Package Version
1 base 4.2.2
2 colorspace 2.1.0
3 cowplot 1.1.1
4 fivethirtyeight 0.6.2
5 gapminder 1.0.0
6 ggdist 3.2.0
7 gghalves 0.1.4
8 ggrain 0.0.3
9 ggridges 0.5.3
10 ggstatsplot 0.9.4
11 MetBrewer 0.2.0
12 openintro 2.4.0
13 pacman 0.5.1
14 palmerpenguins 0.1.1
15 patchwork 1.1.2
16 rmarkdown 2.14
17 scales 1.2.1
18 ThemePark 0.0.0.9000
19 tidyverse 1.3.2
Citation
1 @base
2 @colorspace2009b; @colorspace2009c; @colorspace2020a
3 @cowplot
4 @fivethirtyeight
5 @gapminder
6 @ggdist
7 @gghalves
8 @ggrain
9 @ggridges
10 @ggstatsplot
11 @MetBrewer
12 @openintro
13 @pacman
14 @palmerpenguins
15 @patchwork
16 @rmarkdown2018; @rmarkdown2020; @rmarkdown2022
17 @scales
18 @ThemePark
19 @tidyverseProbablity Distributions and Visualization
Princeton University
2023-09-24
What is probability theory?
Probability is the study of random processes
Probability is used to characterize uncertainty/randomness
![]()

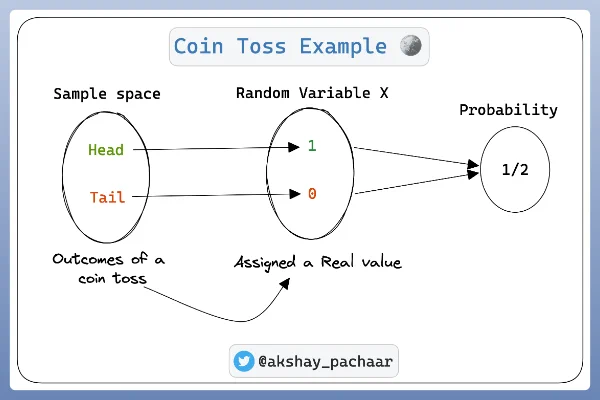
Illustration
Random variables are mappings from events to numbers
Formally, a random variable is defined as a function that maps the sample space \(\Omega\) of a random generative process into the real line (or into real numbers)
Discrete random variables: definition
Discrete random variables are defined on a range that is a countable set
i.e., they can only take on a finite or countably infinite number of different values

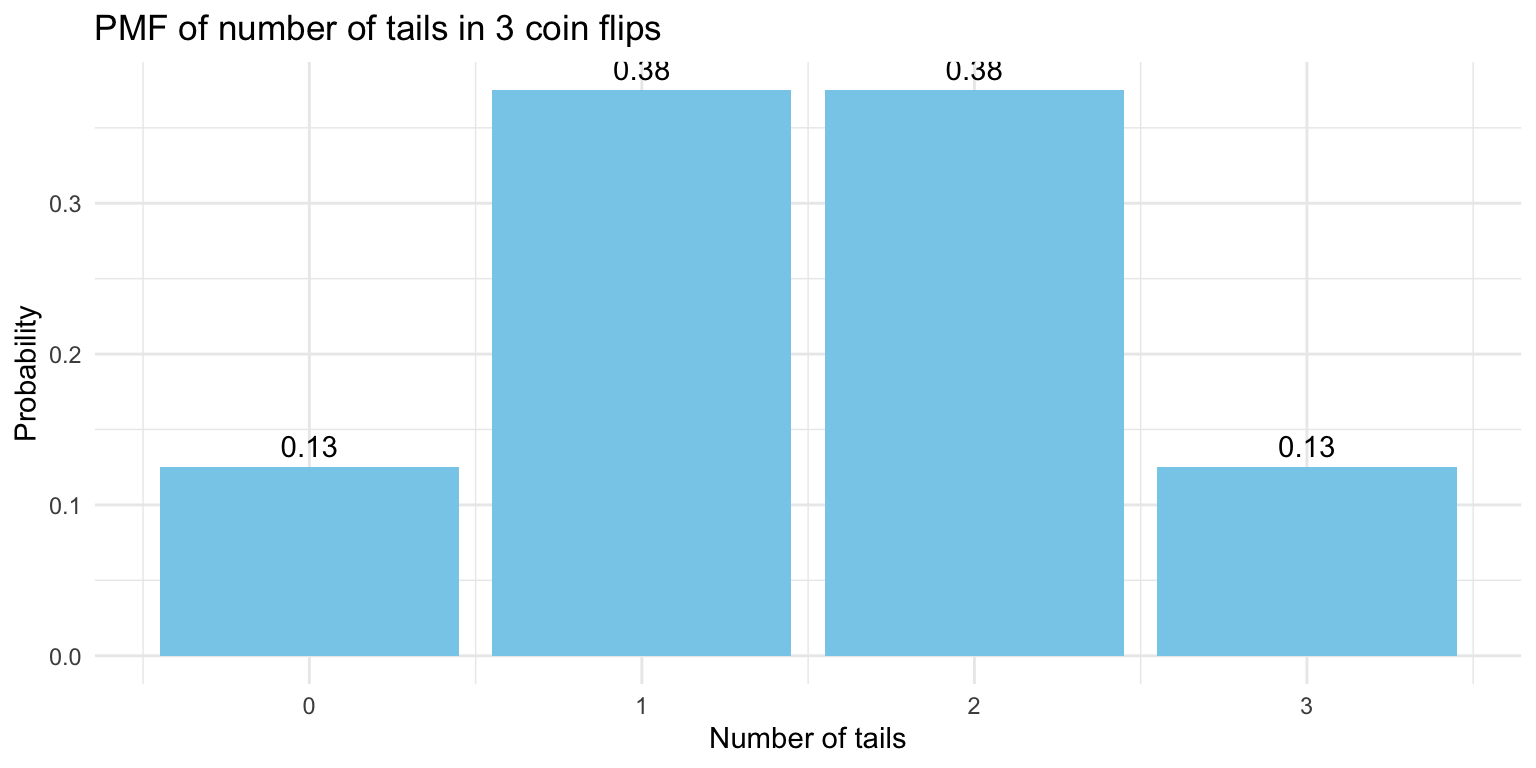
PMF: Dessert tonight
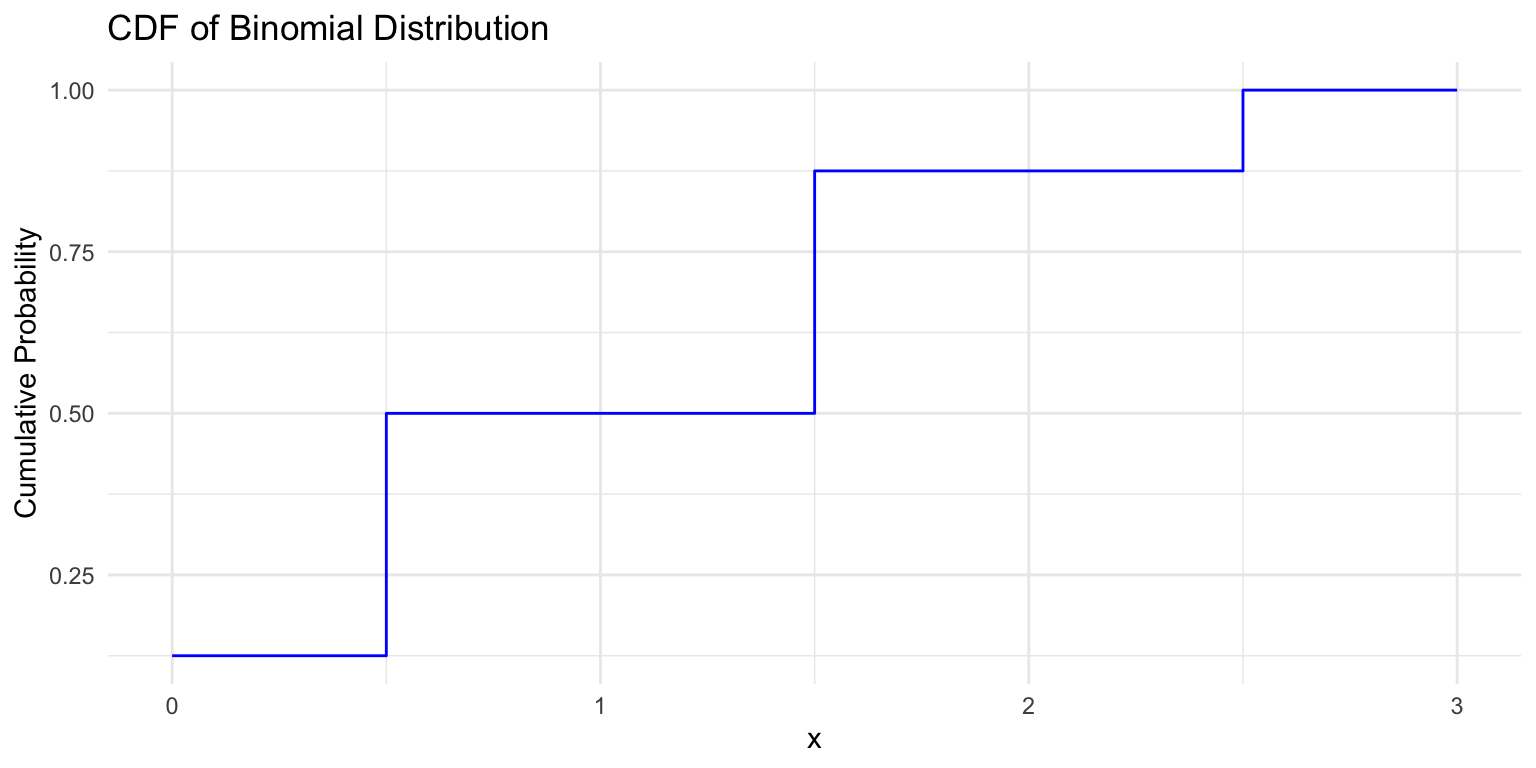
Cumulative distribution function (CDF): definition
The CDF of a random variable is the function \(F\) such that
- \(F(x) = P(X \leq x)\)
PMF tells us probability of each possible outcome
CDF tells us the probability that an outcome below a specific value occurs
Sums to 1
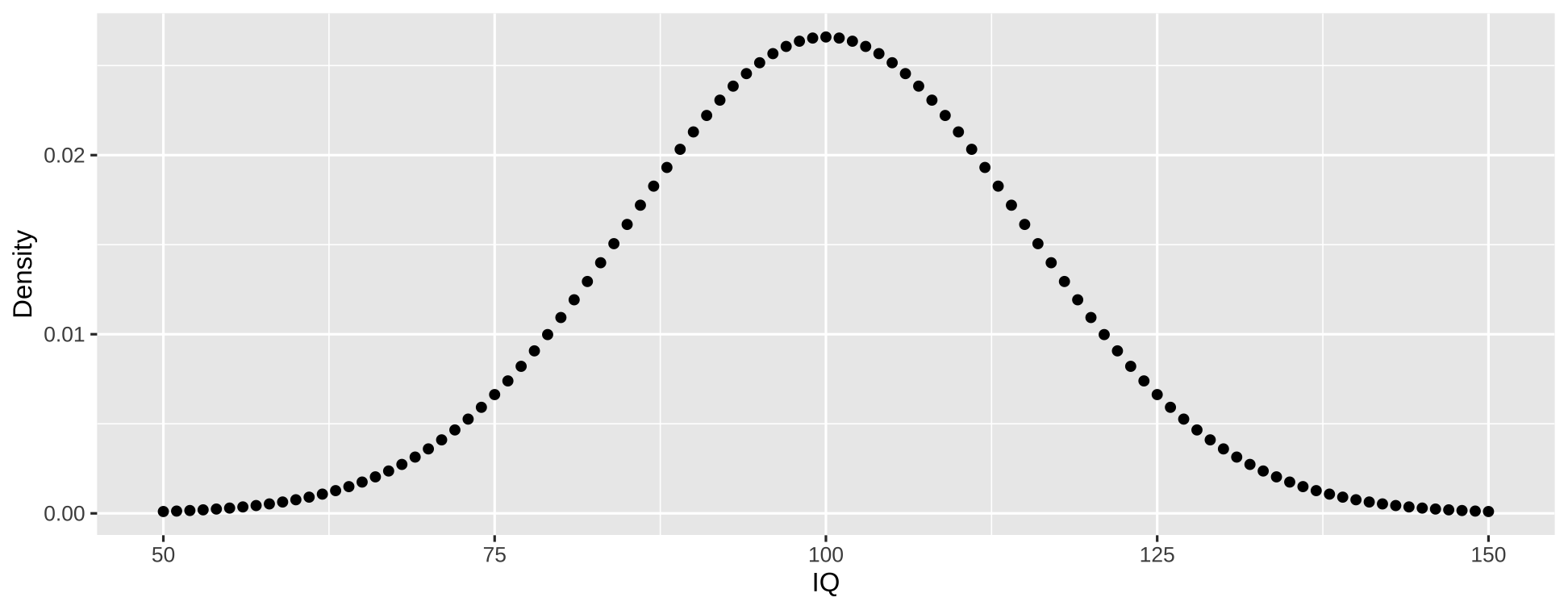
Continuous random variables: Definition
- A continuous random variable is a variable that can take on an infinite number of values within a given range or interval
Probability Density Function (PDF): Definition
- PDF is continuous version of PMF
