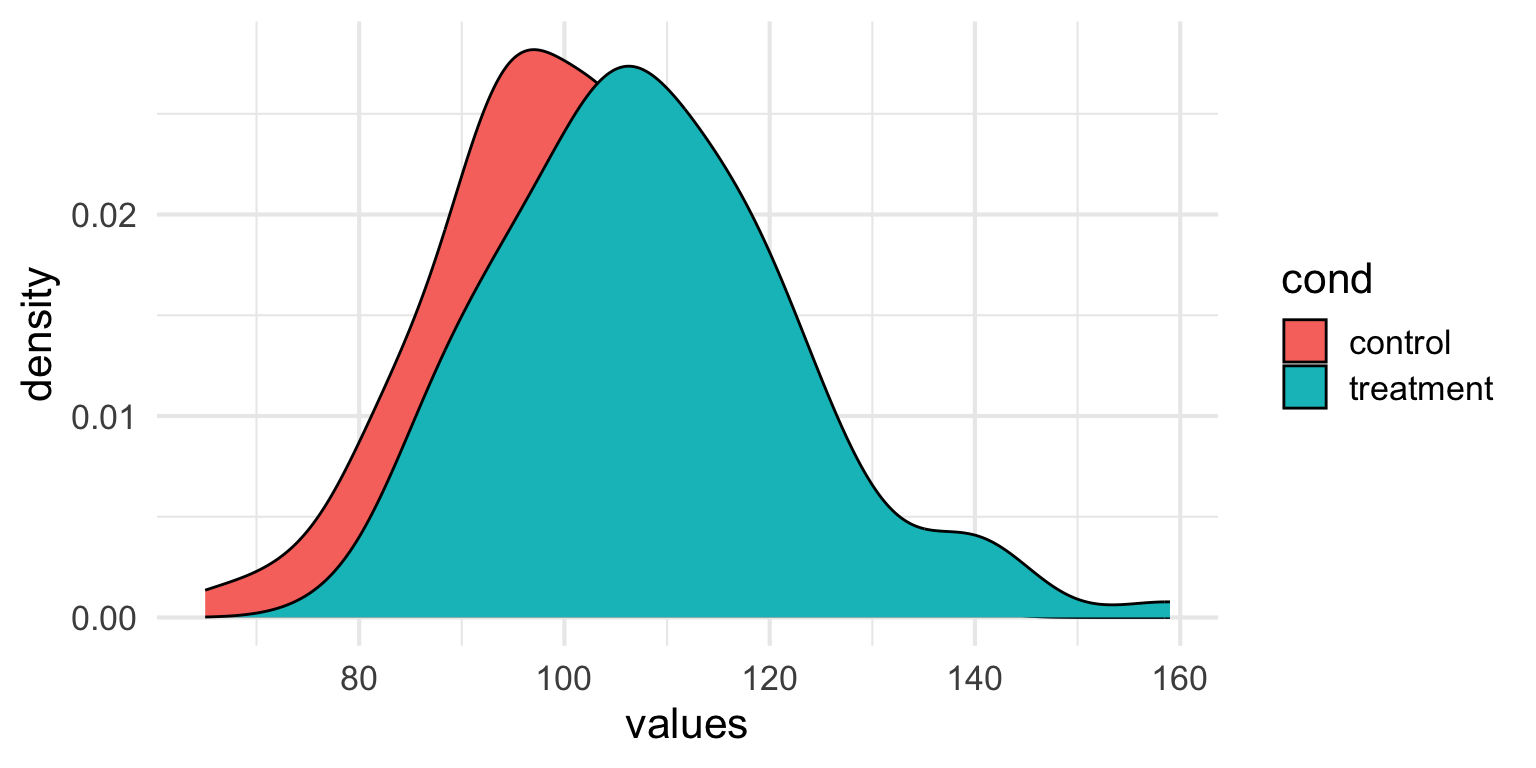
What Makes a Model “Good”
We want it to describe our data well
We want it to generalize to new datasets
- We want error to be as small as possible
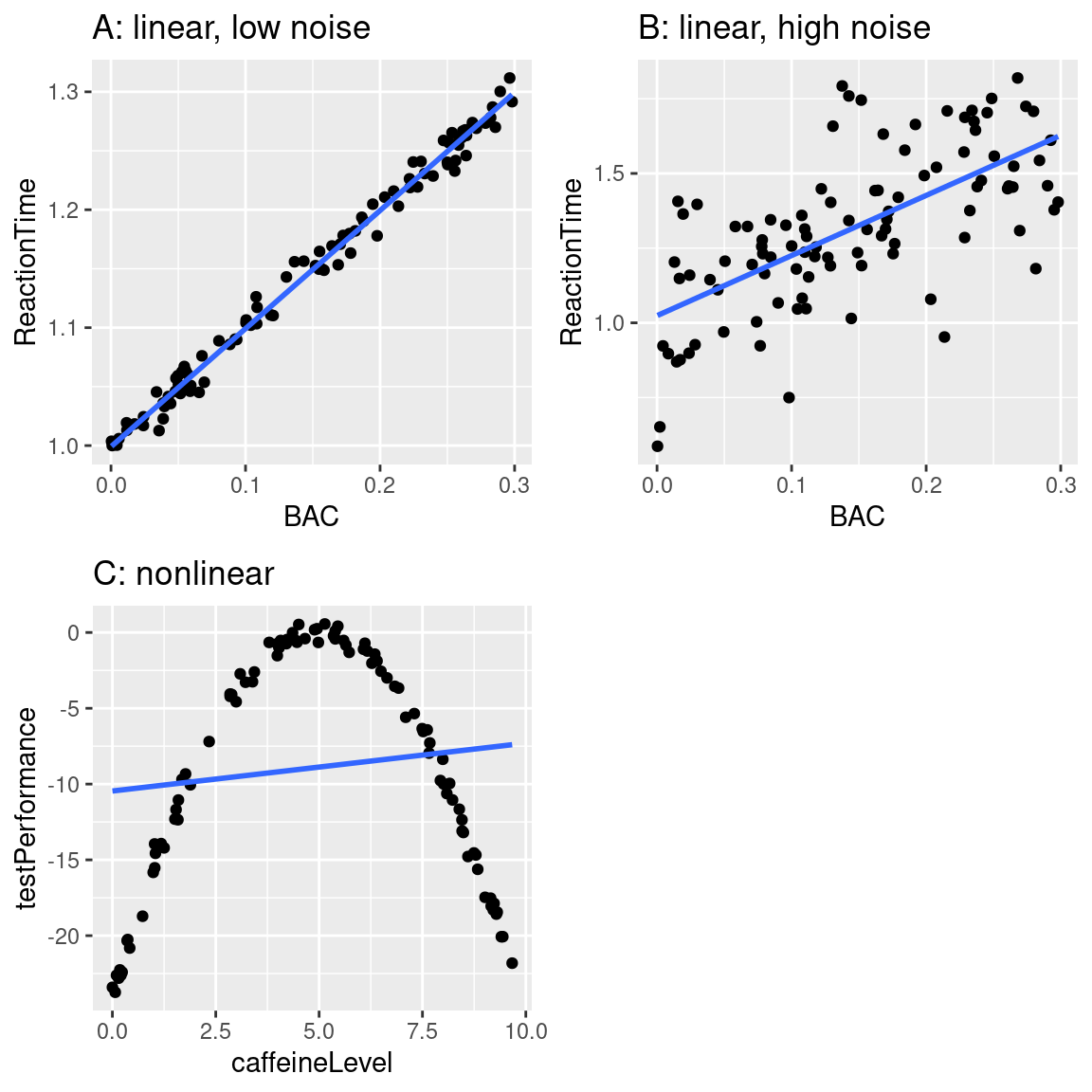
Can a Model Be Too Good?