- The PDF of a random continuous variable is the function \(F\) such that
\[P(a \leq X \leq b) = \int_{a}^{b} f(x) \, dx\]
- PDF tells us the probability of range of outcomes
- What is probability of observing IQ between 100 and 125?
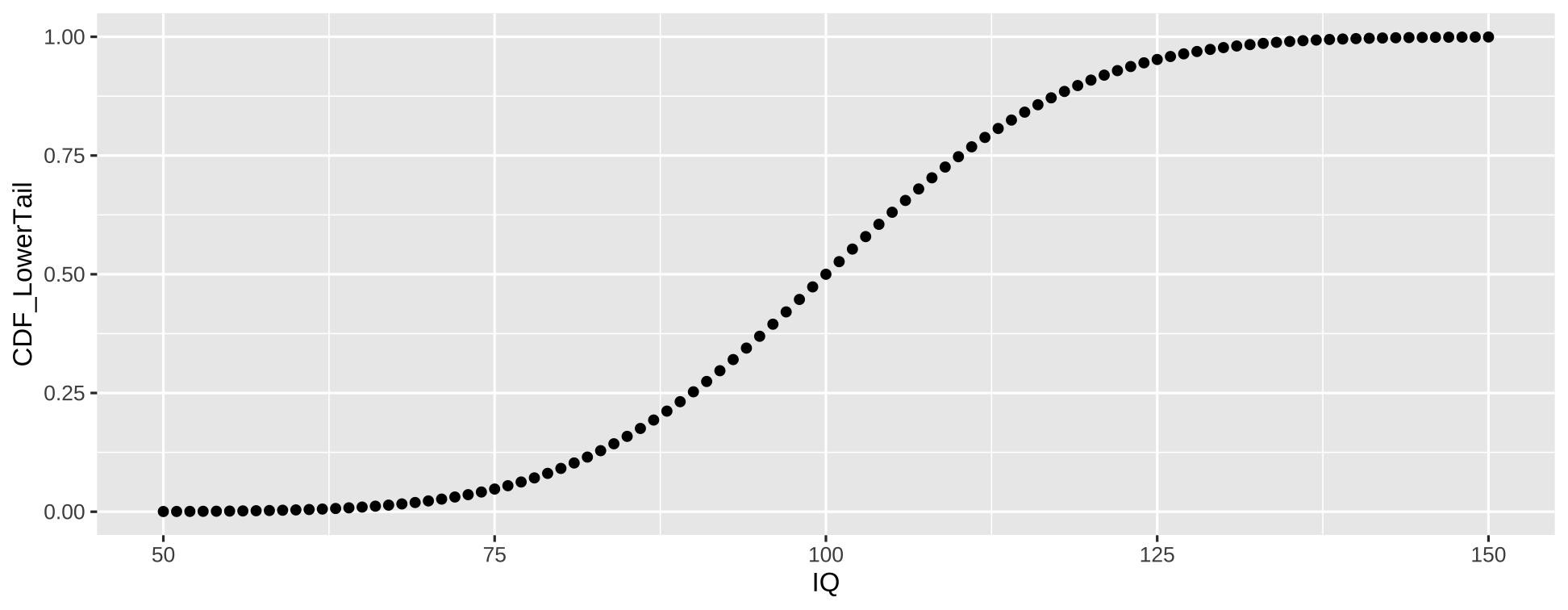
CDF
\(F(x) = P(X \leq x)\)
- \(IQ \leq 100\)
Our goal as statisticians
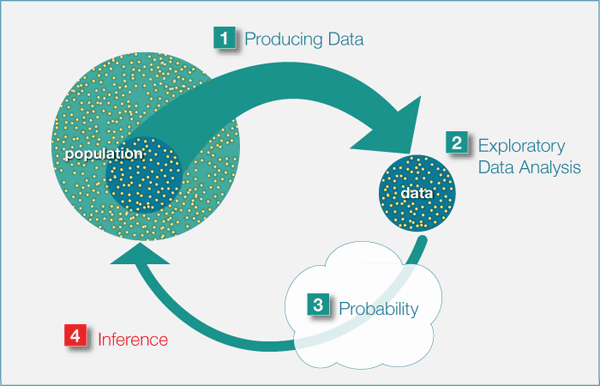
Link probability distributions to the data generating process (DGP)
The DGP represents the “real-world” process of how data comes about
Probability distributions are mathematical models used to model and understand the DGP
DGP
Bottom-up: This approach begins with the observed data. By examining the data distribution, one might make educated guesses or inferences about the underlying processes that produced it
Top-down: This approach relies on pre-existing knowledge or theories about the system or phenomenon in question to inform our understanding of the DGP
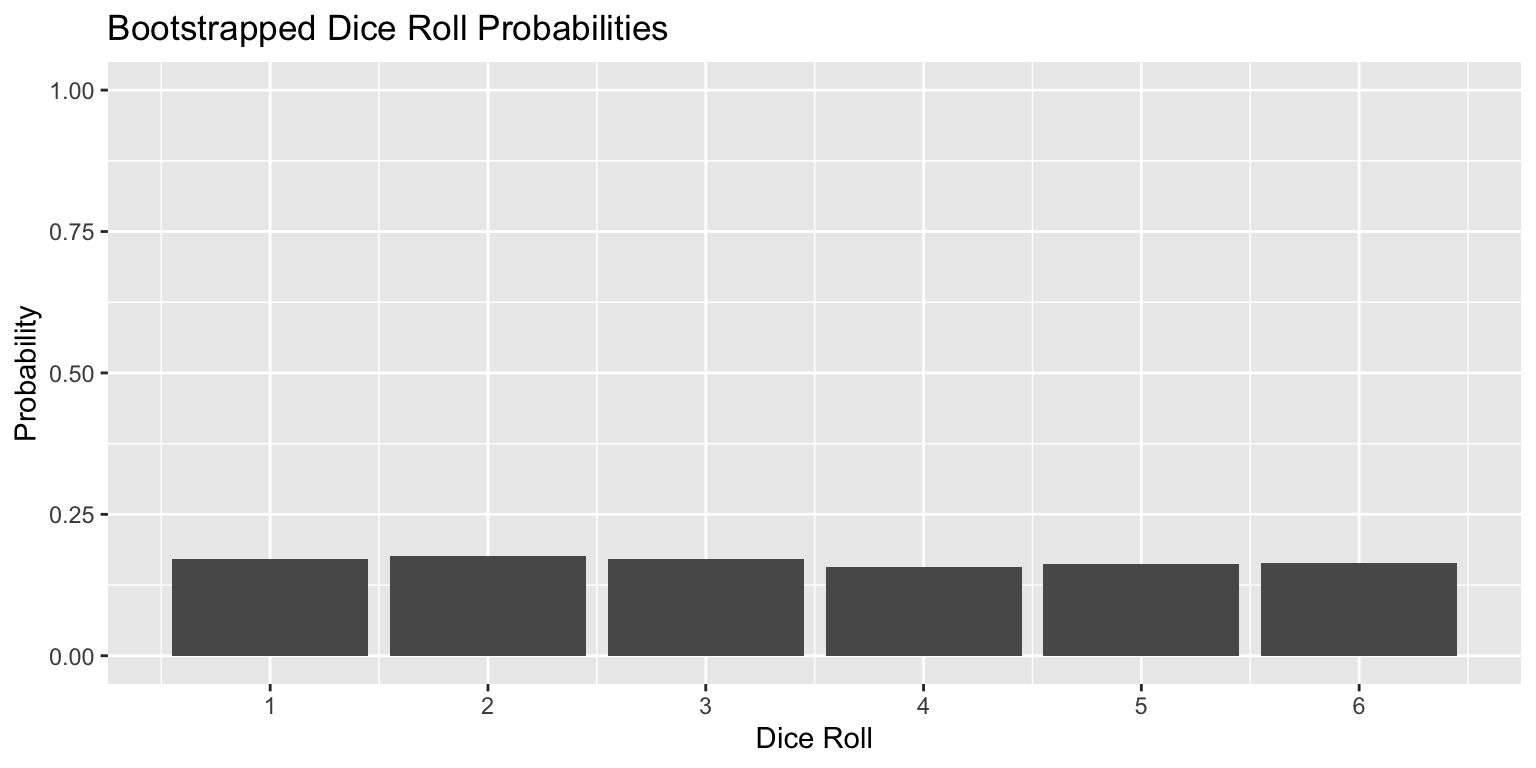
Bootstrapping
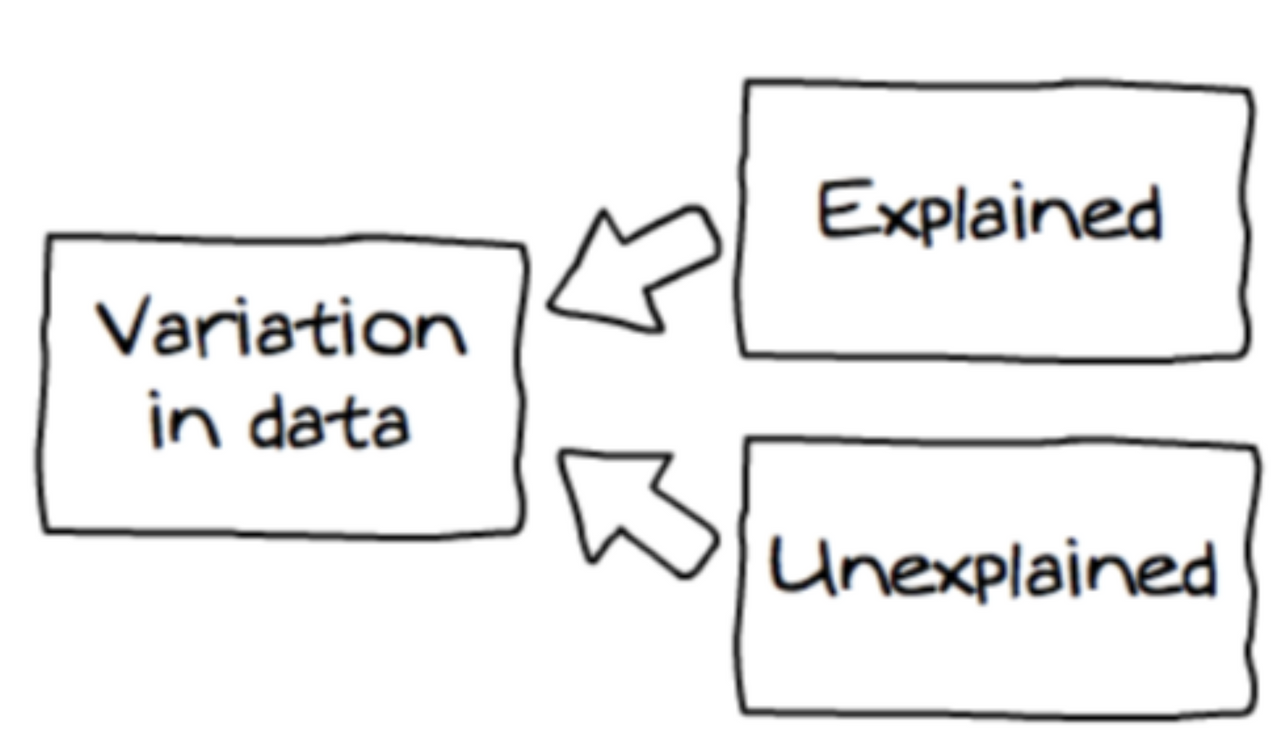
Sources of Variance
- There is uncertainty associated with the DGP


Randomness
Shuffling (permutation tests)
Rind and Bordia (1996)
![]()
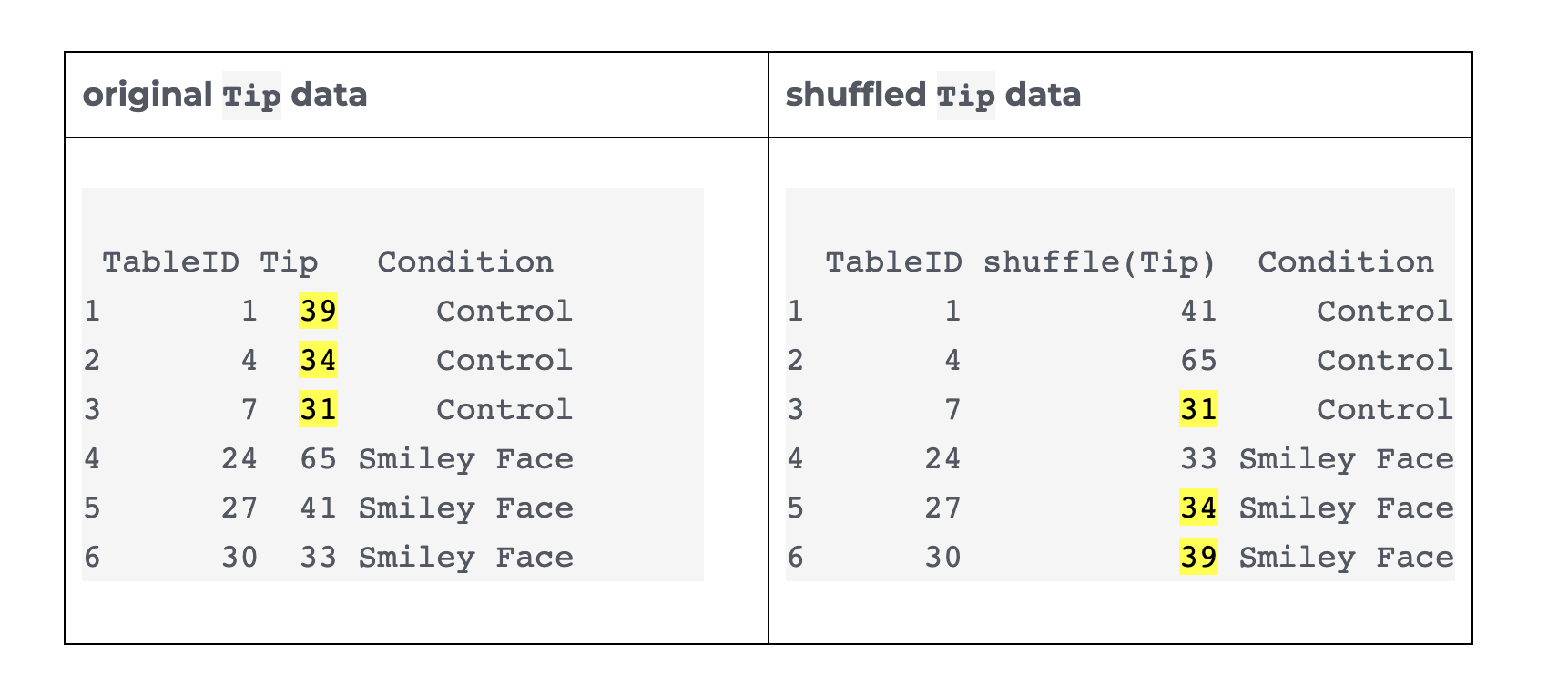
Visualizing variance

ggplot2is tidyverse’s data visualization package (plotninein Python uses similar syntax)The gg in
ggplot2stands for Grammar of GraphicsIt is inspired by the book Grammar of Graphics by Leland Wilkinson
A grammar of graphics is a tool that enables us to concisely describe the components of a graphic
ggplot2
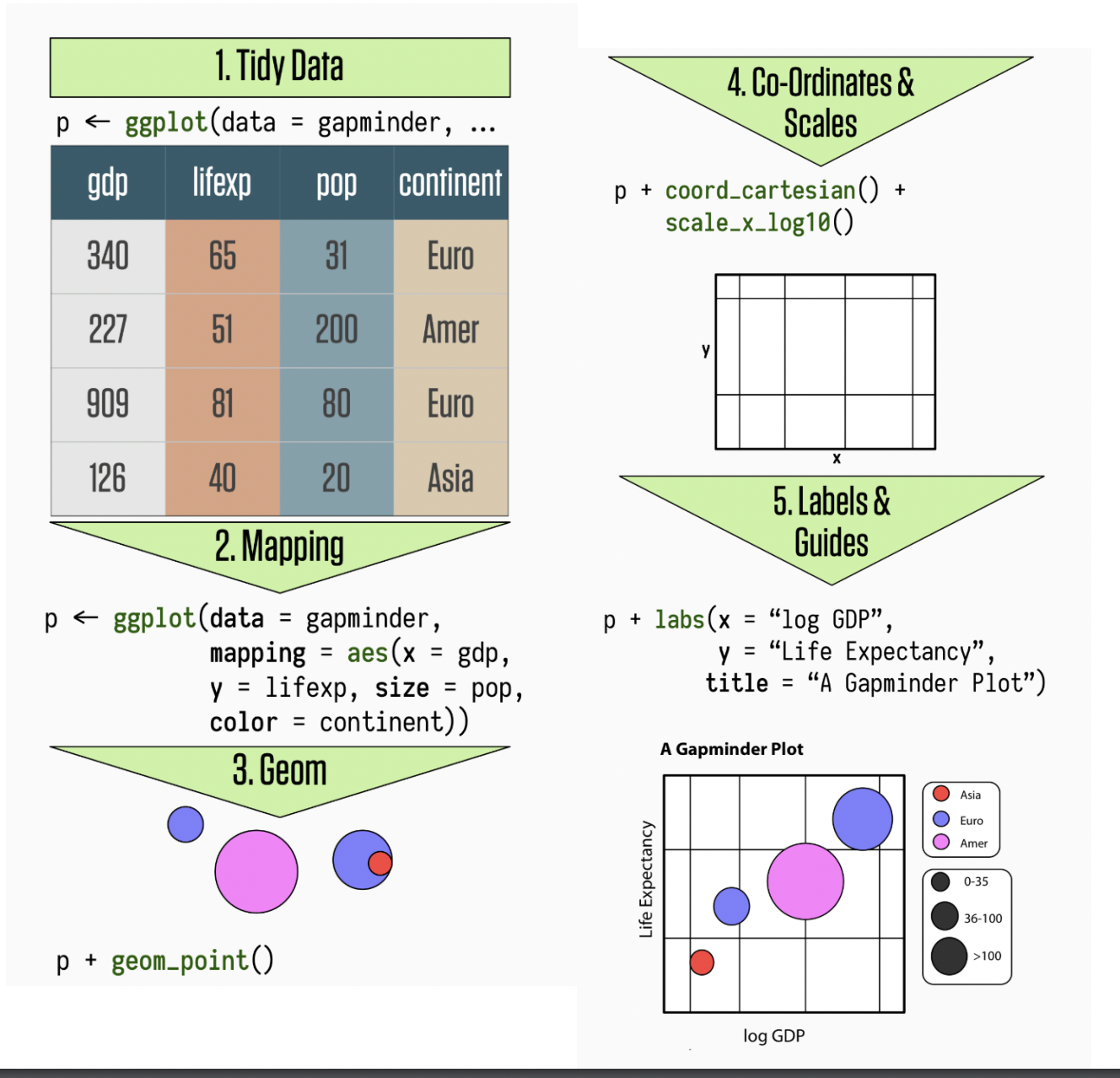
ggplot2
Let’s start with a blank canvas

ggplot2 - Data
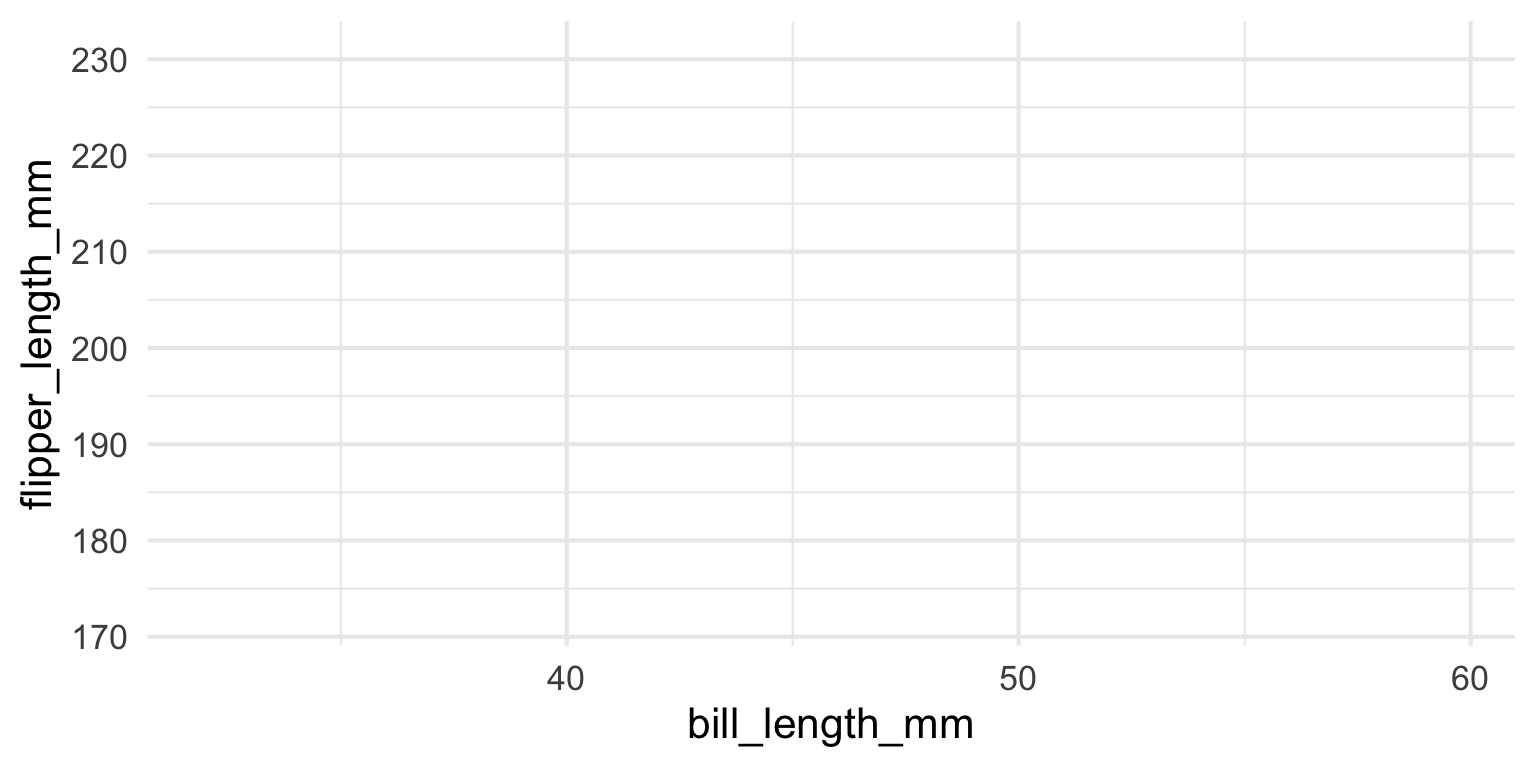
ggplot2 - Layers
Let’s add a geom
geom_pointadds a dot for each raw data point
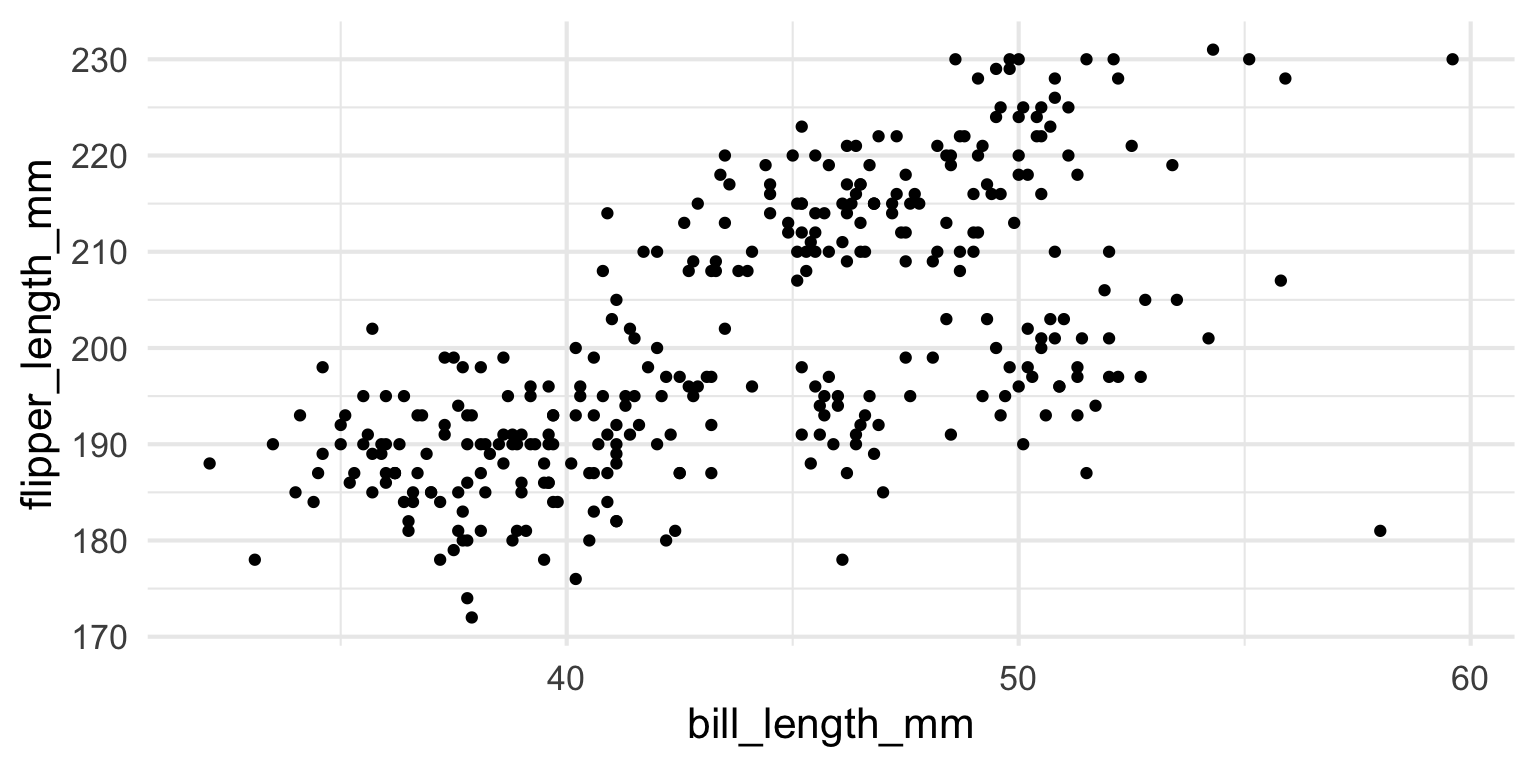
ggplot2 - Layers
Let’s add another geom
geom_smoothplots a smoothed line for the data
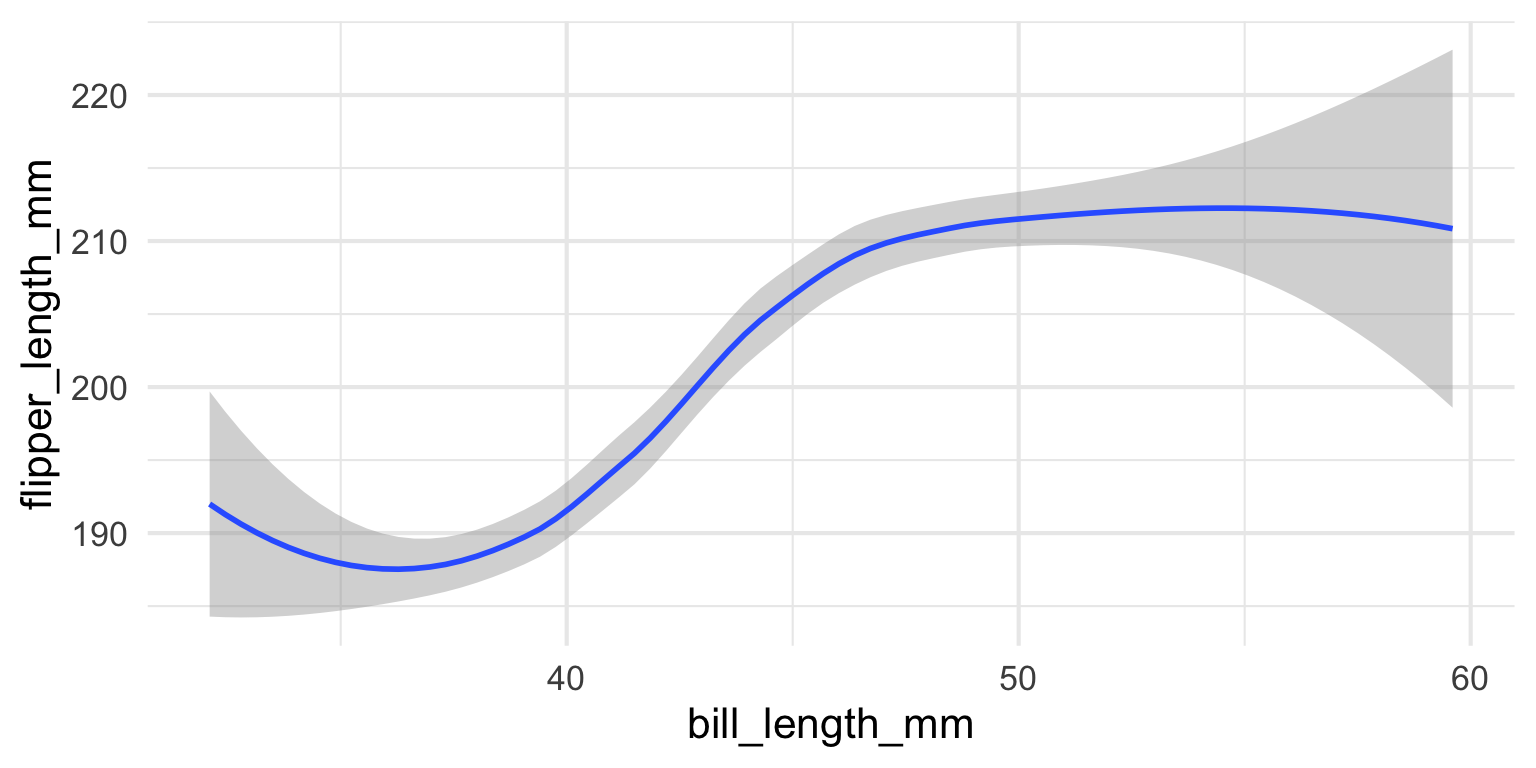
ggplot2 Layers
- Maybe a linear line
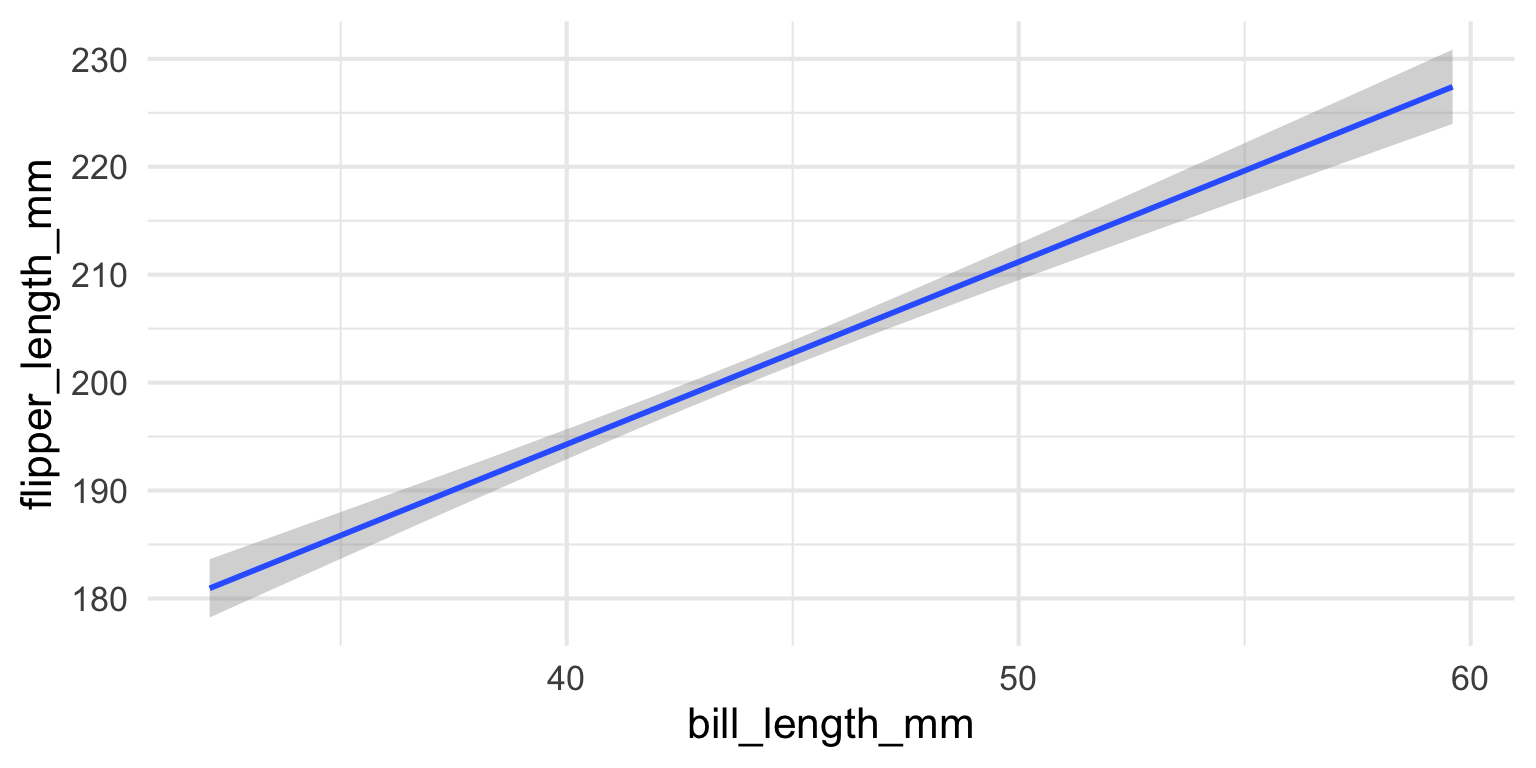
ggplot2 - Layers
- It might be nice to see the raw data WITH the line. We can combine geoms!
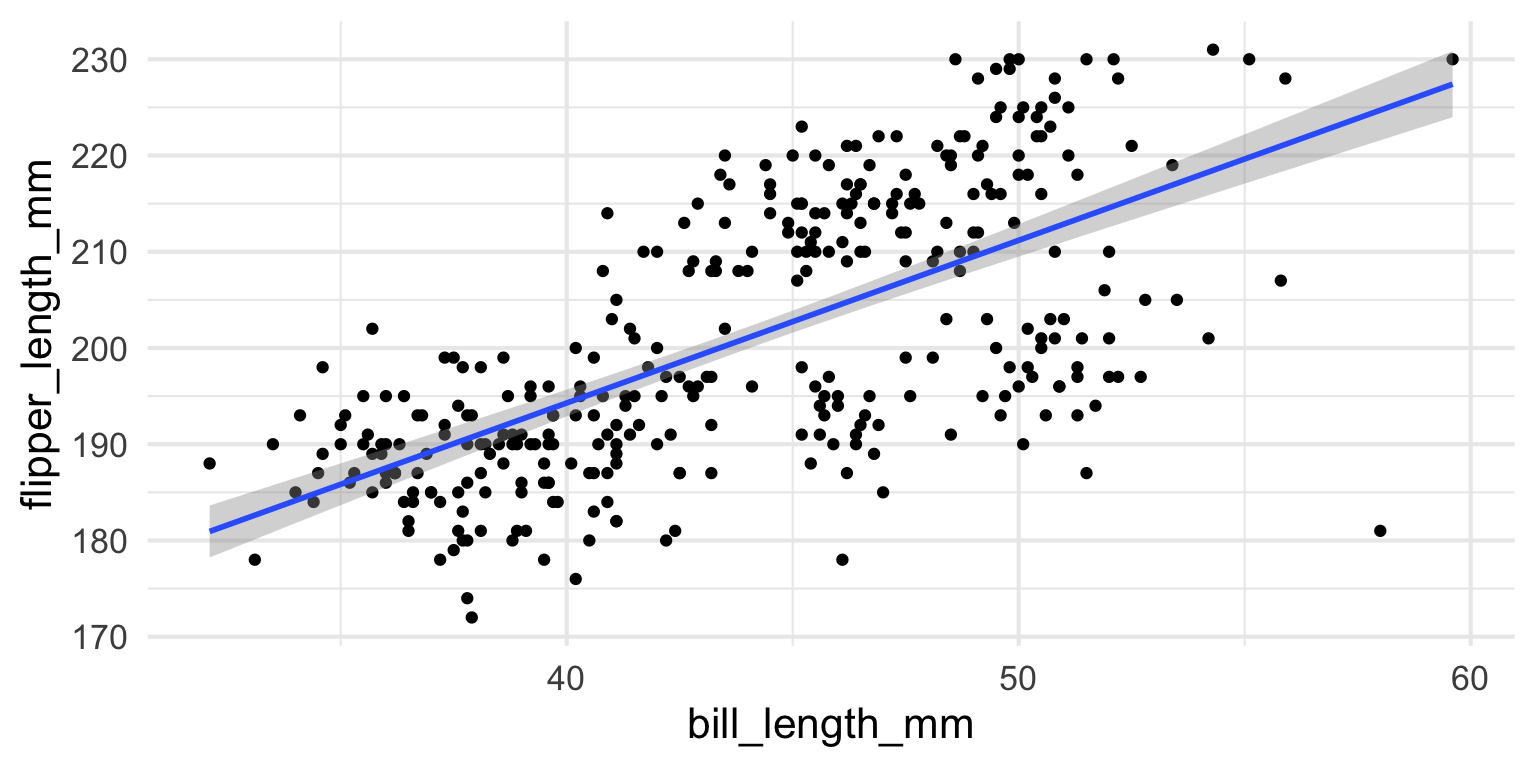
ggplot2 - Size
- Points are a bit small. Let’s make them bigger!
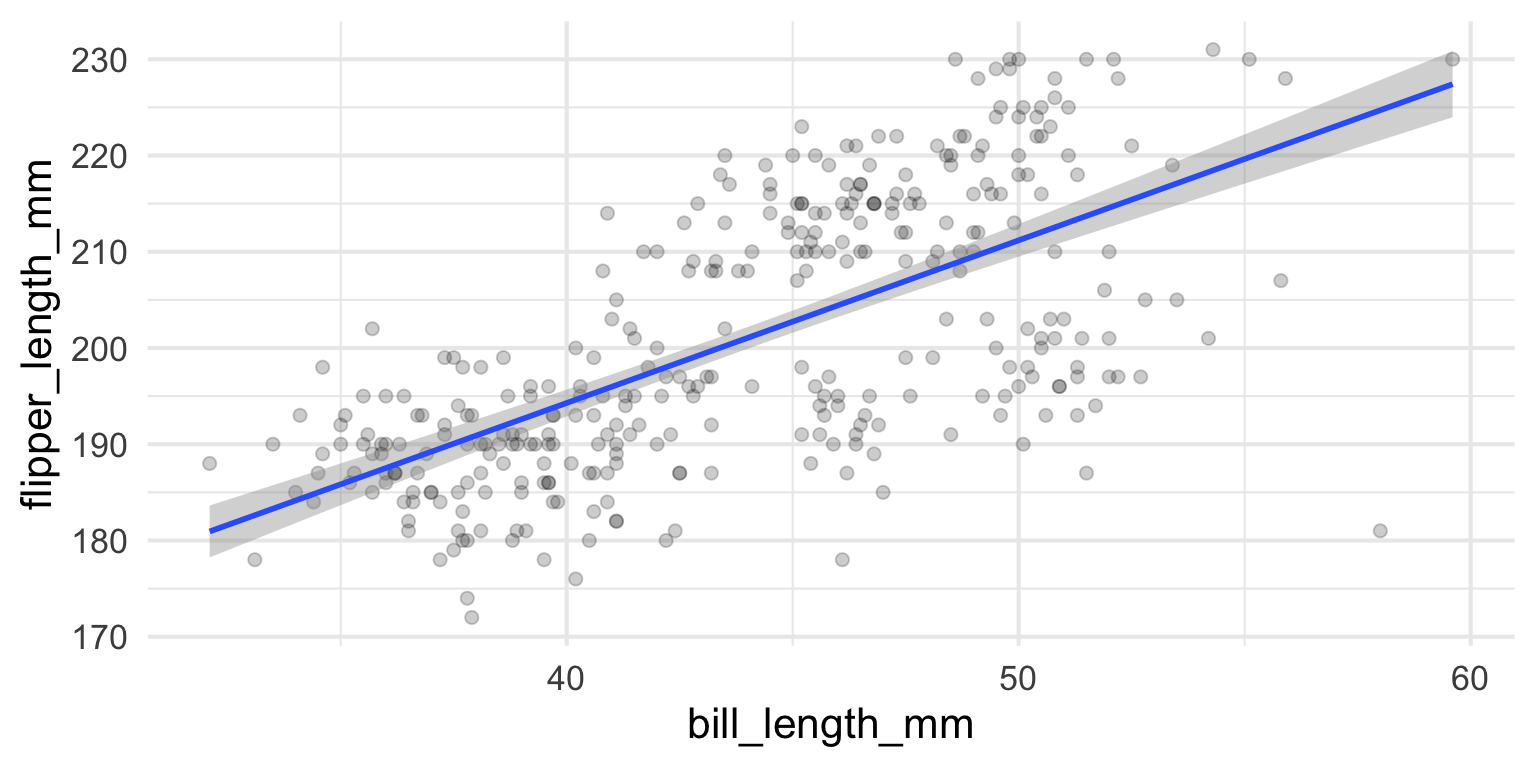
ggplot2 - Color
- How could we add information about different types of penguins?
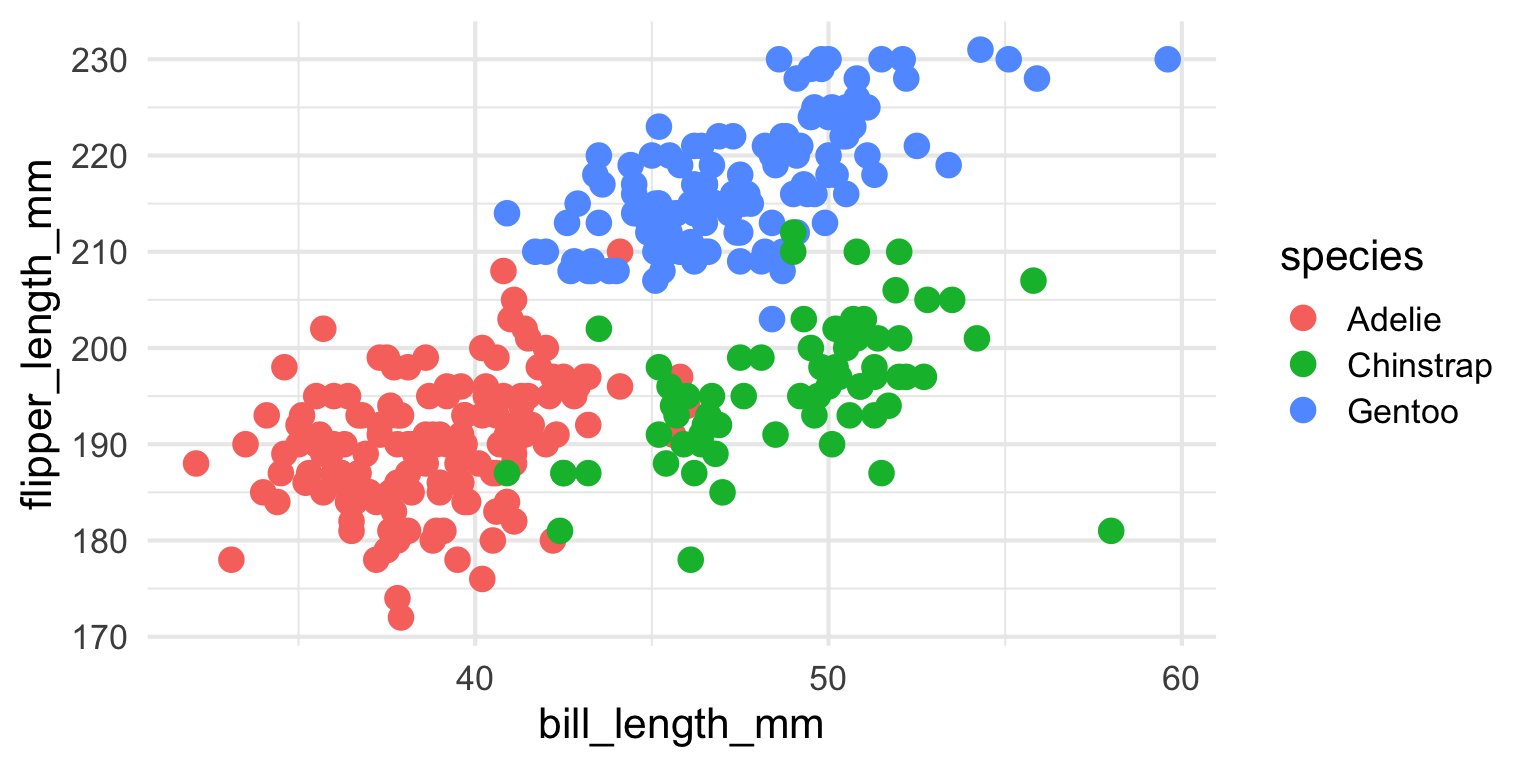
ggplot2 - Title
Let’s clean up our plot
Add title
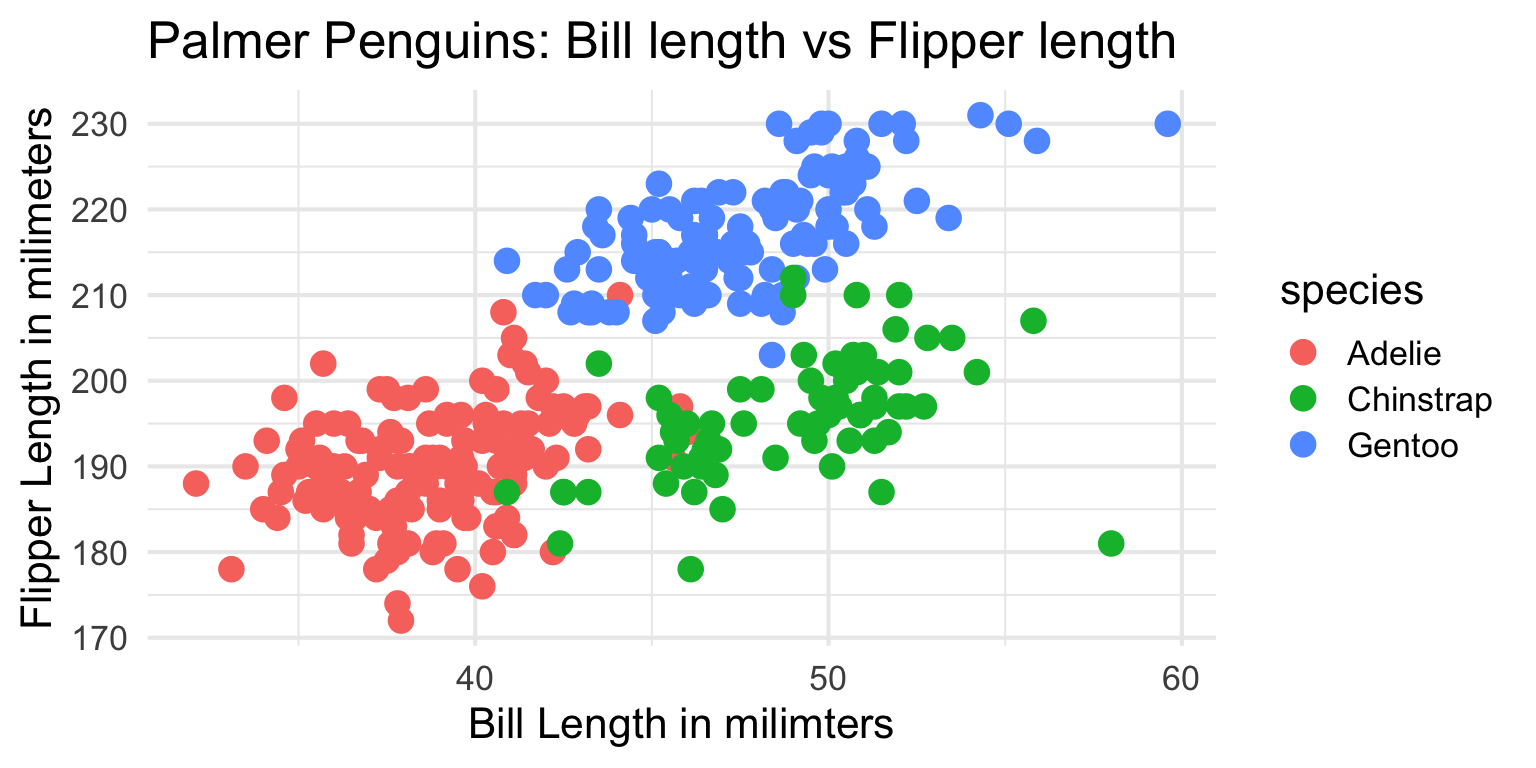
ggplot2 - Themes
theme_plot <- ggplot(data=penguins, mapping = aes(x=bill_length_mm, y = flipper_length_mm, color=species)) +
geom_point(size = 4) +
xlab("Bill Length in milimters") +
ylab("Flipper Length in milimeters") +
ggtitle("Palmer Penguins: Bill length vs Flipper length") +
theme_dark(base_size = 16)