Yes!
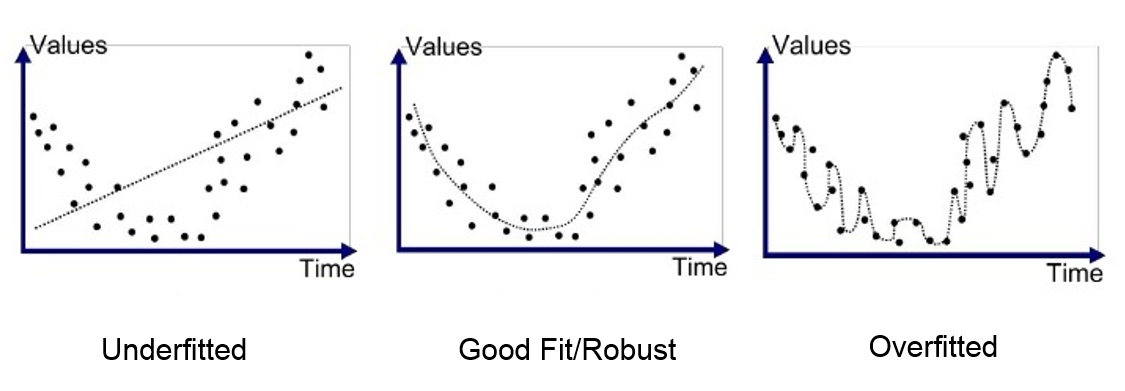
Overfitting
- A model with little to no error will not generalize to new datasets
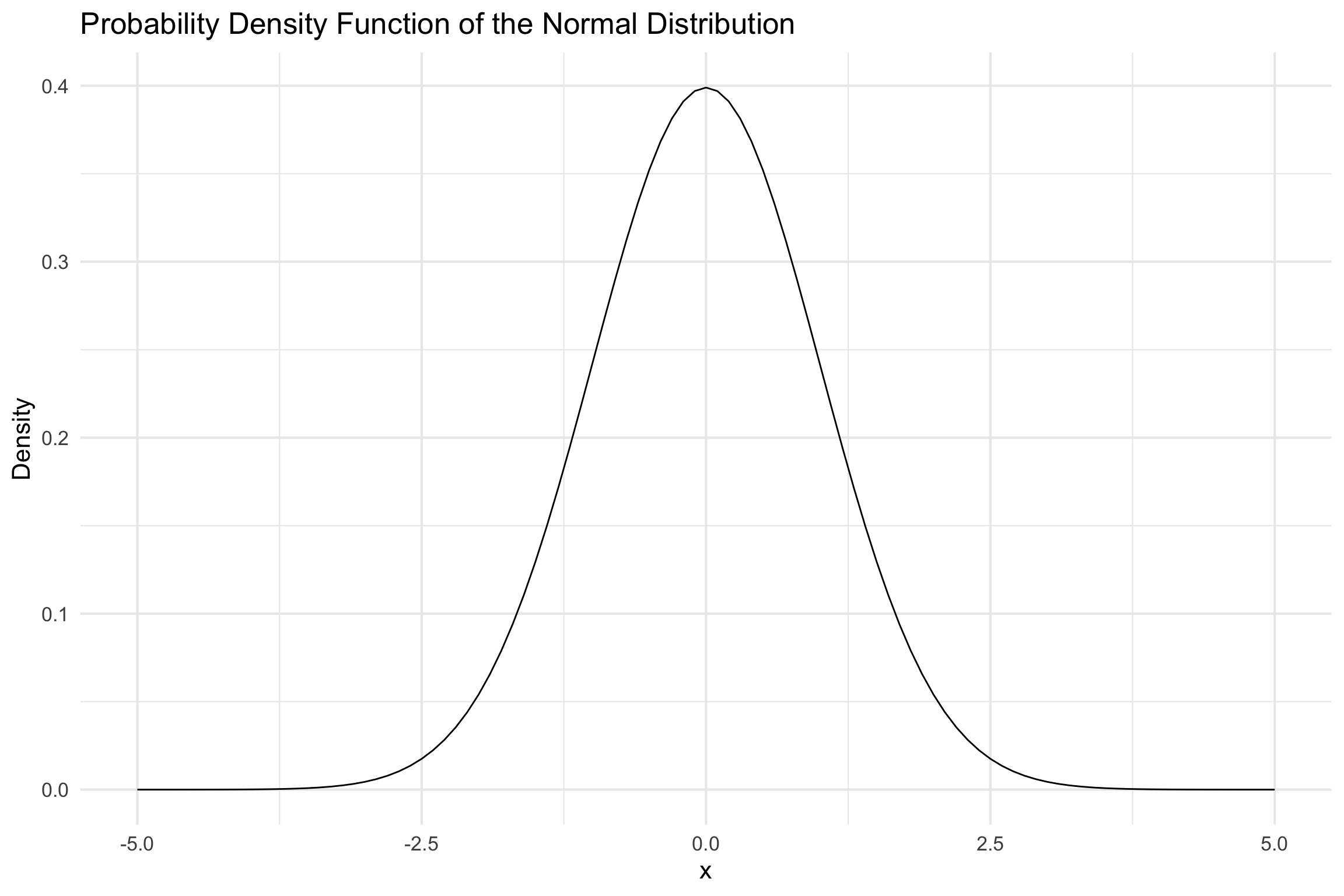
Normal distribution
- Sometimes called a Gaussian distribution
- If we assume a variable is at least normally distributed can make many inferences!
- Most of the statistical models assume normal distribution
- Error in linear models is assumed to distributed as normal
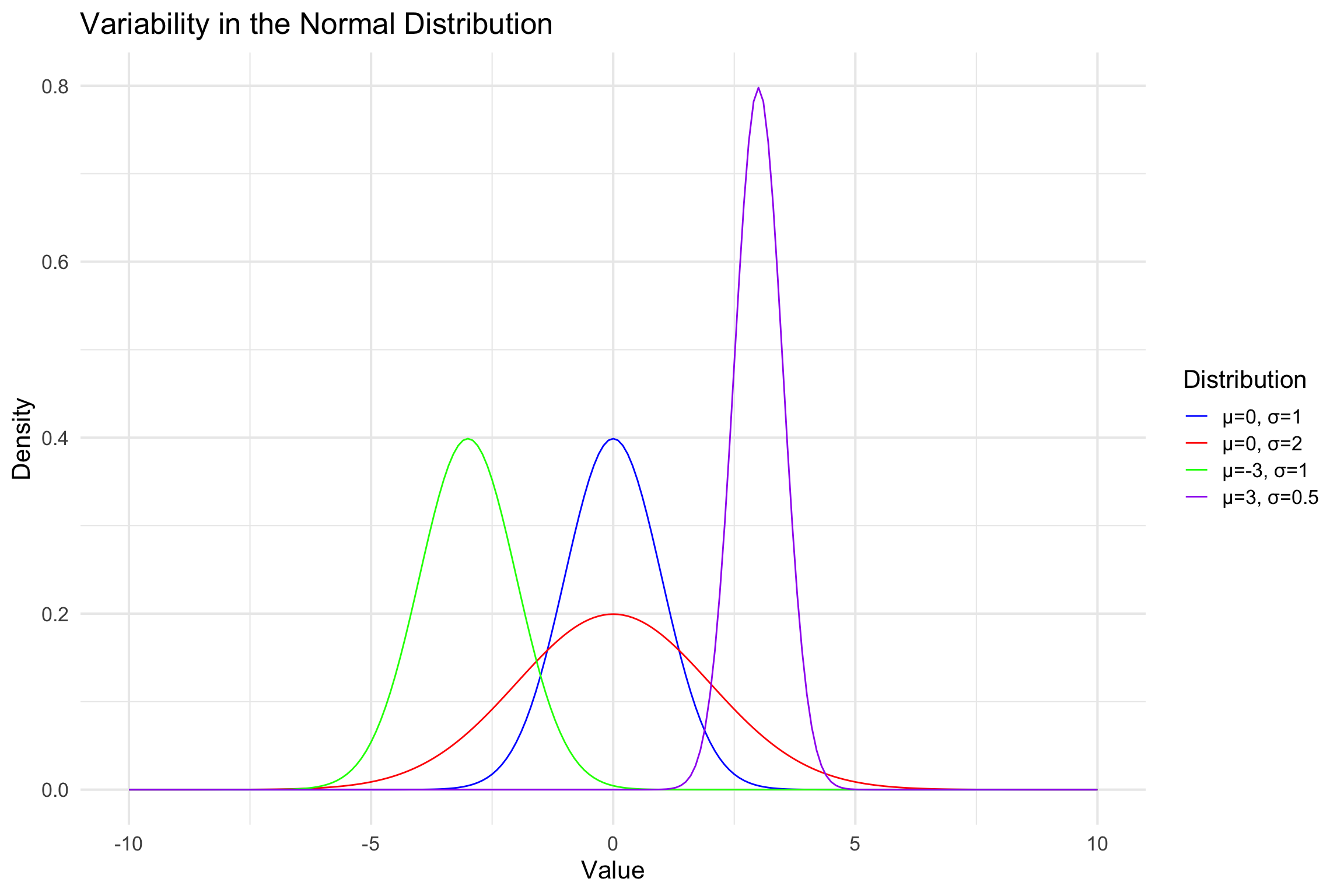
Normal distribution
Normal(μ, σ)
Parameters:
\(\mu\) = Mean
\(\sigma\) Standard deviation
- On average, how far is each point from the mean (spread)?