theme_plot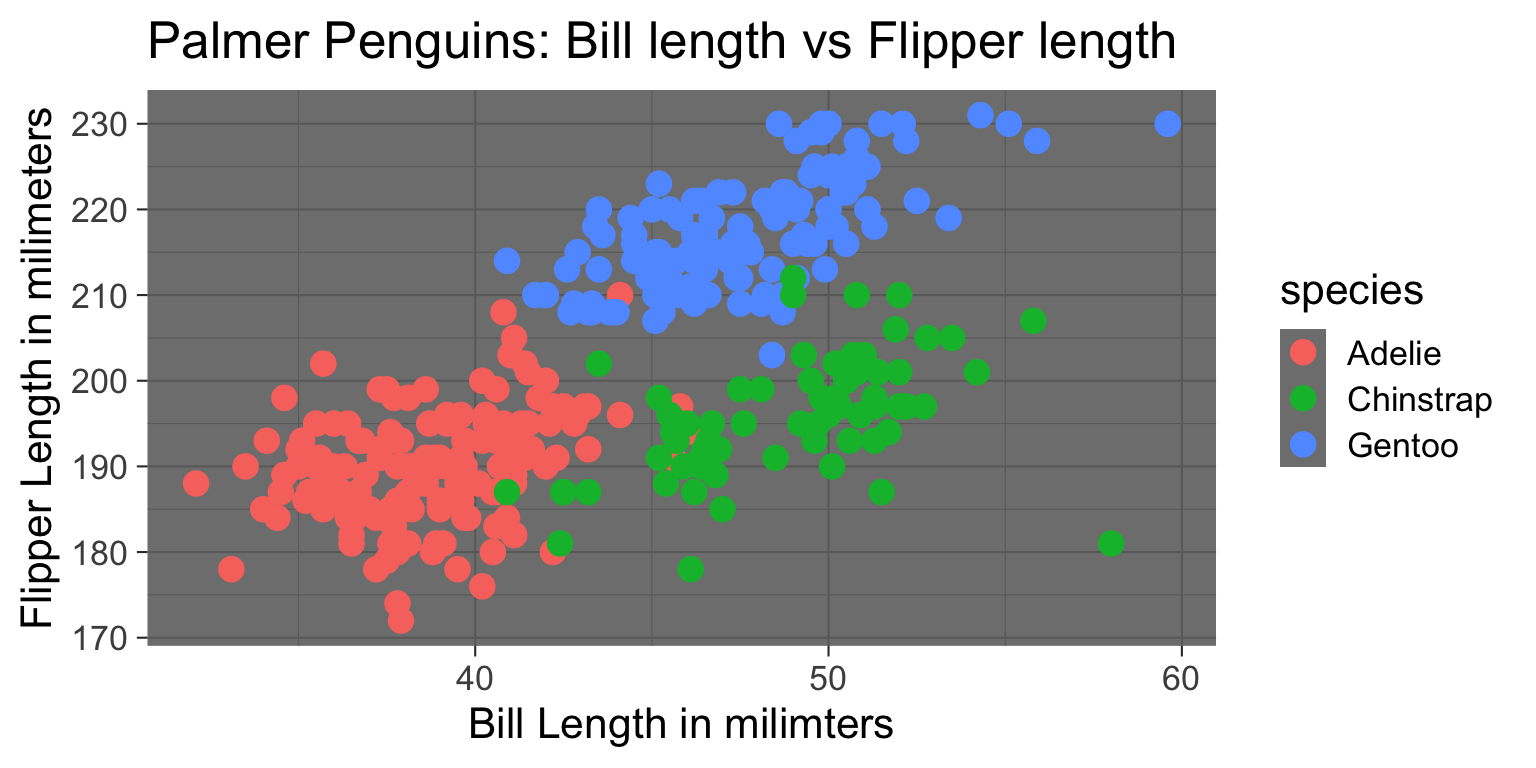
ggplot2 - Color themes


library(MetBrewer)
#| code-line-numbers: "6"
#| fig-align: center
ggplot(data=penguins, mapping = aes(x=bill_length_mm, y = flipper_length_mm, color=species)) +
geom_point(size = 4) +
xlab("Bill Length in milimters") +
ylab("Flipper Length in milimeters") +
ggtitle("Palmer Penguins: Bill length vs Flipper length") + # Changes legend title, and selects a colour-palette
scale_colour_manual(
values = MetBrewer::met.brewer("VanGogh2",3)) +
theme_minimal(base_size = 16)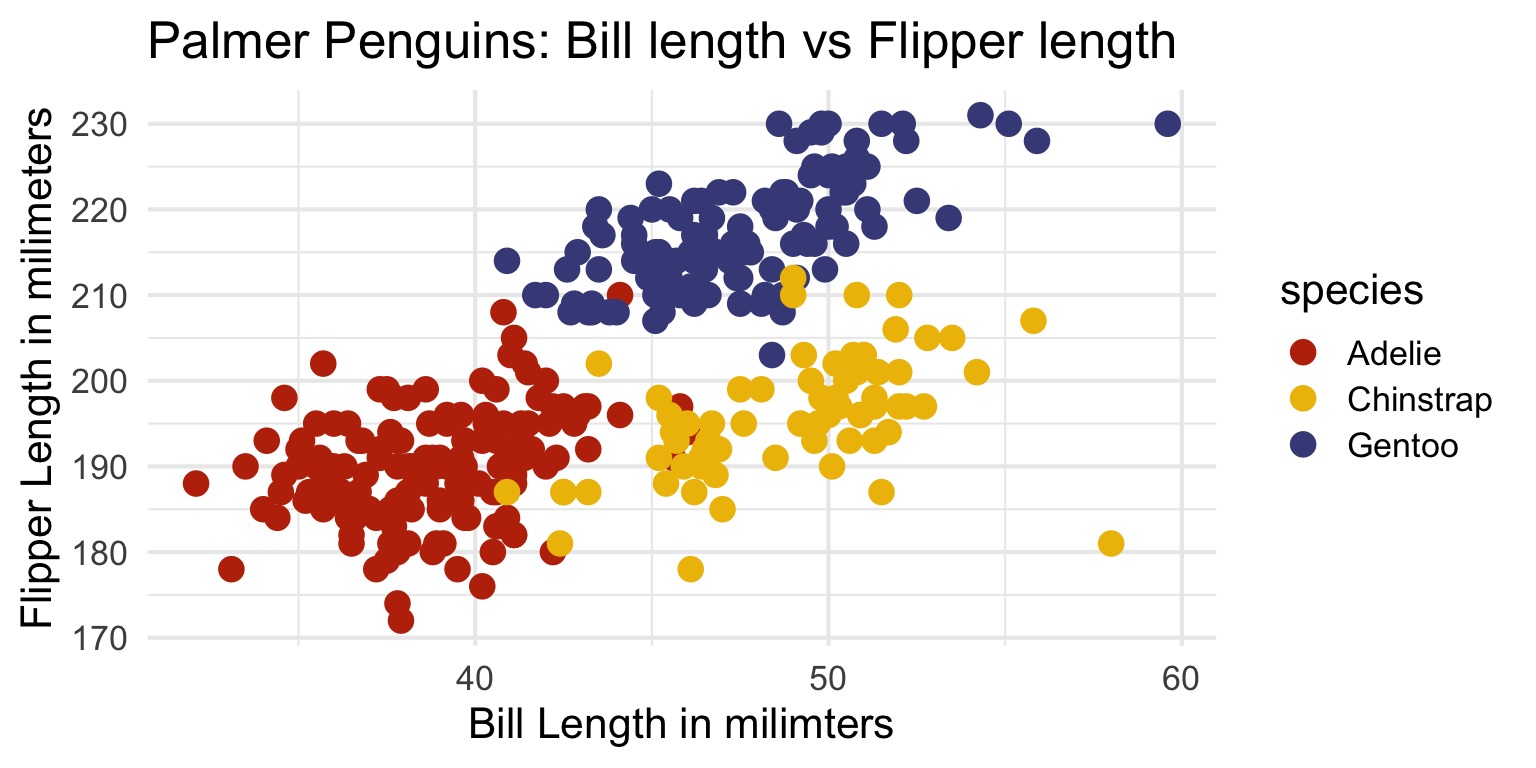
ggplot2 - Themes

library("ThemePark")
`X variable` <- rnorm(50, 0, 1)
`Y variable` <- rnorm(50, 0, 1)
ggplot(data = data.frame(x = `X variable`, y = `Y variable`), aes(x = x, y = y)) +
geom_smooth(method = 'lm', color = barbie_theme_colors["medium"]) +
geom_point() +
labs(title = 'Barbie Scatter Plot') +
theme_barbie()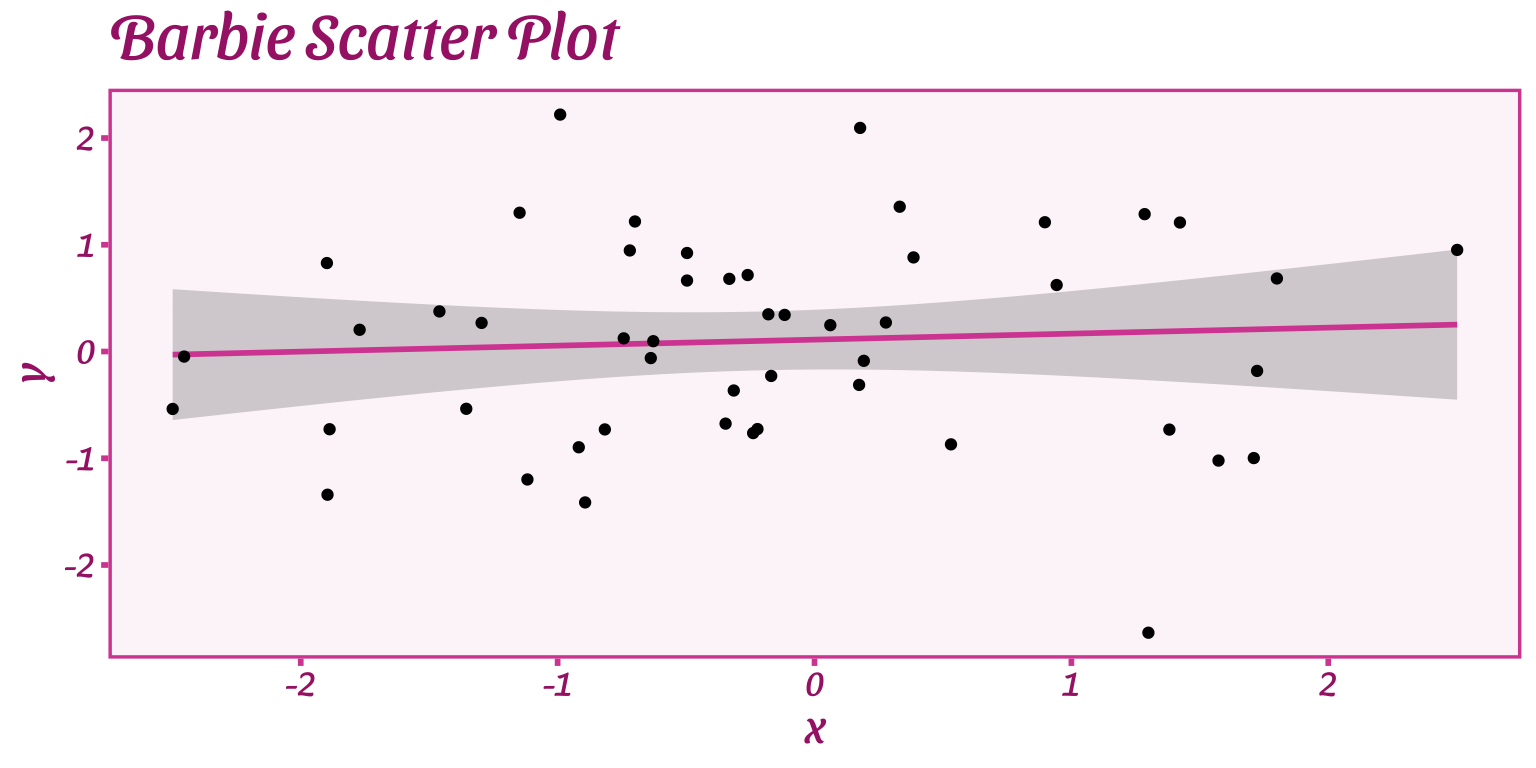
Disclaimer
- More information is always better!
- Avoid visualizing single numbers when you have a whole distribution of numbers

Histograms
Put data into equally spaced buckets (or bins), plot how many rows are in each bucket
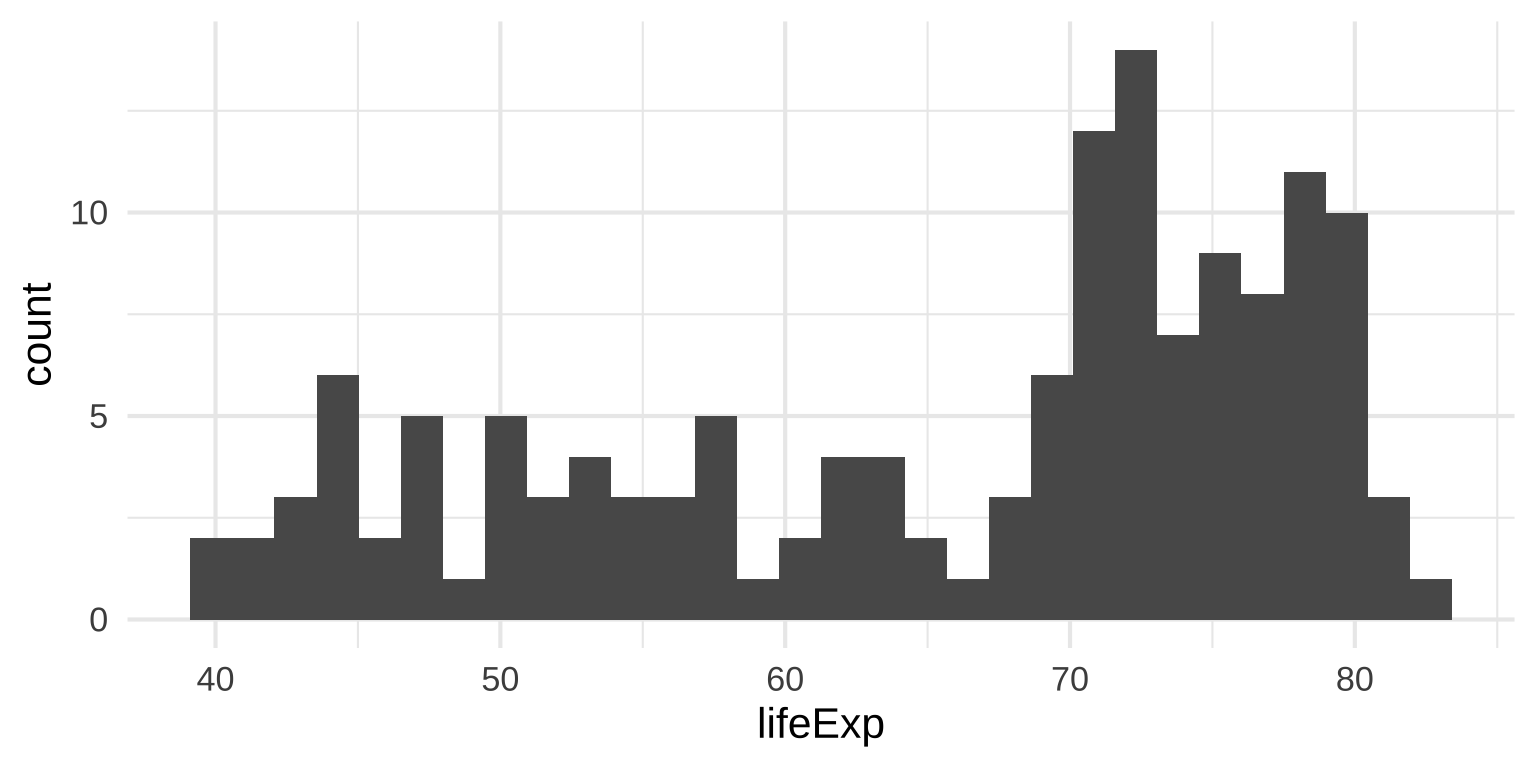
ggdist
Put data into equally spaced buckets (or bins), plot how many rows are in each bucket
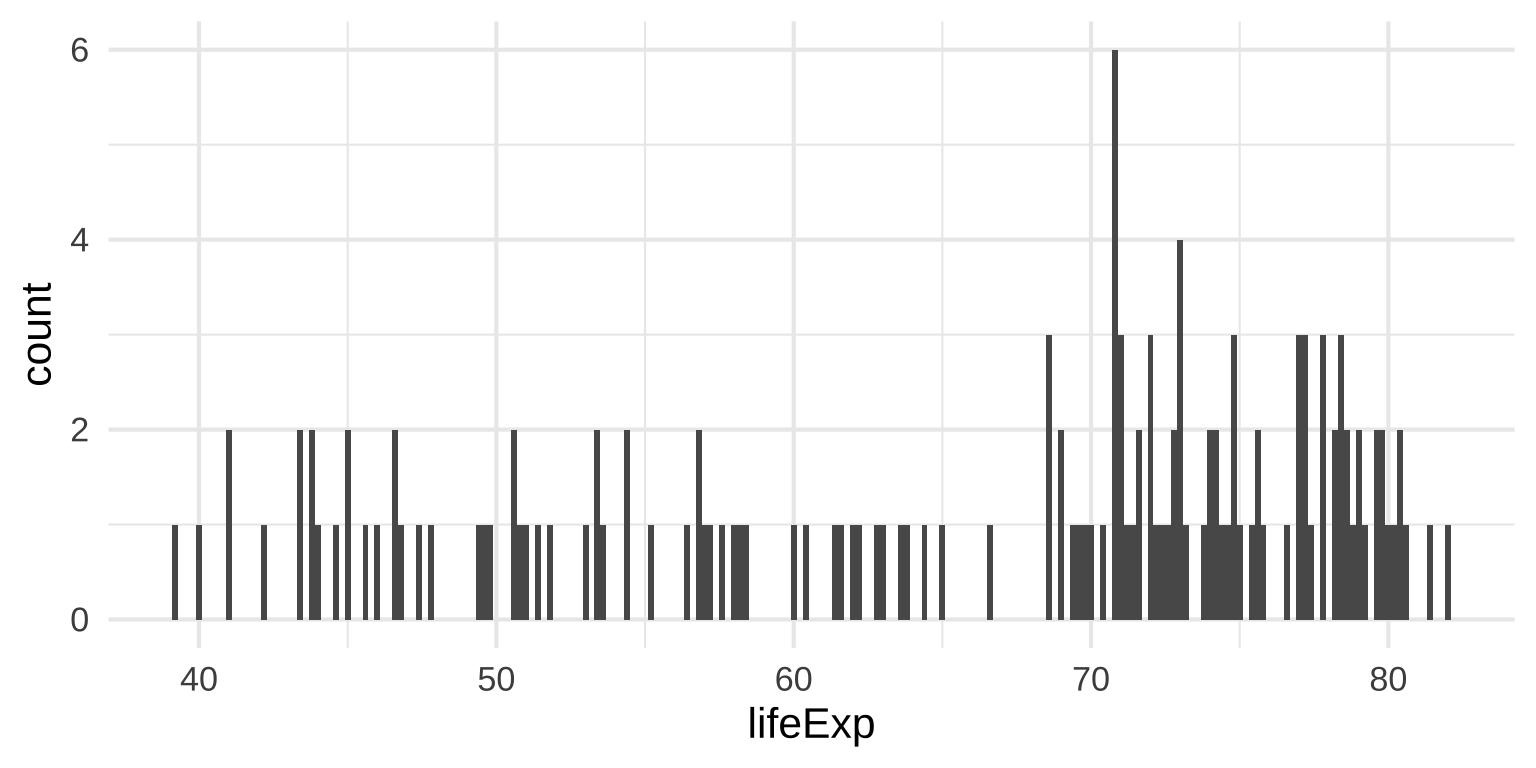