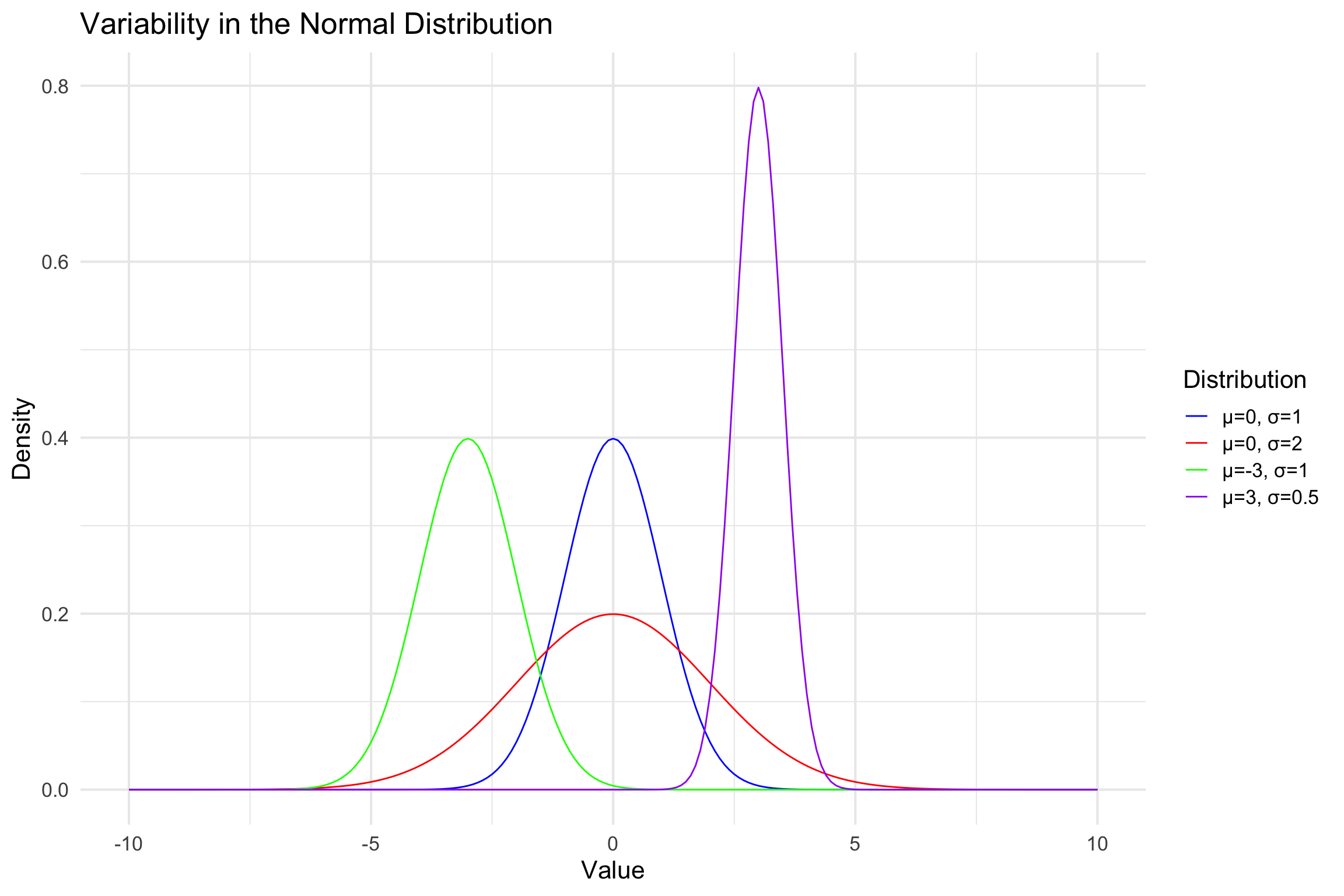
Building a Model - Normal Distribution
Properties of a normal distribution
- Shape
- Unimodal
- Symmetric
- Asymptotic
- Shape
Building a Model - Normal Distribution
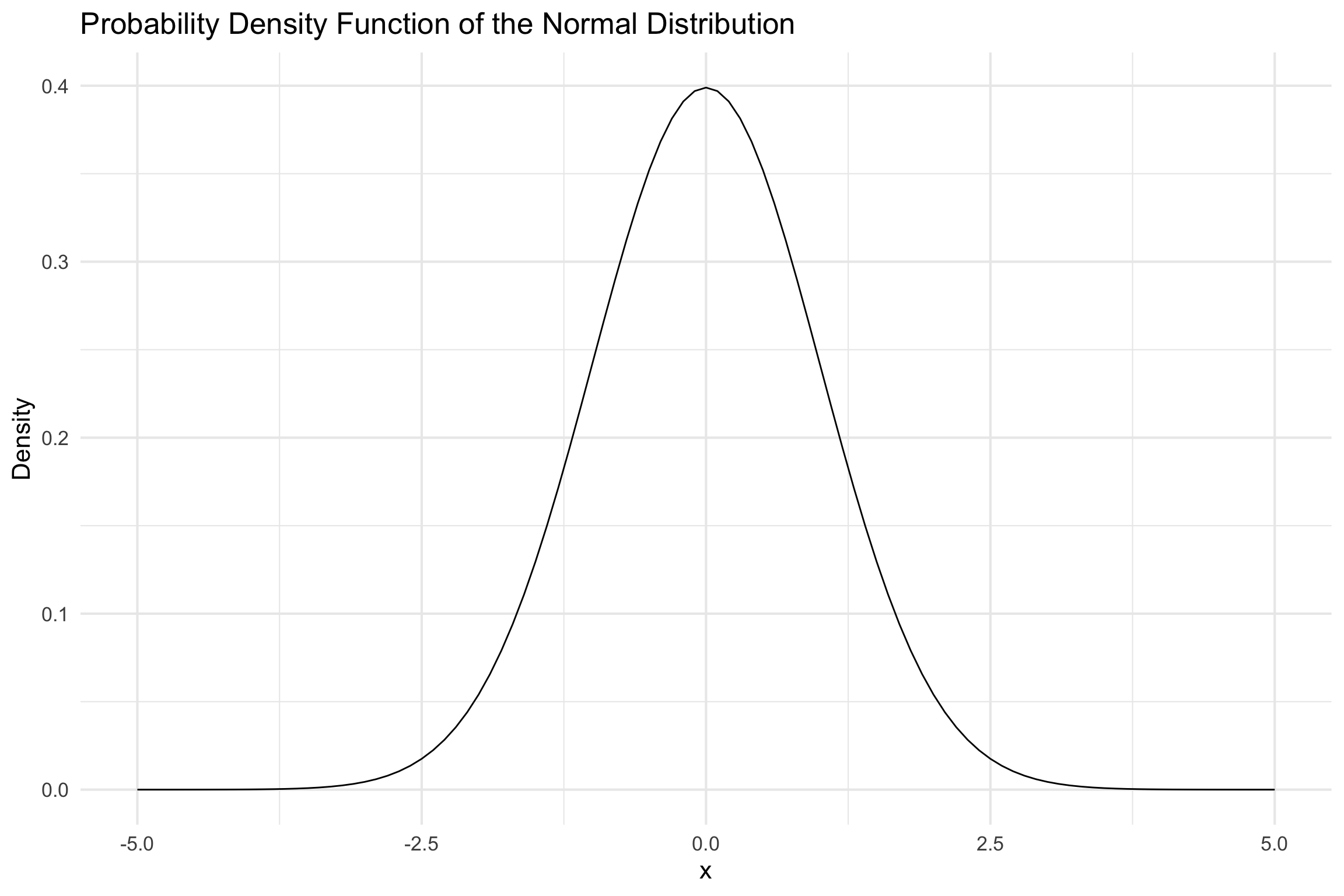
- The PDF of a normal distribution is given by:
\(f(x) = \frac{1}{\sqrt{2\pi \sigma}}\exp\left[-\frac{(x-\mu)^2}{2\sigma^2}\right]\)
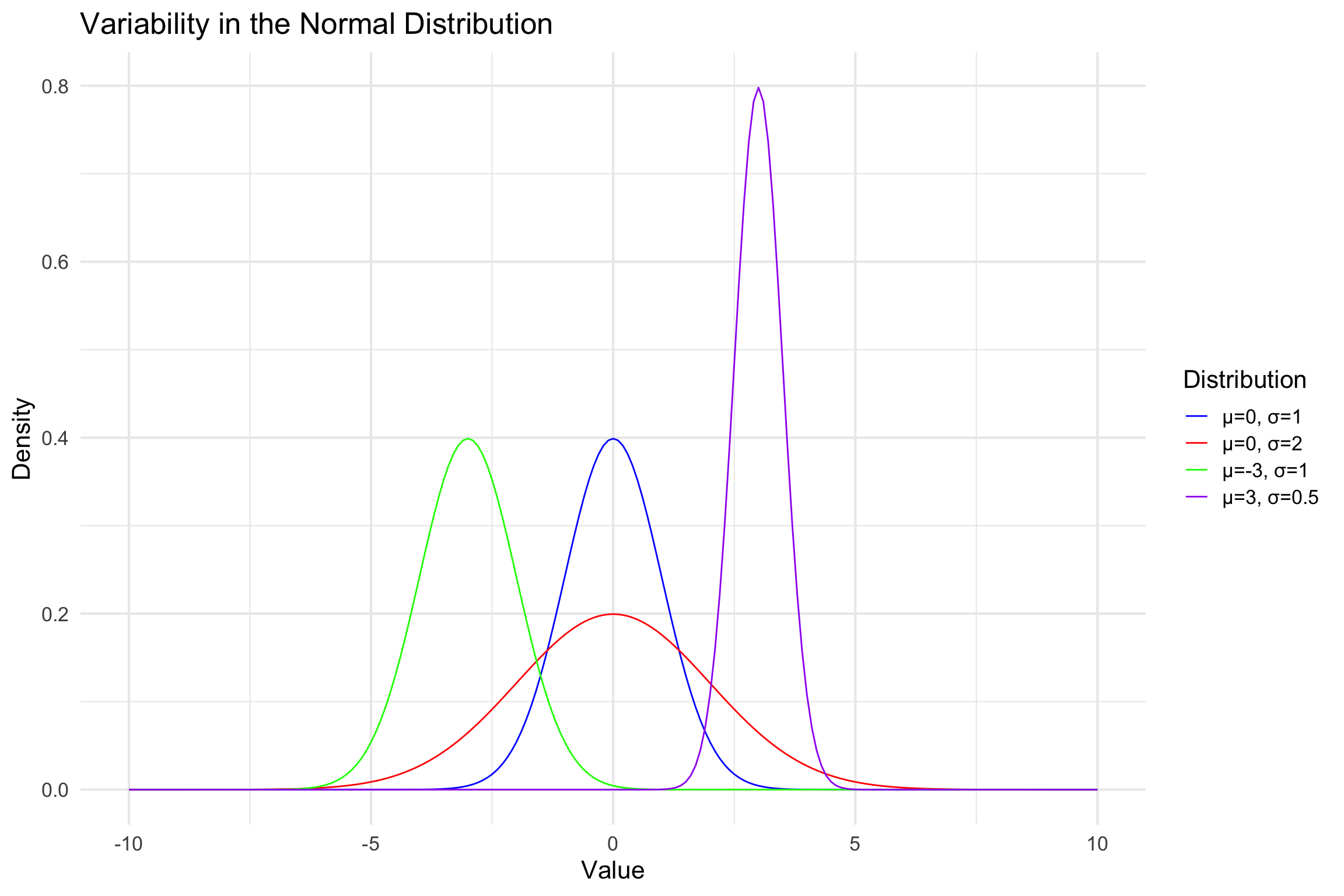
Normal Distribution
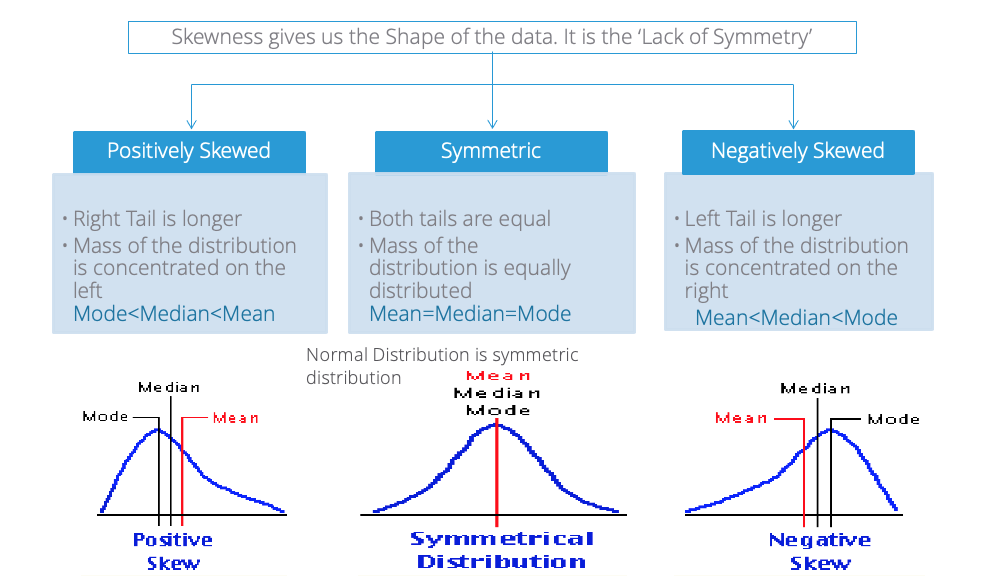
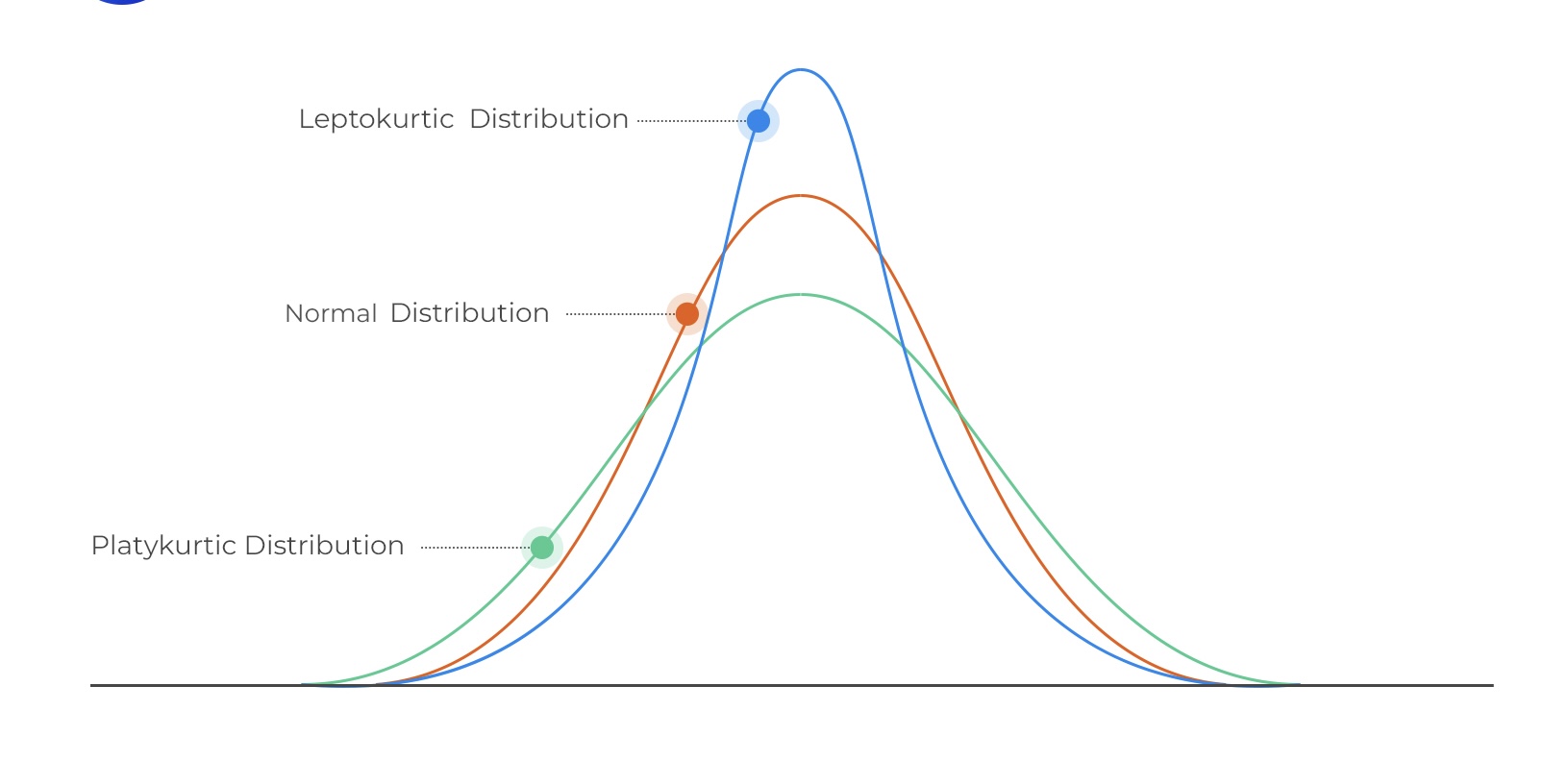
- Skew
Normal Distribution
- Peakedness