Histograms: Bin width
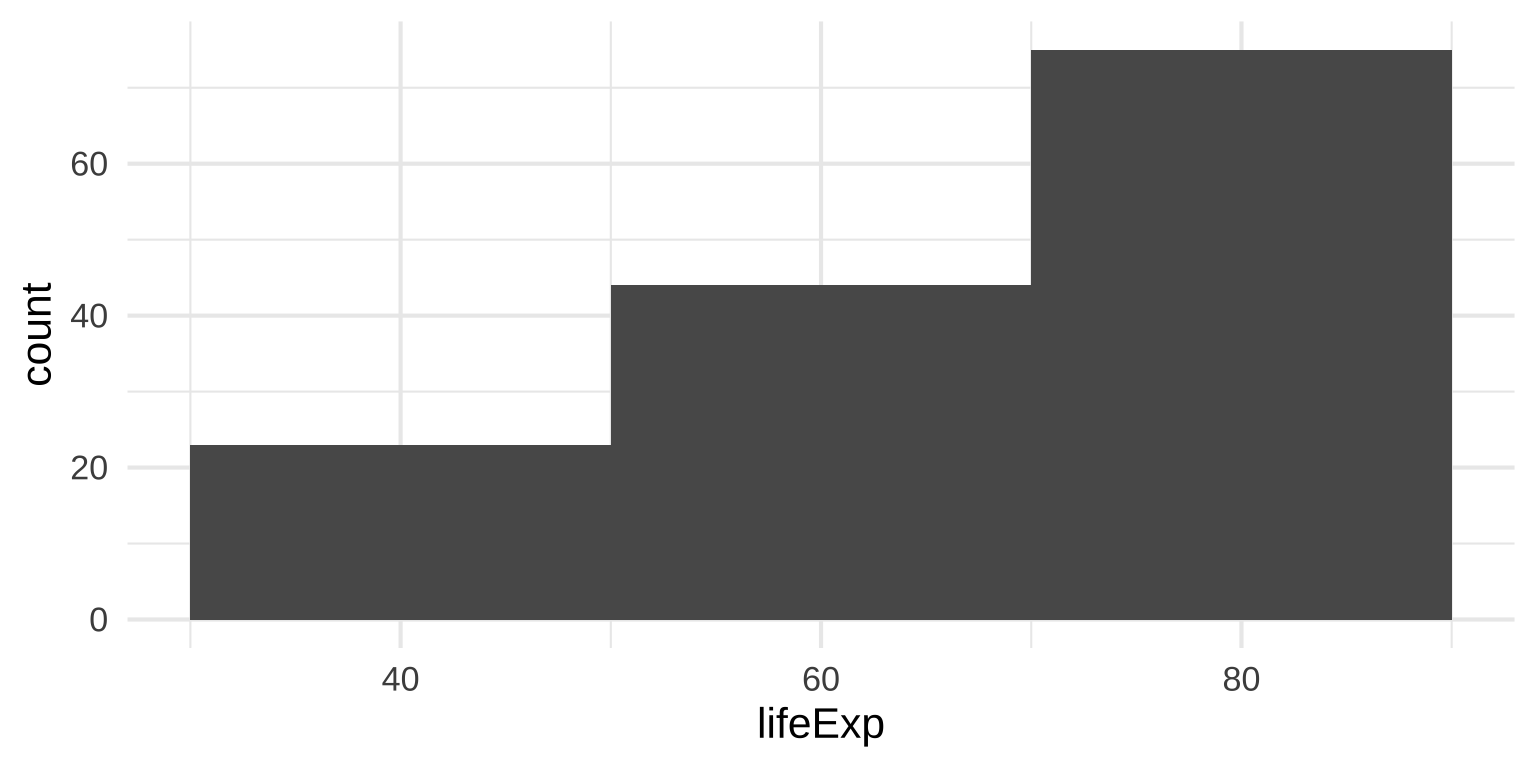
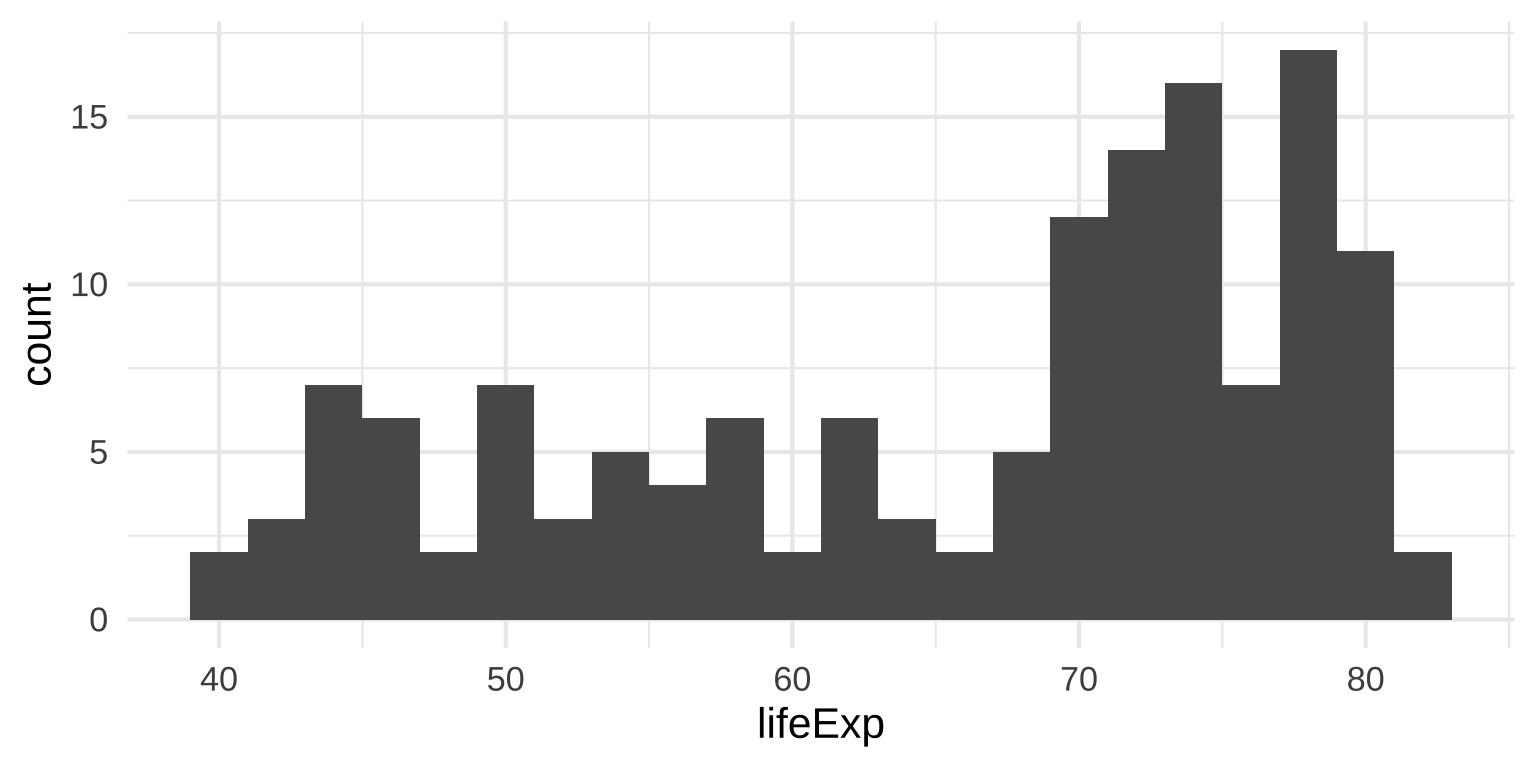
Histogram tips
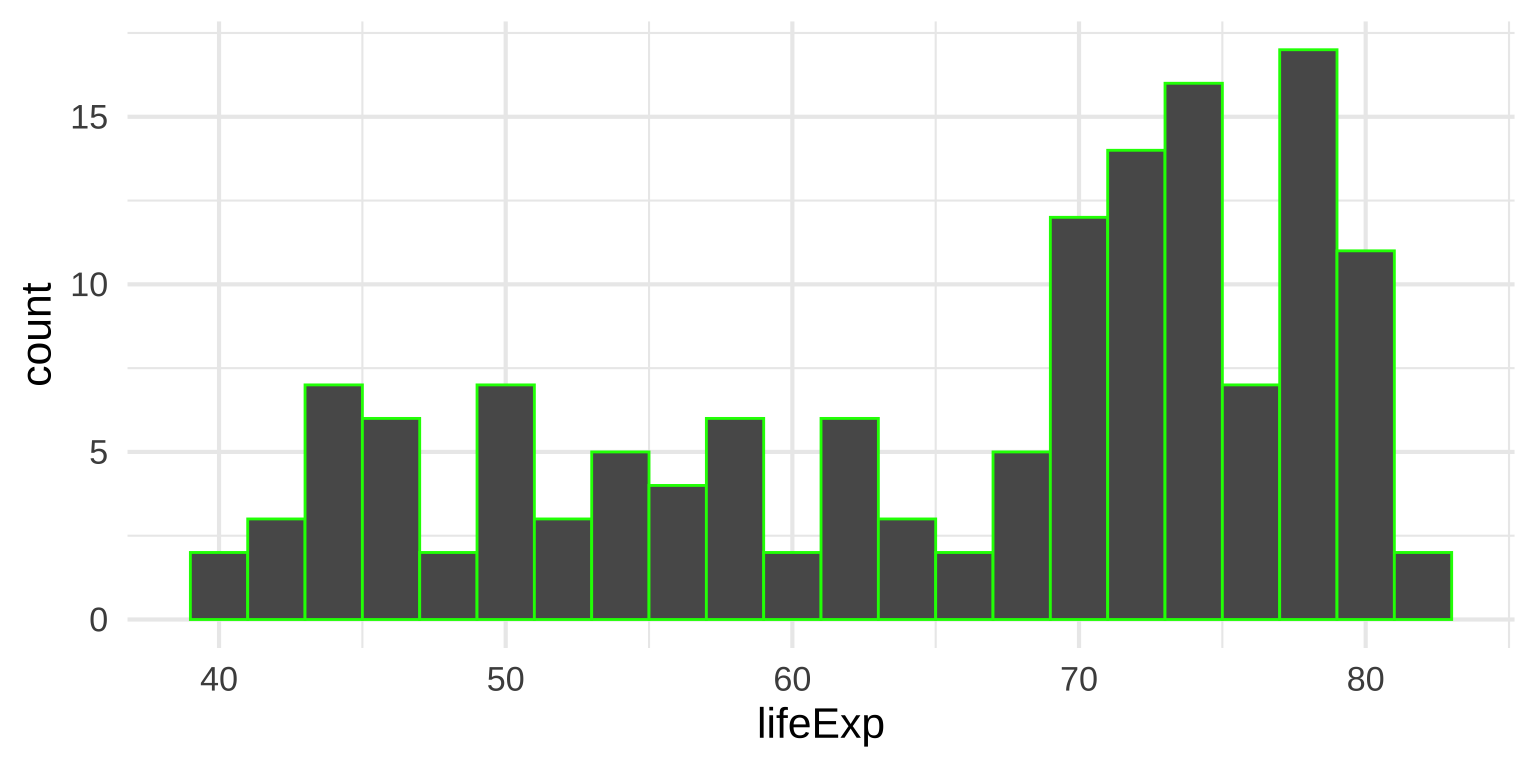
Histogram tips
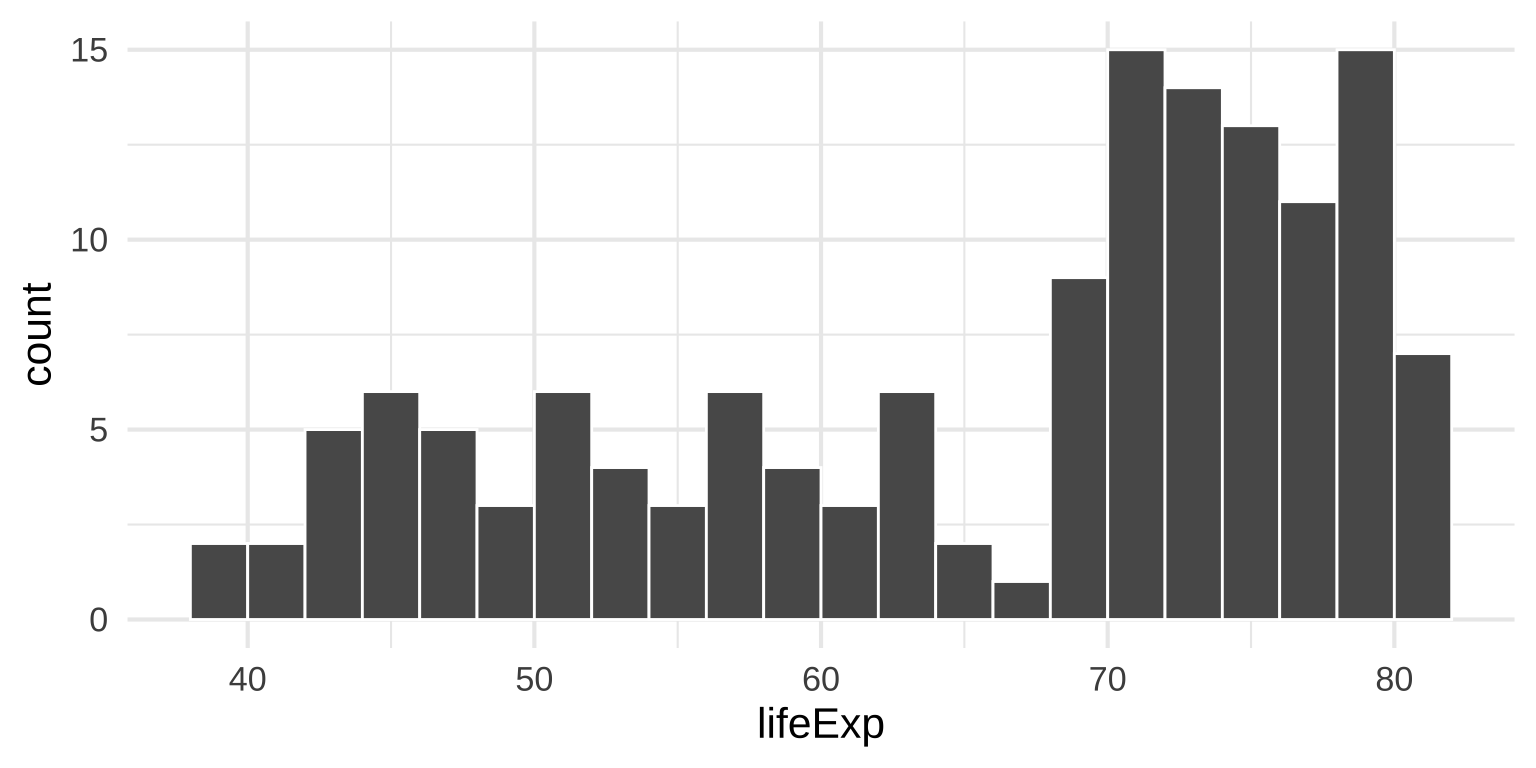
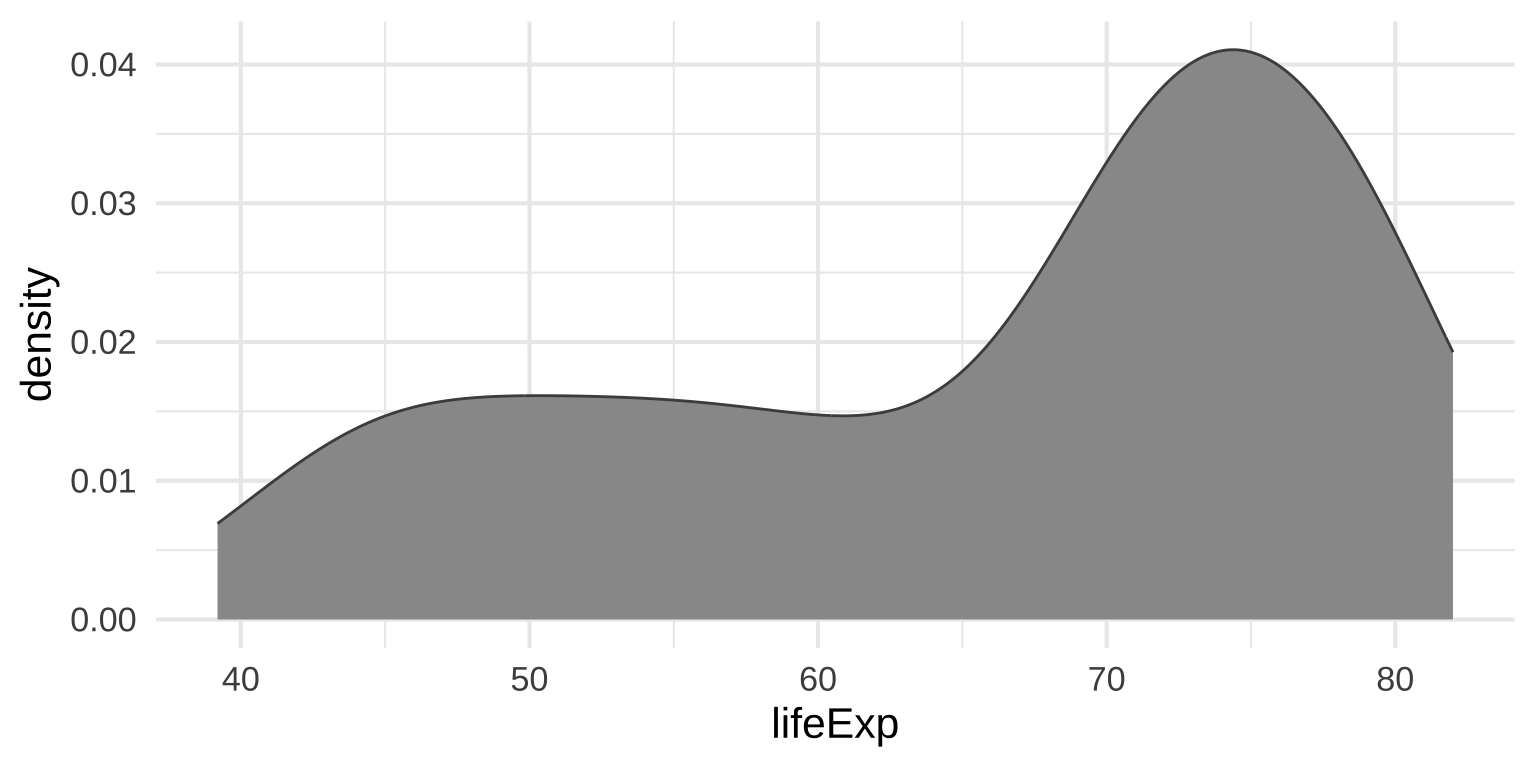
Density plots
Use calculus to find the probability of each x value
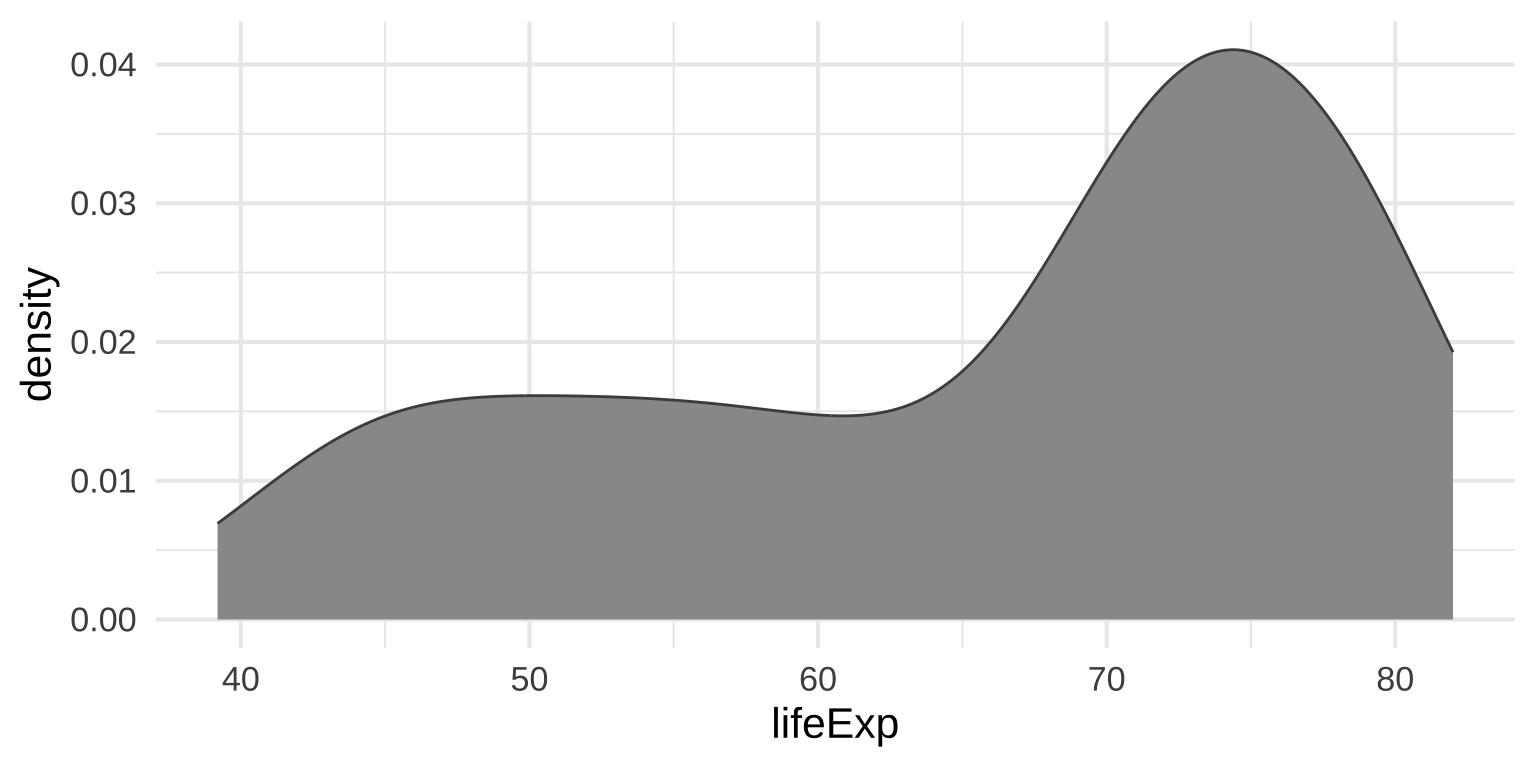
Density plots: Kernels and bandwidths
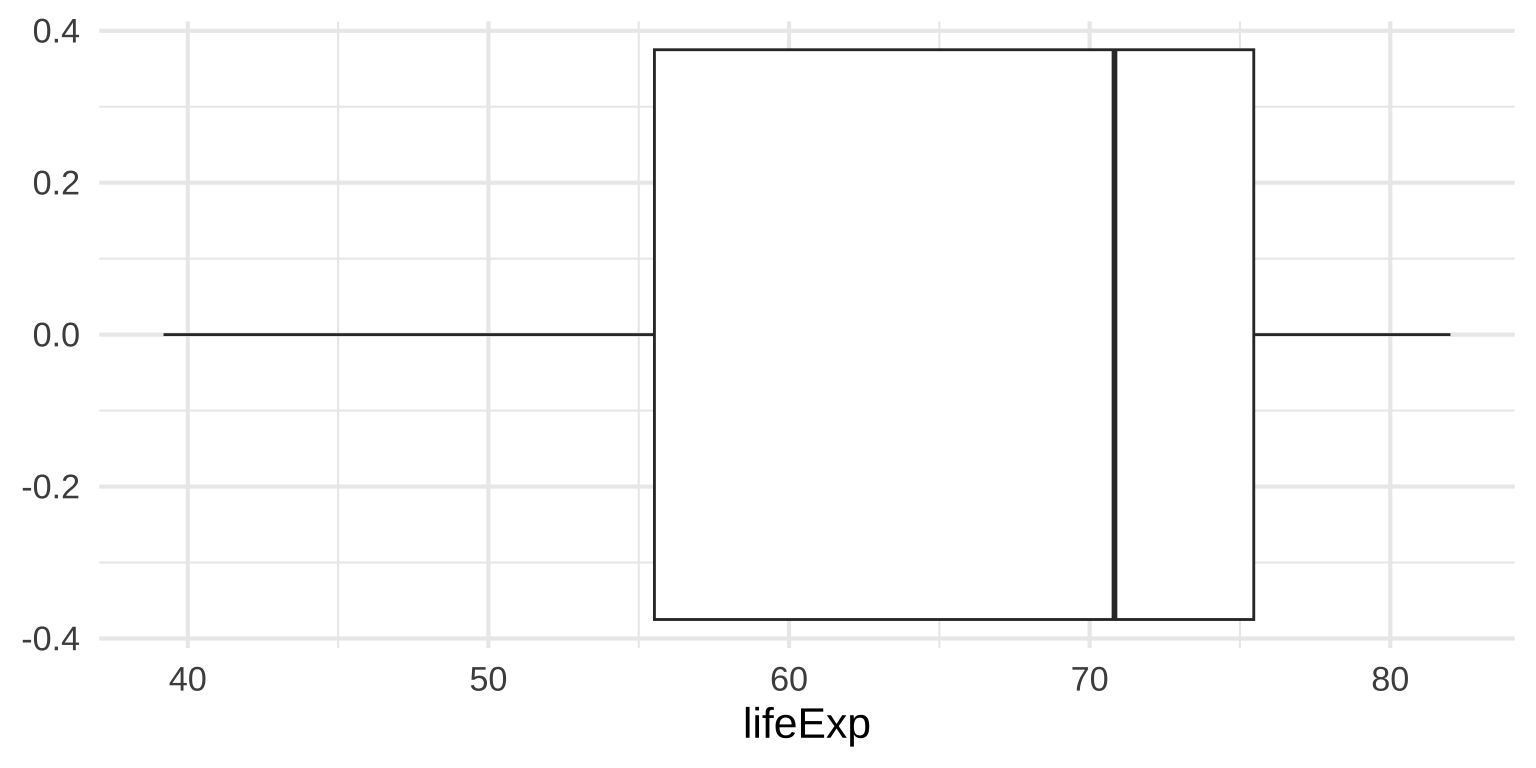
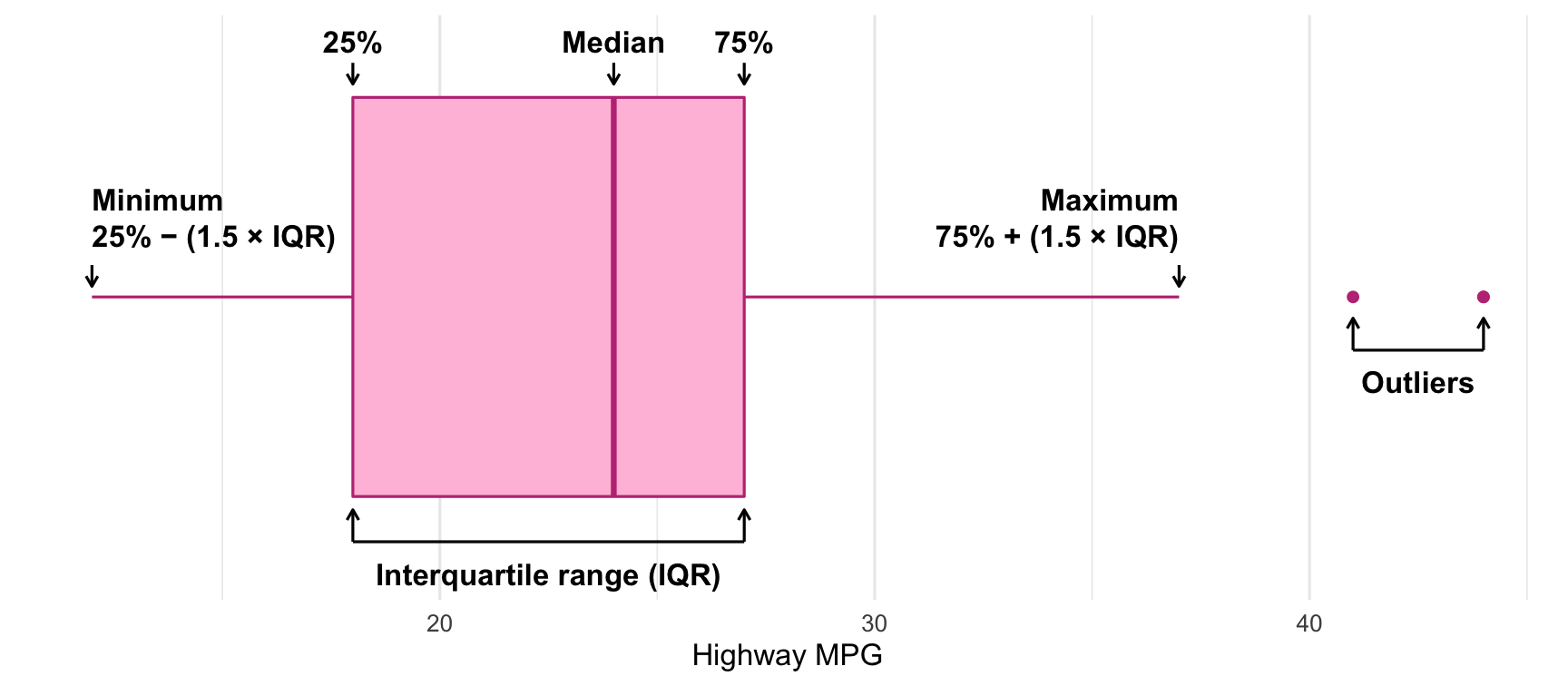
Box plots
Show specific distributional numbers
Five number summary
Bar plots
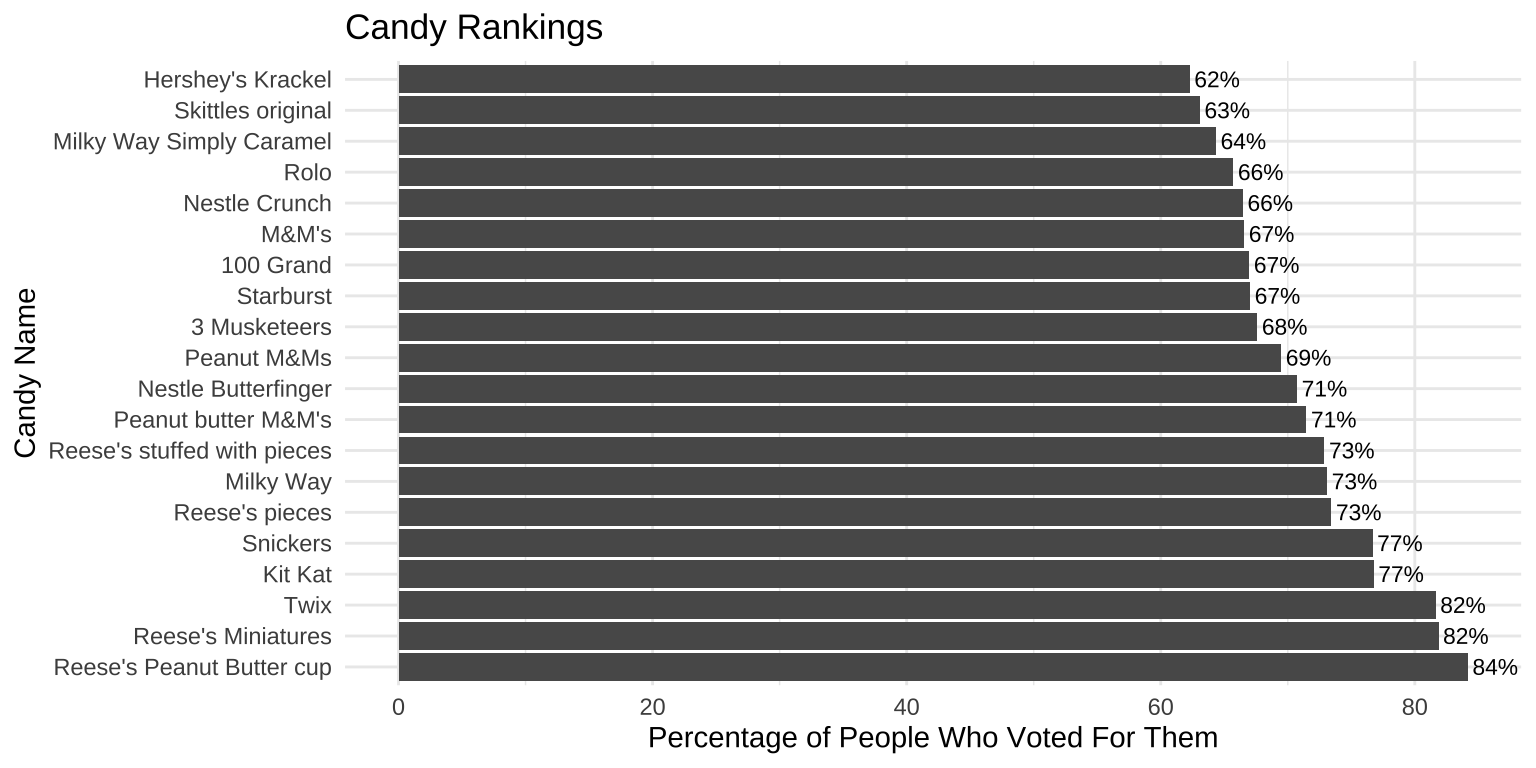
Exploring quantitative variables
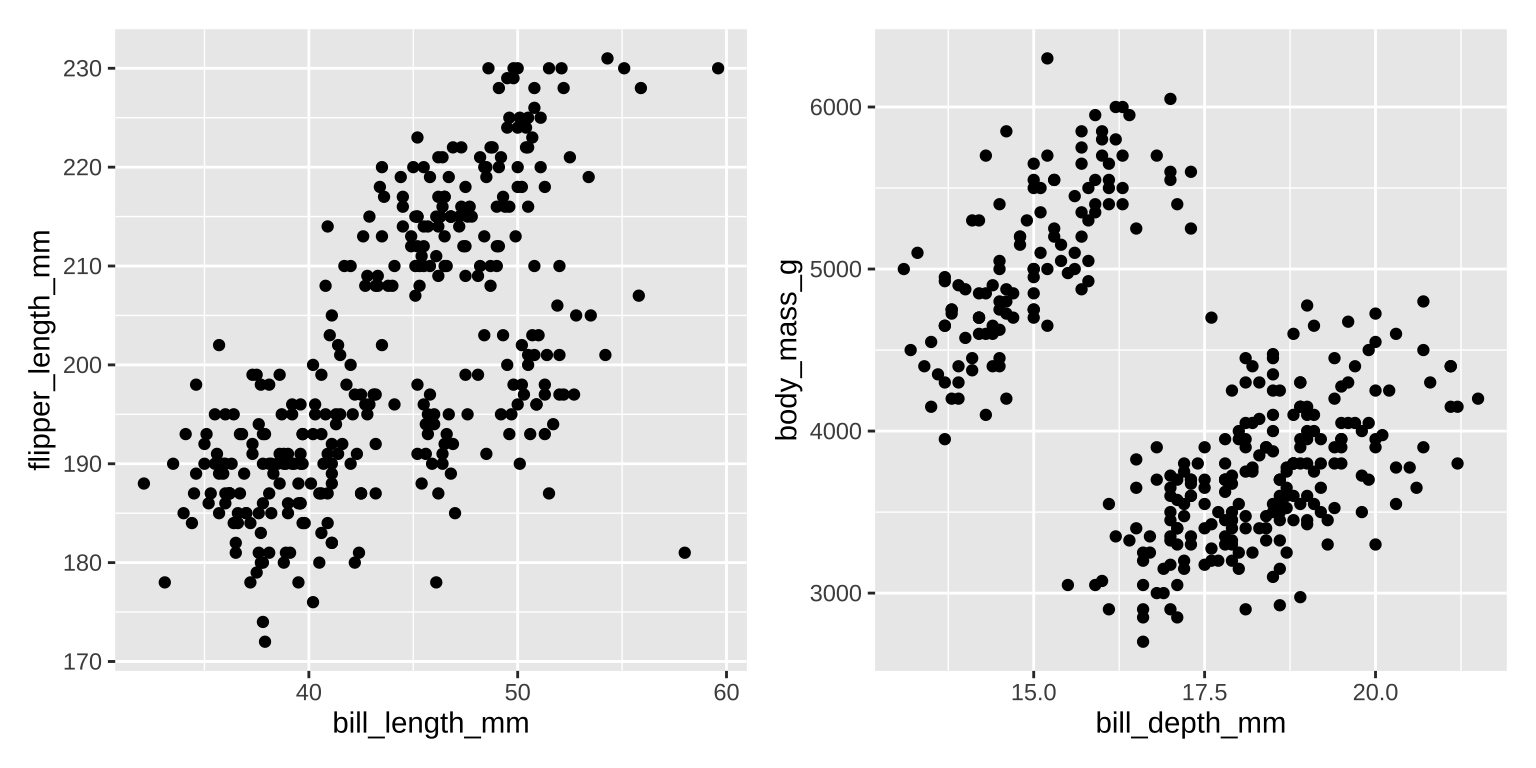