Probability and Standard Normal Distribution: Z-Scores
\[Z(x) = \frac{x - \mu}{\sigma}\]
- Z-score /standard score tells us how far away any data point is from the mean, in units of standard deviation
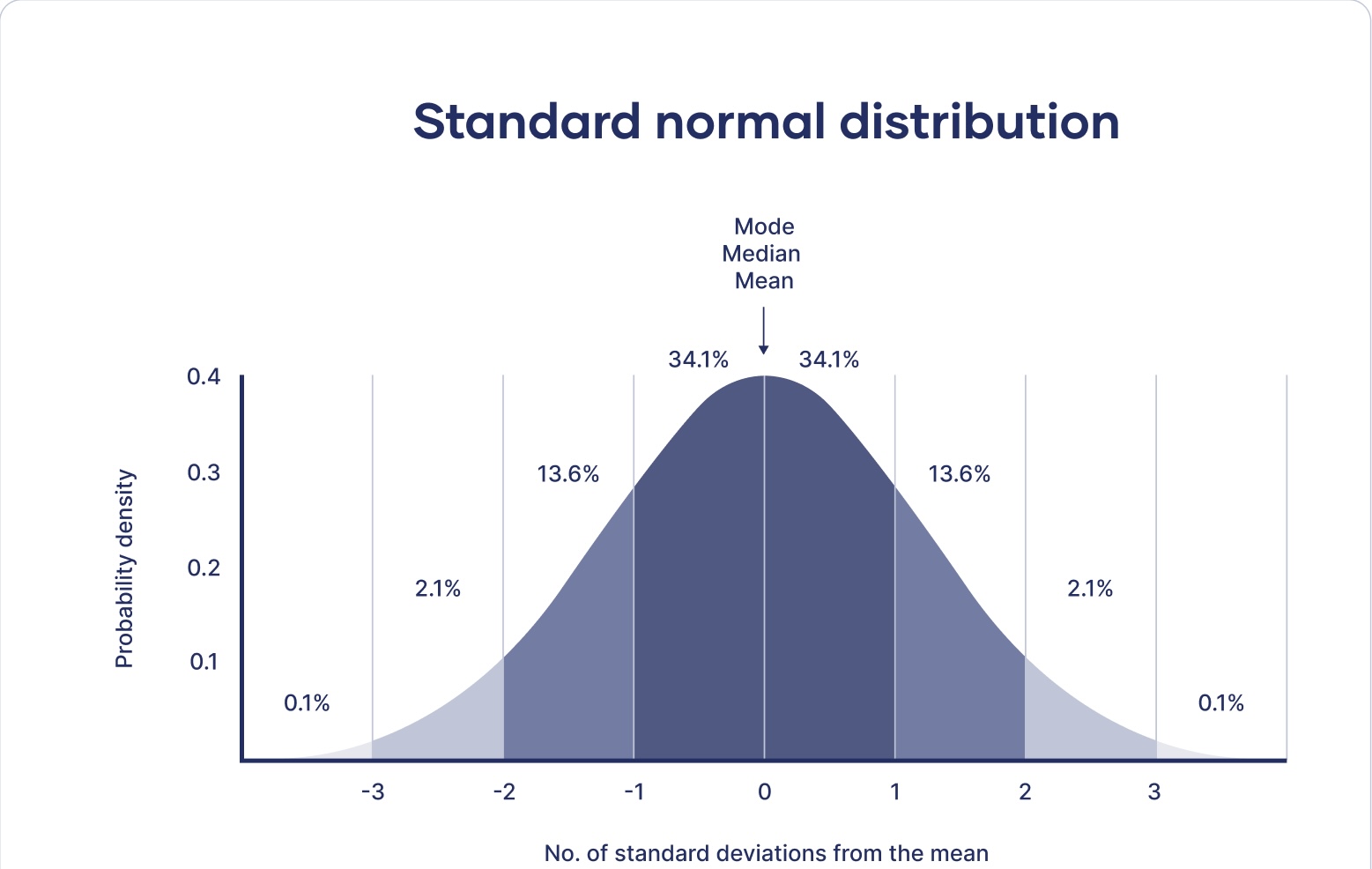
Standard Normal Distribution
- Properties of standard normal
- Empirical Rule