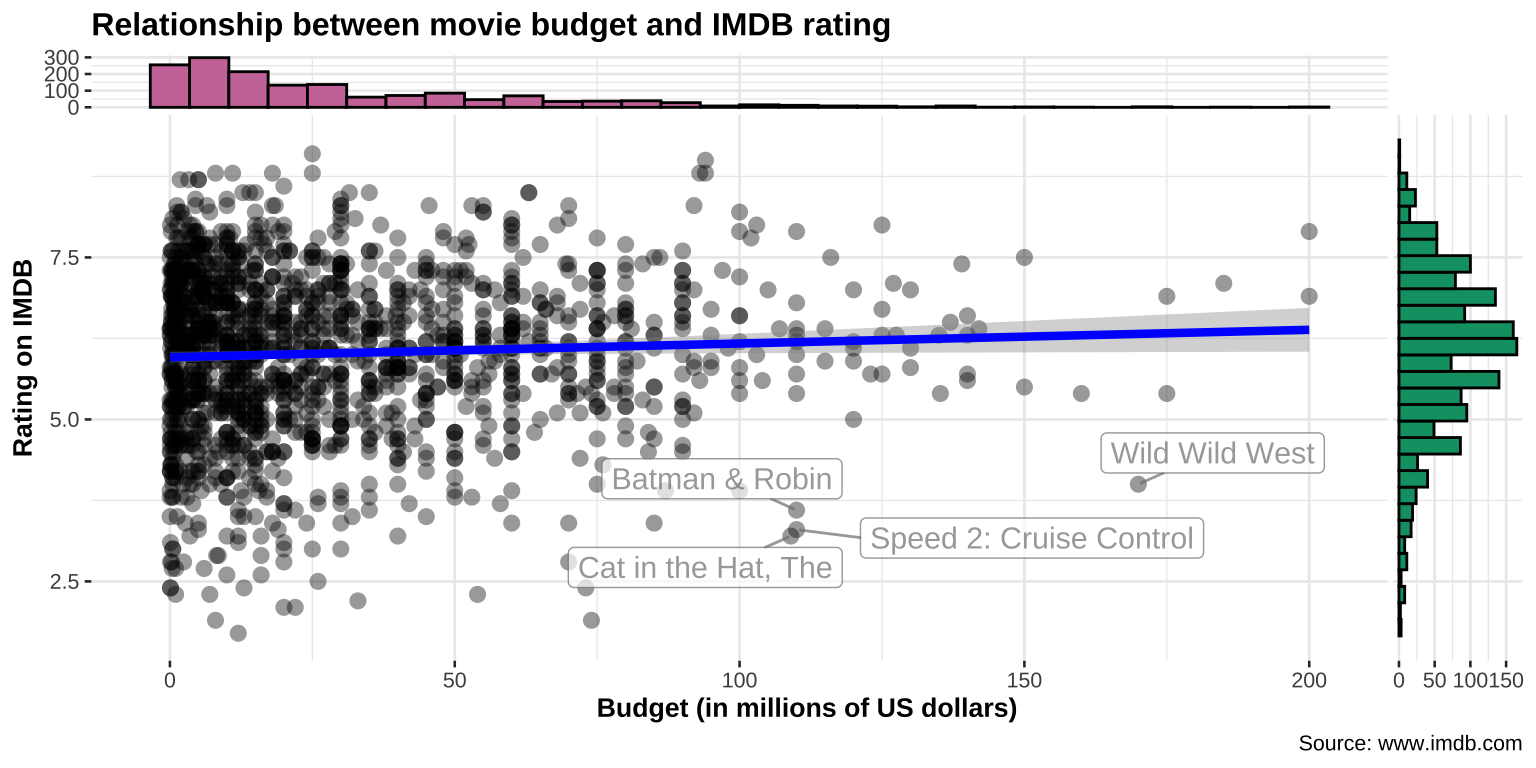
Scatter plots
![]()
![]()
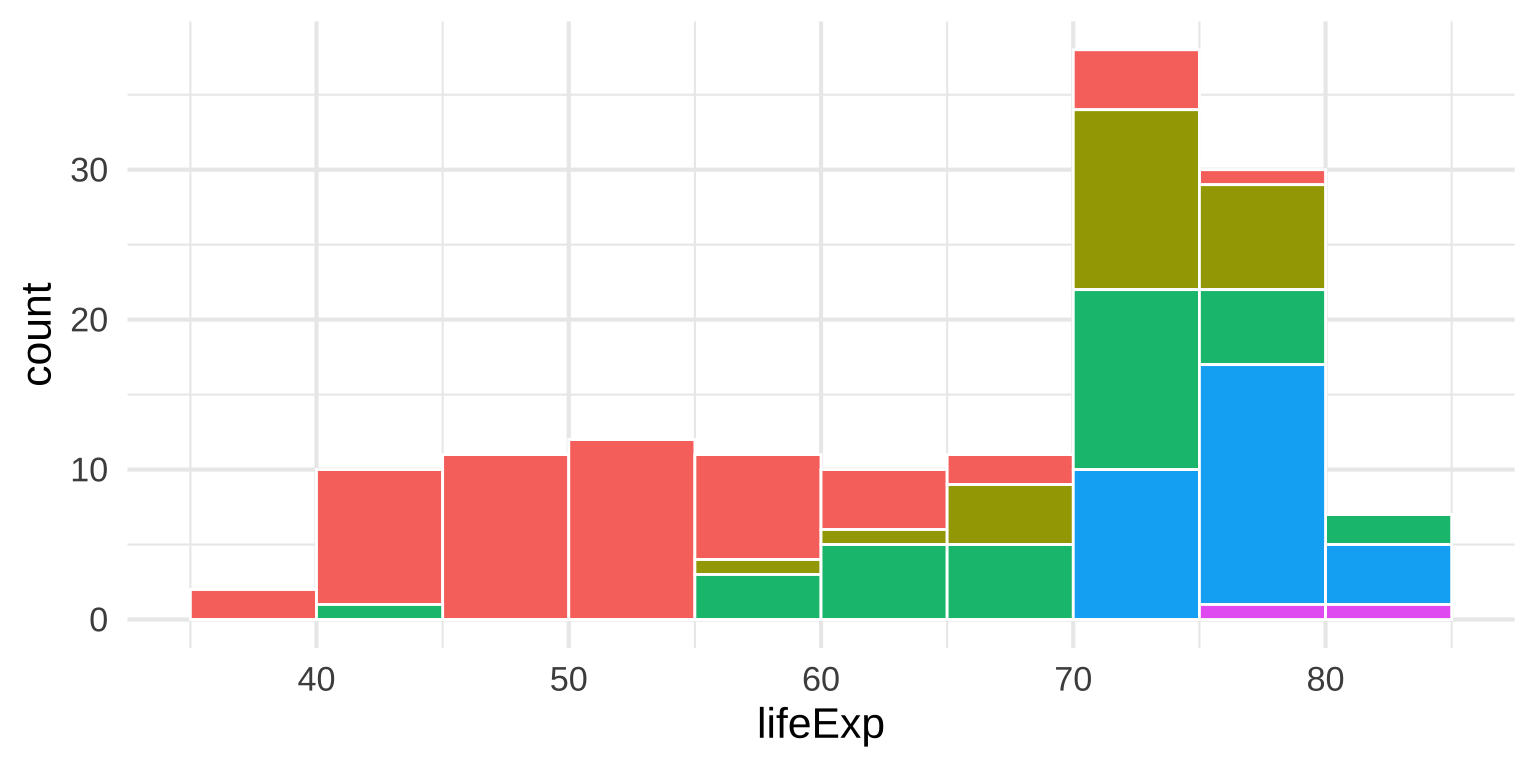
Multiple histograms
- This looks bad and is hard to read
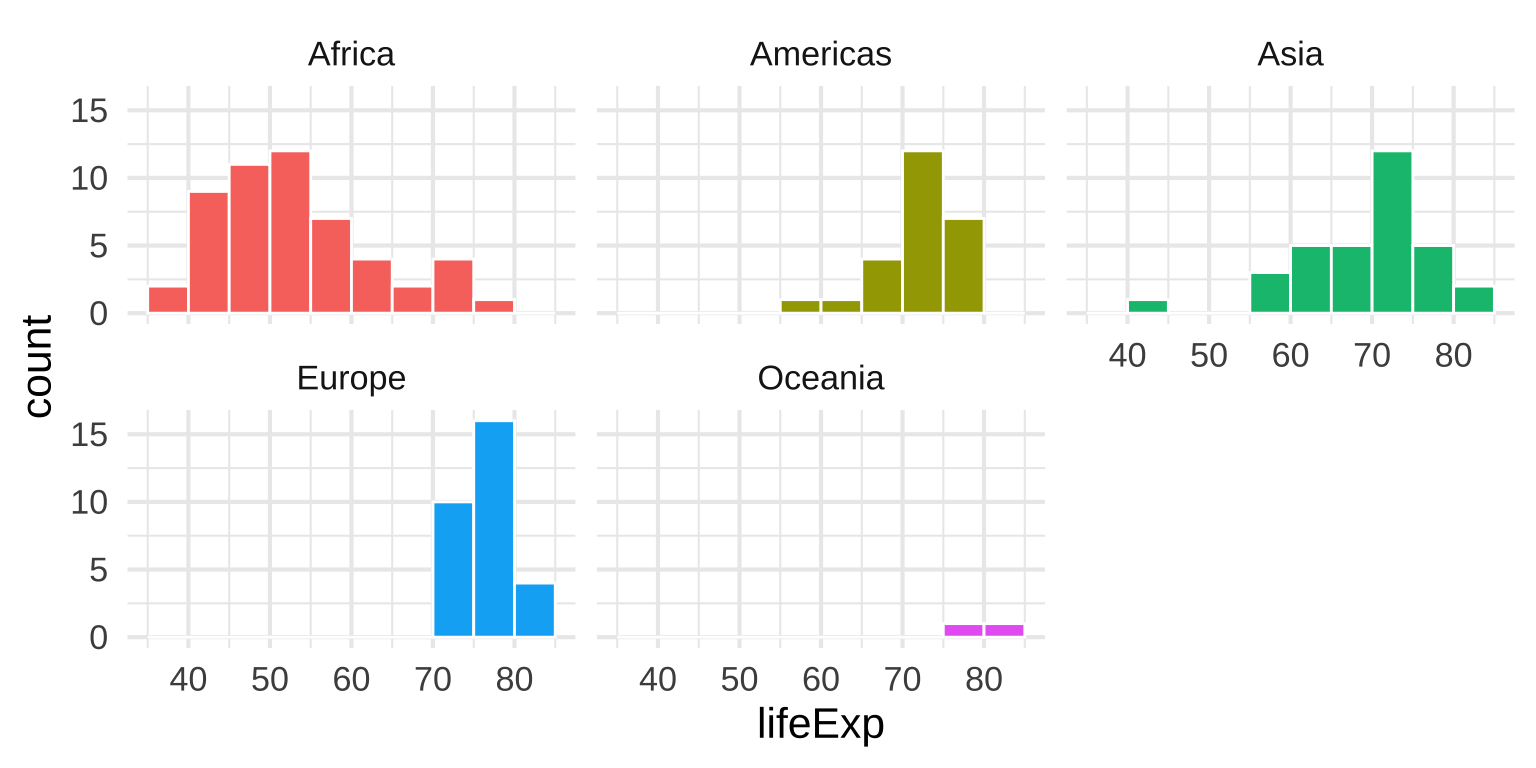
Multiple histograms
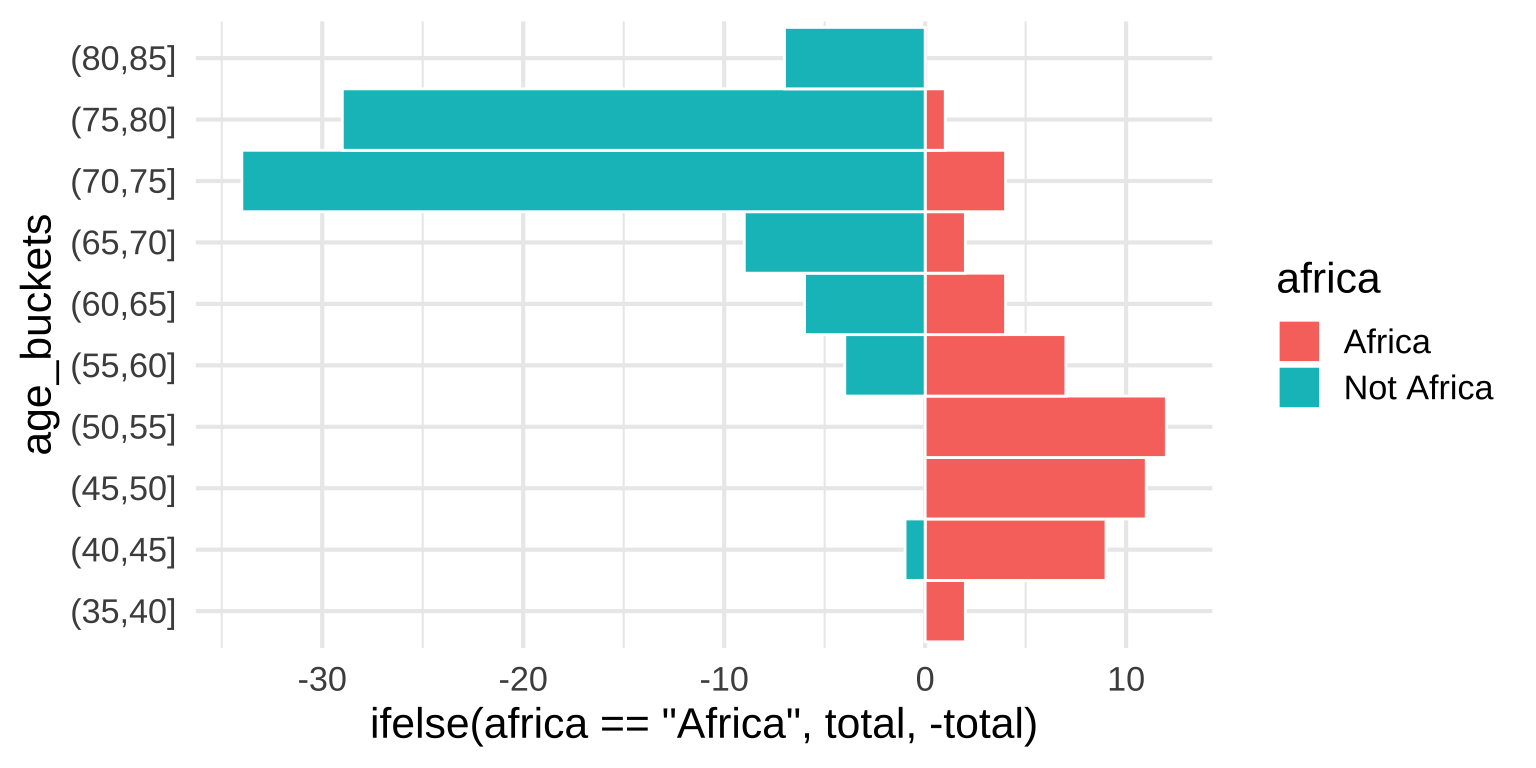
Pyramid histograms
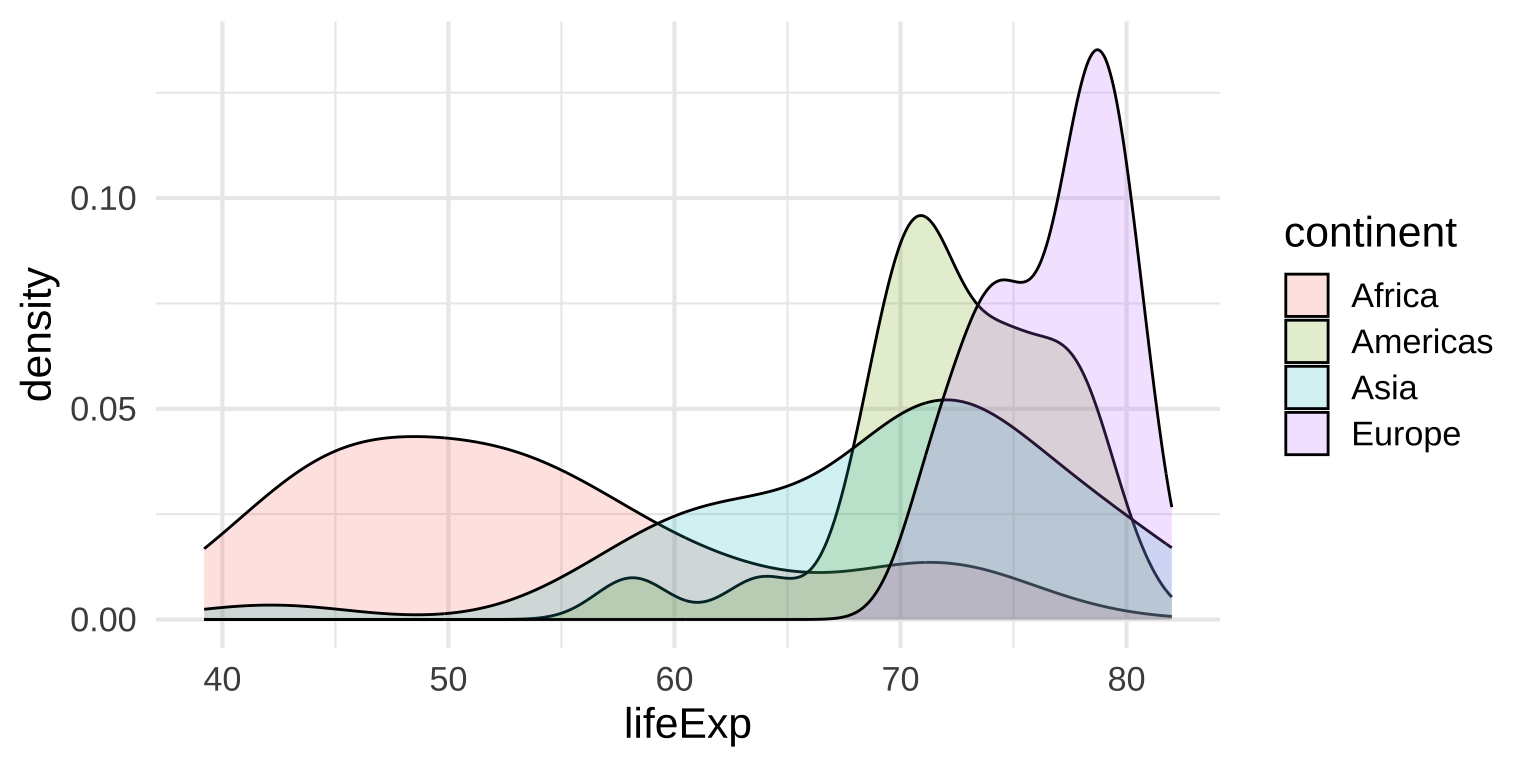
Multiple densities: Transparency
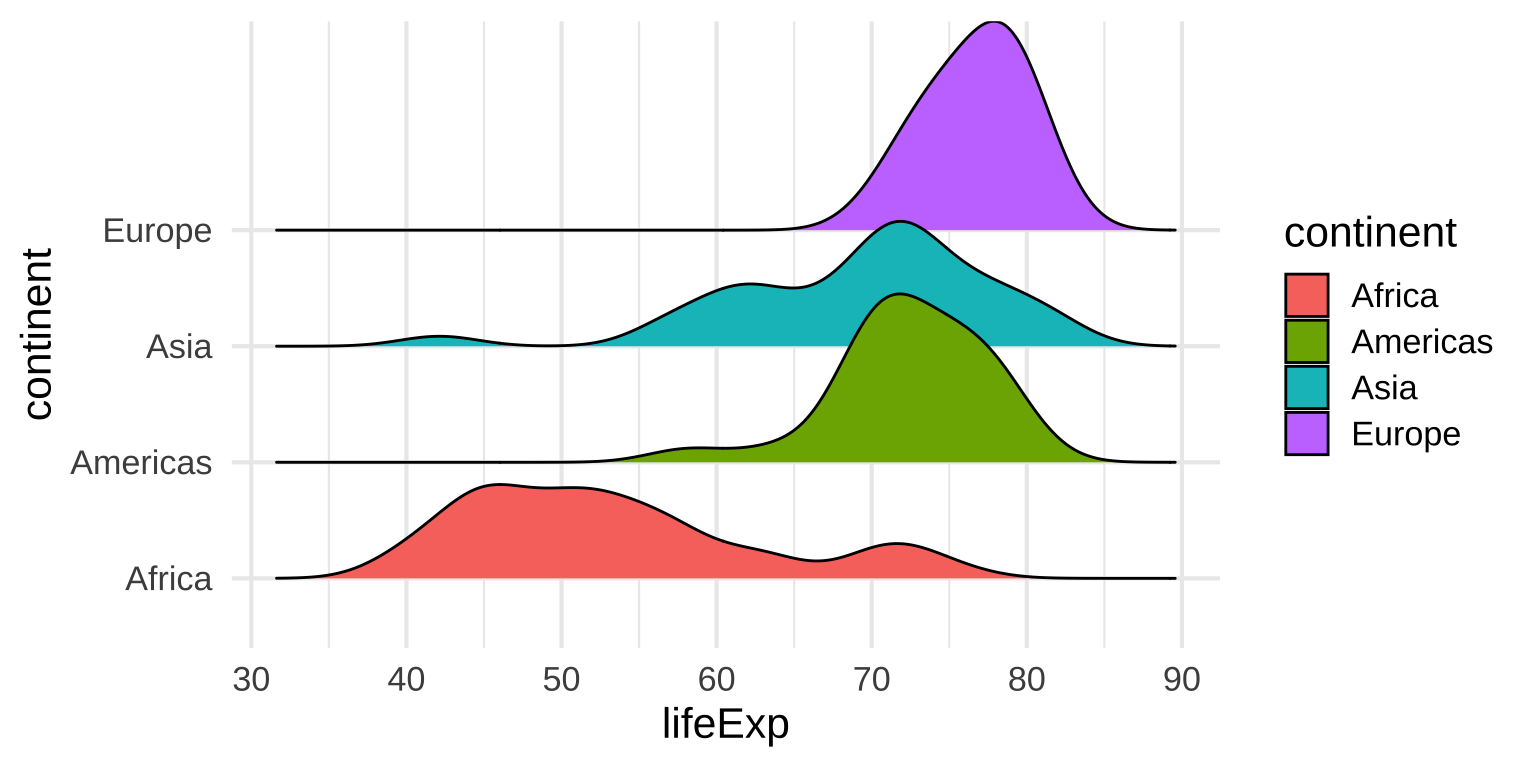
Multiple densities: Ridge plots
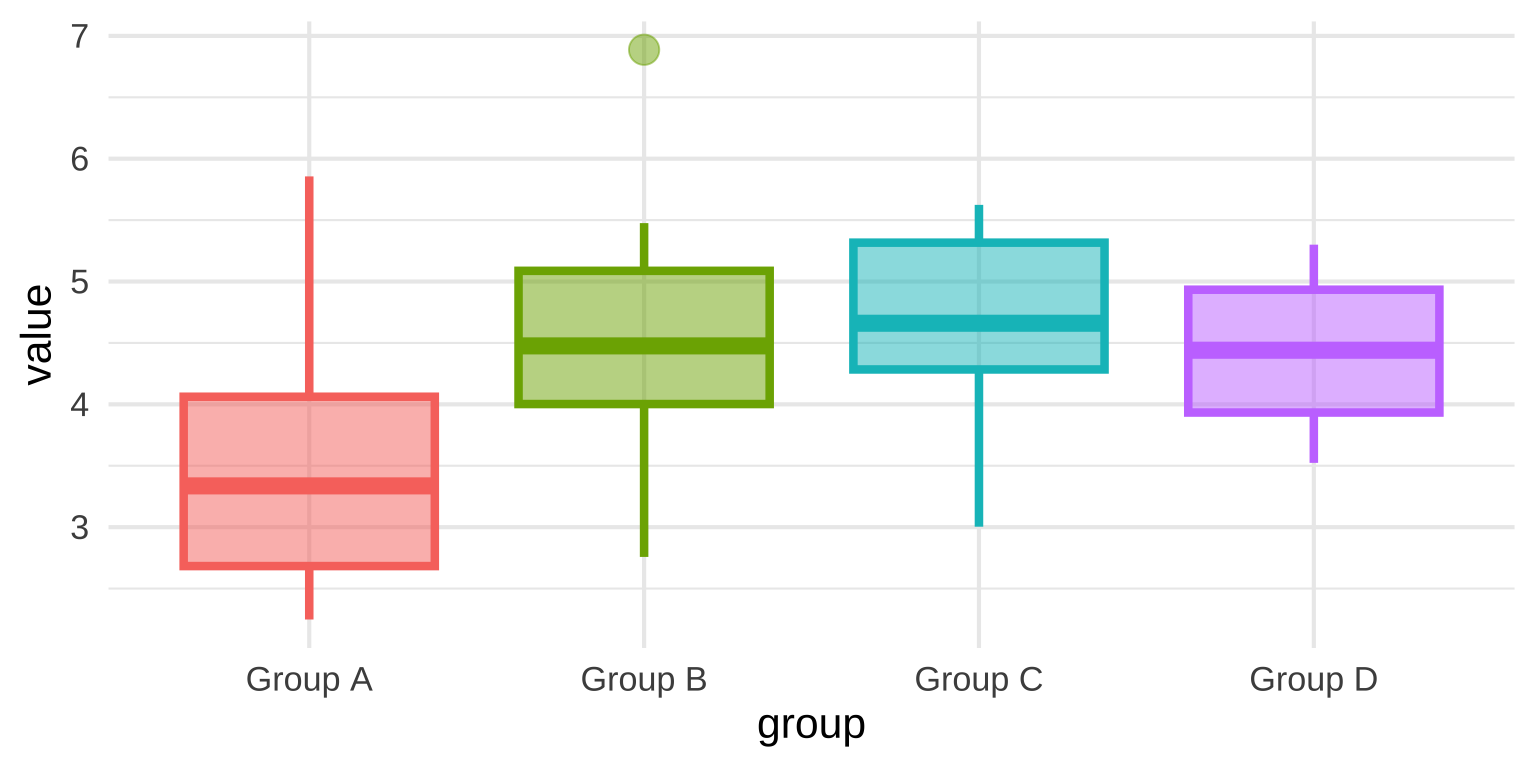
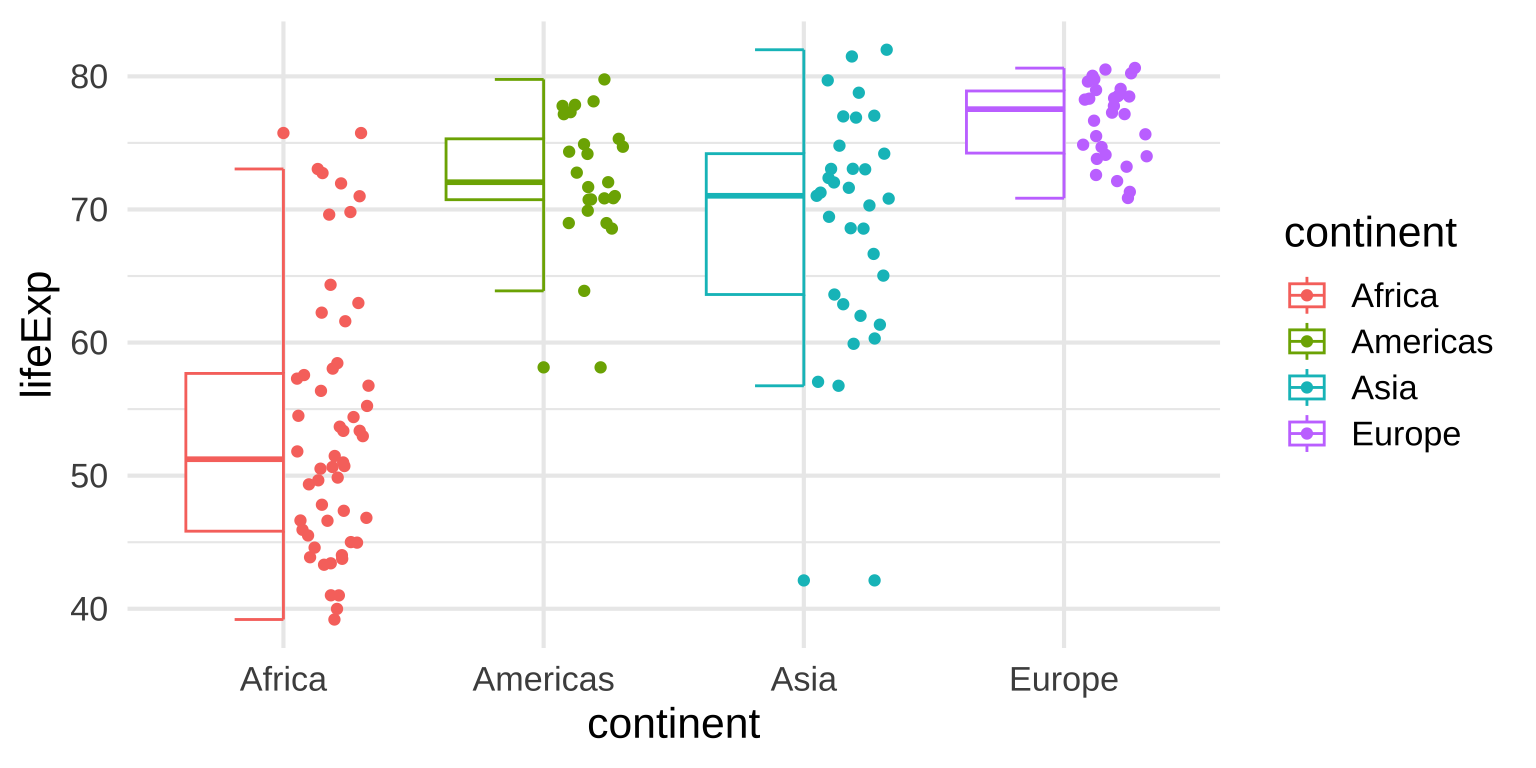
Multiple Box plots
- Boxplots
Violin plots
Density plot rotated 90 degrees and mirrored
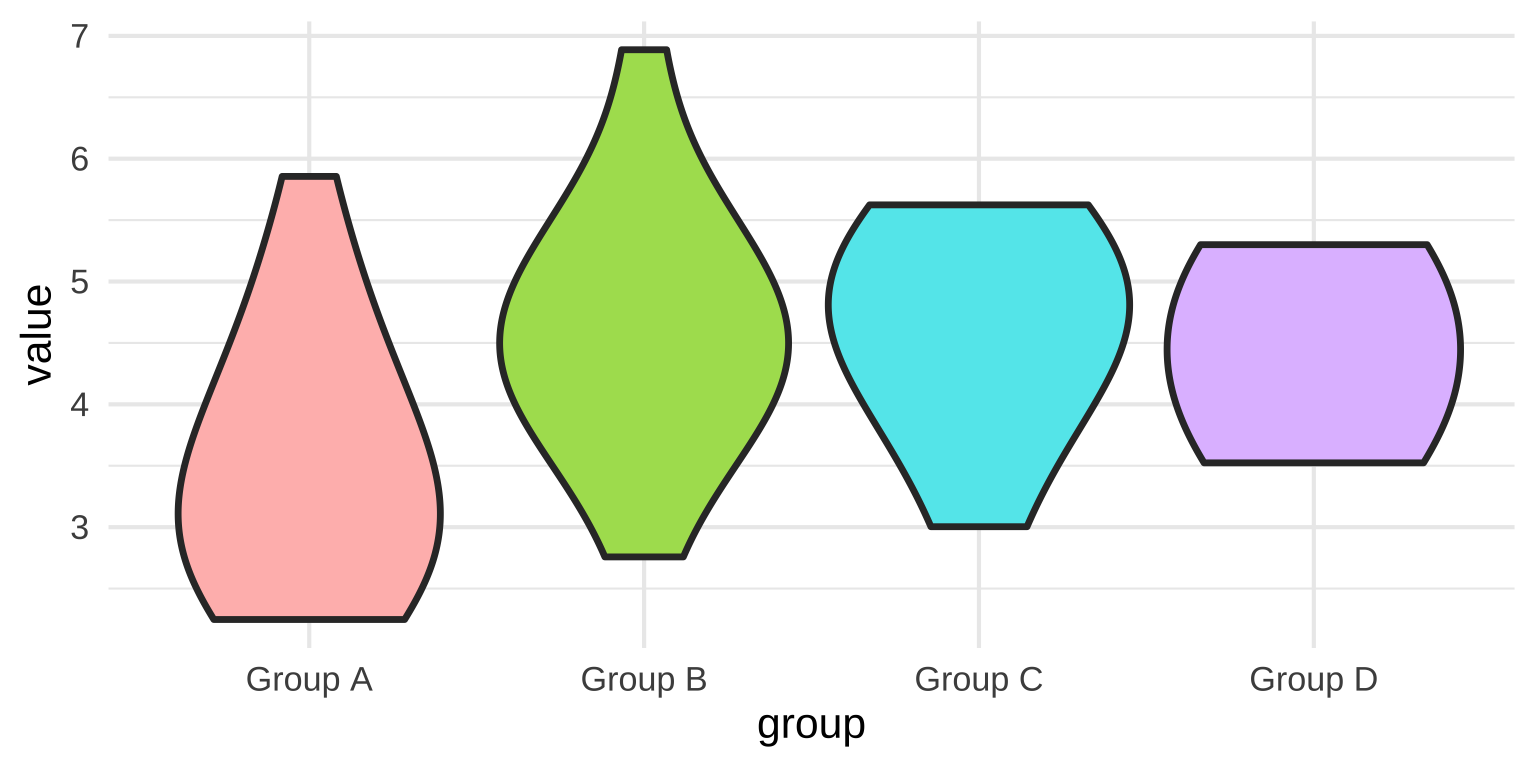
Half violin plots + Box
# Create the plot
ggplot(data, aes(x = group, y = value, fill=group)) +
# Half violin plot with ggdist
stat_halfeye()+
# Distributional boxplot (similar to standard boxplot but with more flexibility)
geom_boxplot(width = 0.1, outlier.shape = NA, fill = "white")+
theme_minimal(base_size = 16) +
theme(legend.position = "none")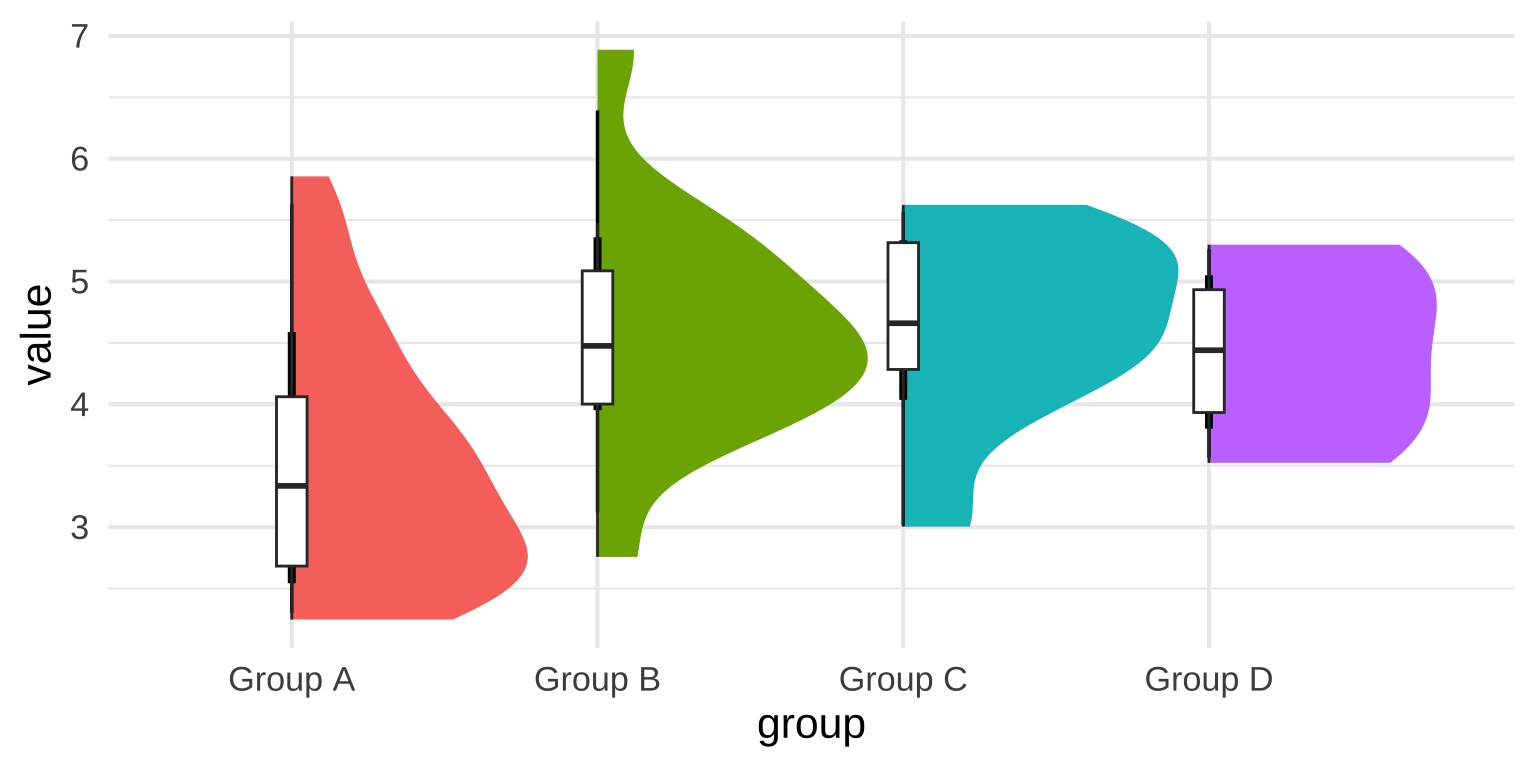
Strip plots
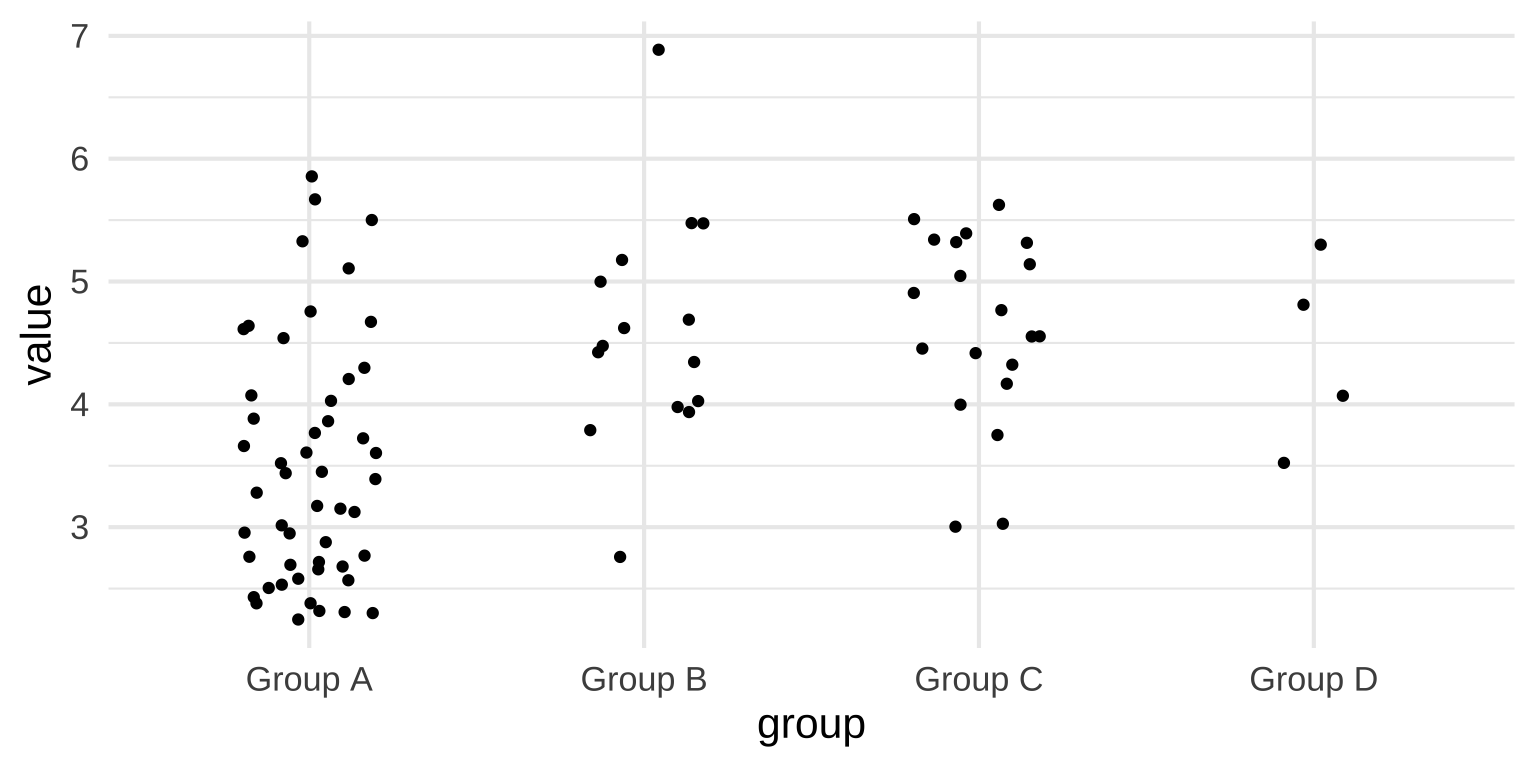
Strip plots
Add summary stats
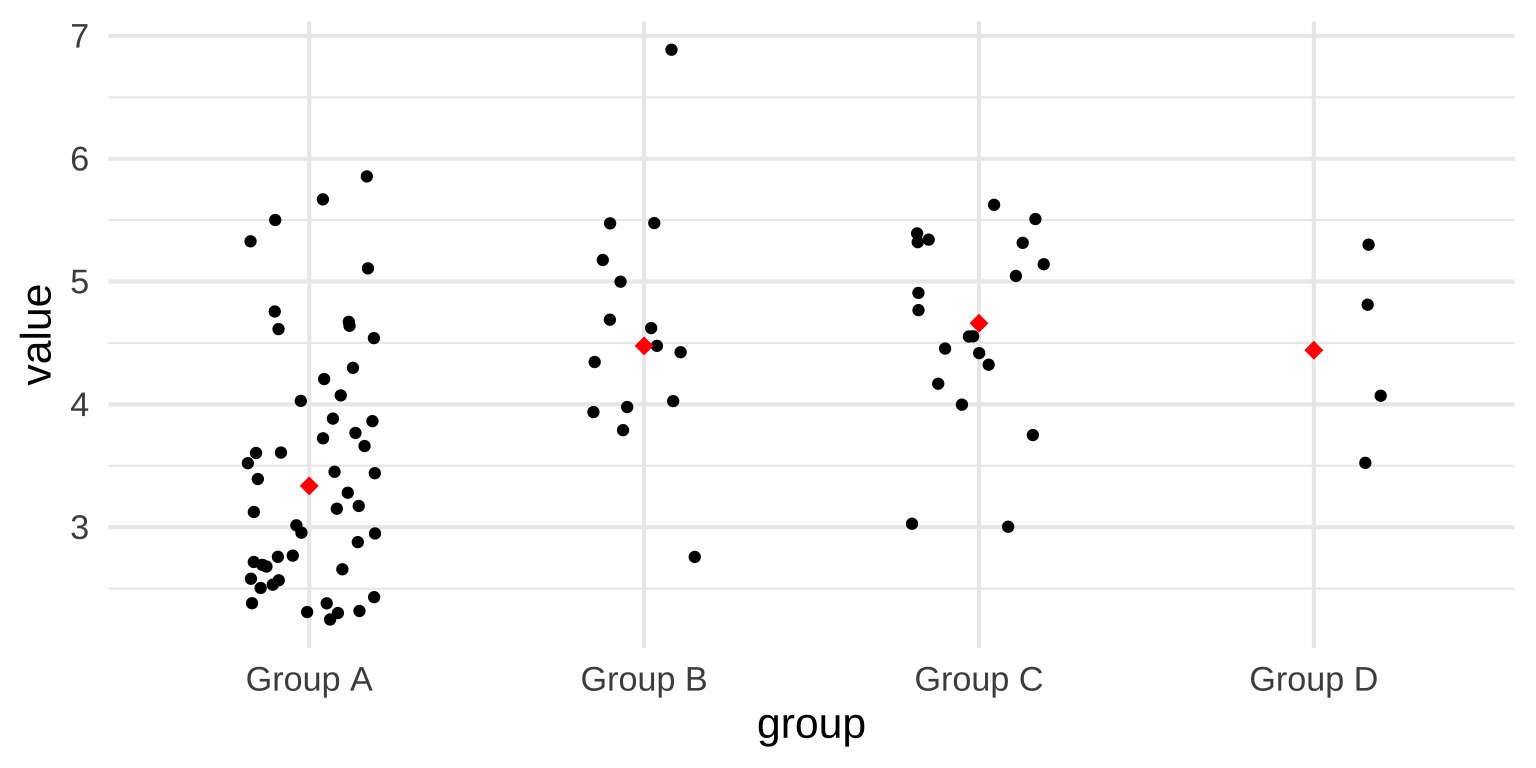
Raincloud plots

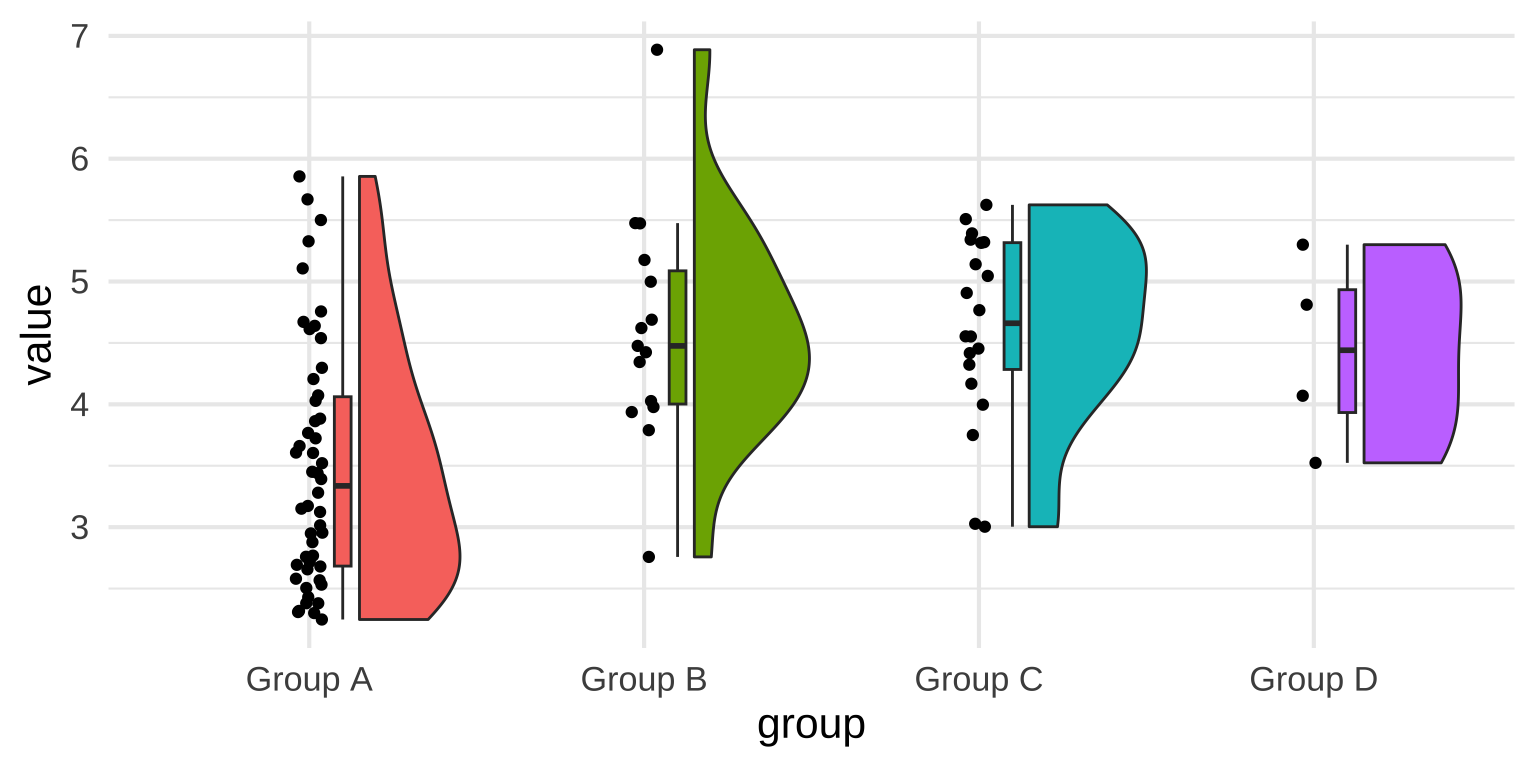
Raincloud Plots
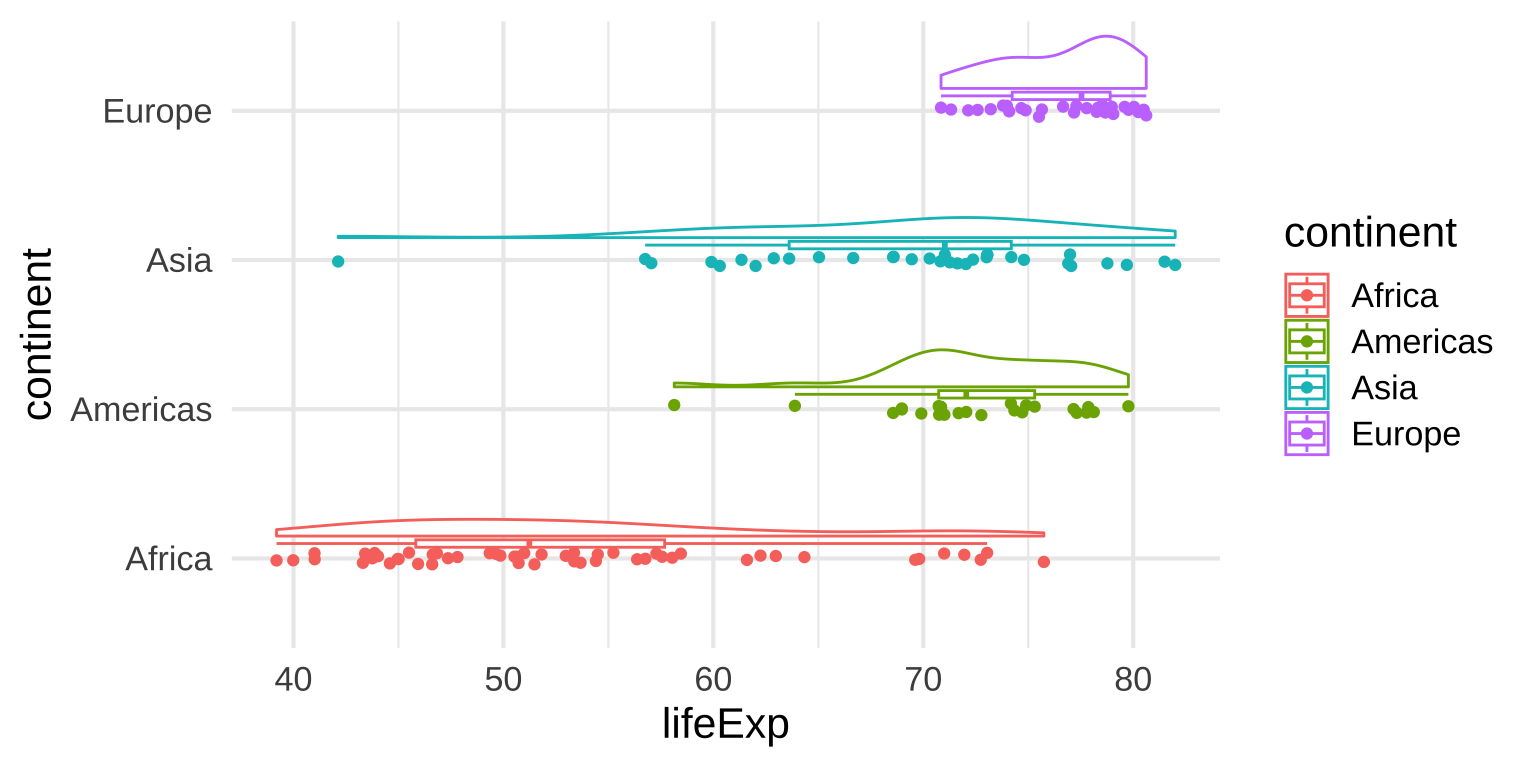
Multiple Geoms
Categorical vs. Categorical
Stacked bar plots
![]()