- 68.27% of the data falls within one standard deviation (sigma) of the mean
- 95.45% falls within two sigma
- 99.73% falls within three sigma
- Empirical Rule
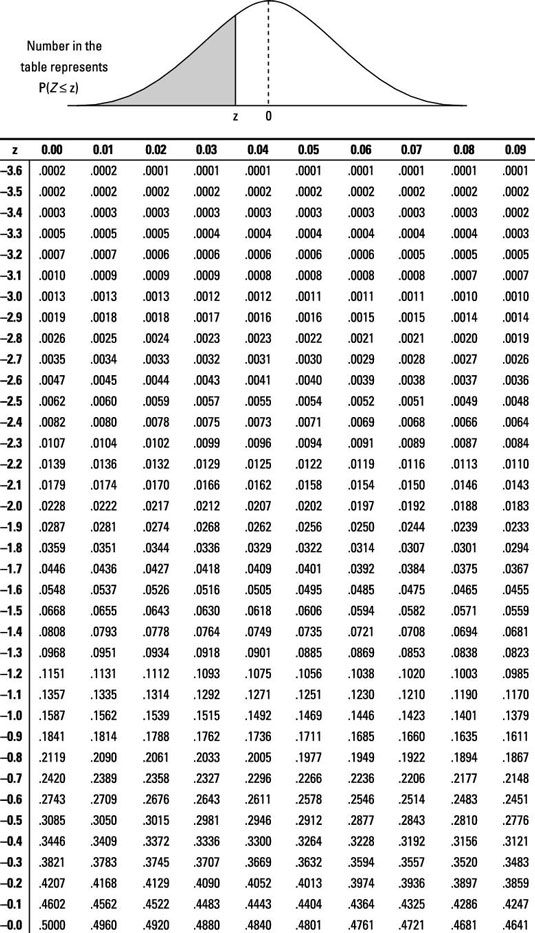
Z tables
- NO MORE TABLES
Package PnormGC
- Percentage between IQ score of 120 and 159?
[1] 0.09116933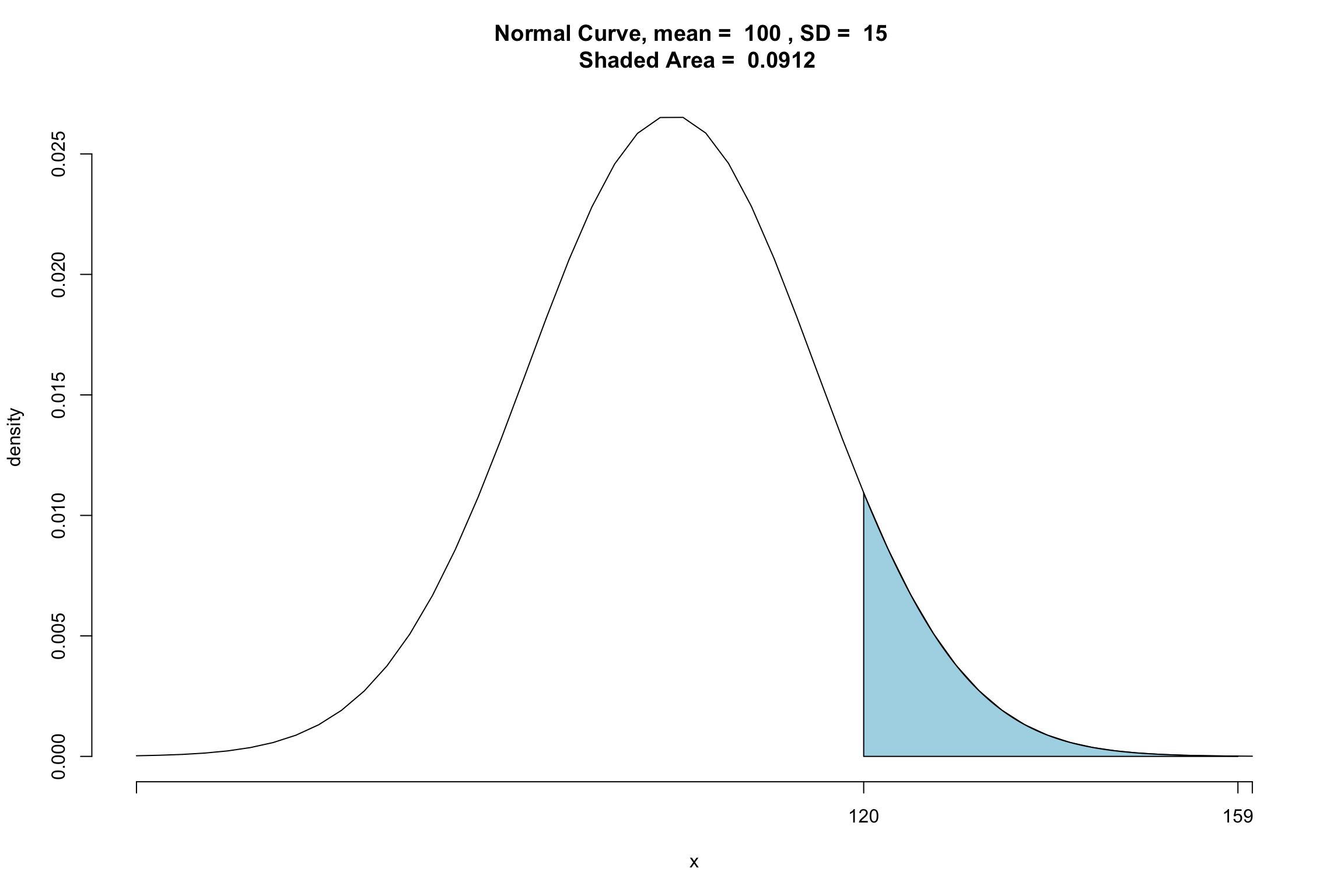
Package PnormGC
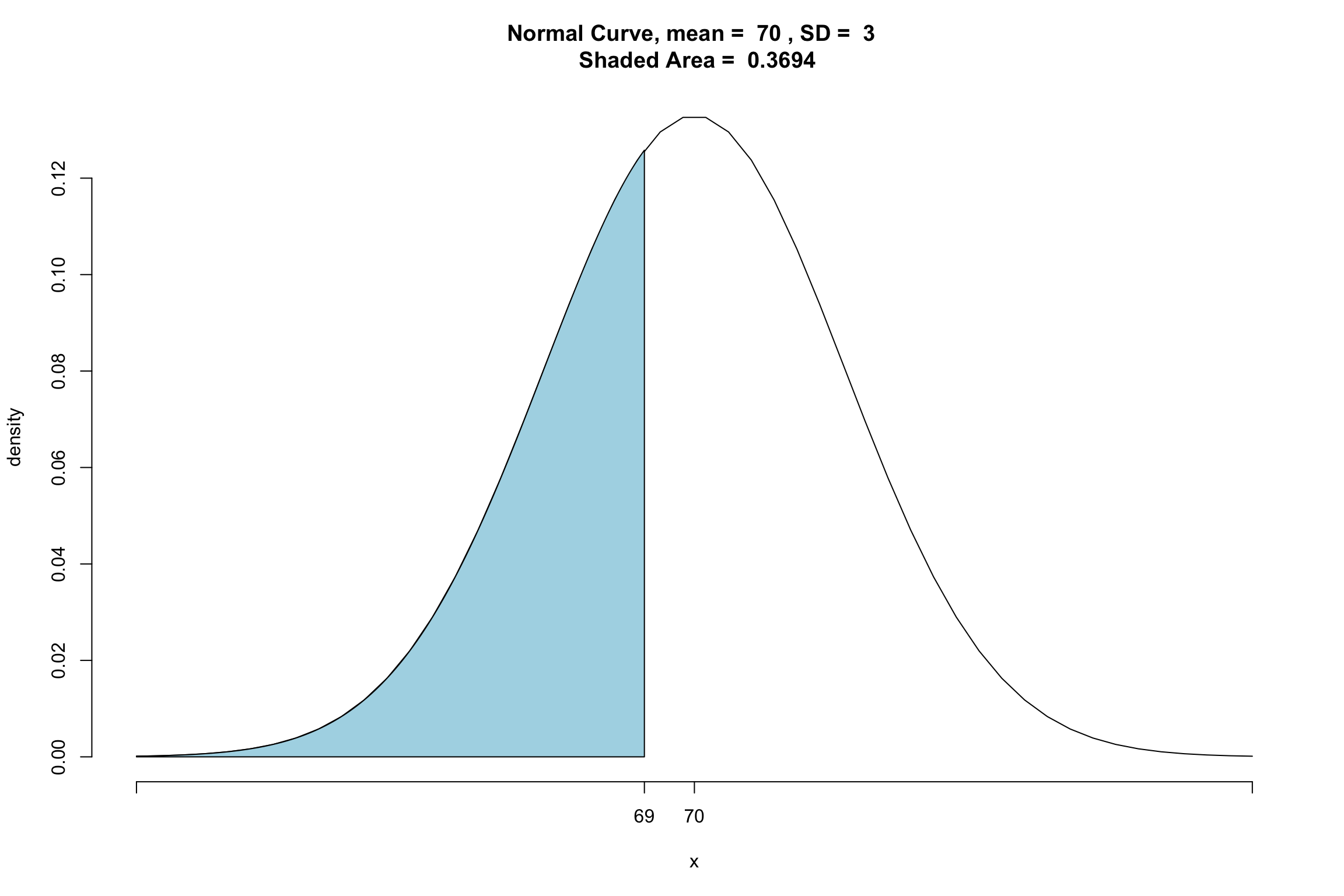
What about \(P(X \leq 69)\)