Monsters, Models, and Normal Distributions
Princeton University
Packages
Outline
Thinking about models
The normal distribution
Z-scores
- How to compute Z-scores
- Z-score practice
- How to compute Z-scores
What is a statistical model?
- Statistical modeling = “making models of distributions”
What is a model?
Models are simplifications of things in the real world

What is a model?
Distributions
Basic Structure of a Model
\[data = model + error\]
Data
Model
Use our model to predict the value of the data for any given observation:
\[\widehat{data_i} = model_i\]
Error (predicted - observed)
\[error_i = data_i - \widehat{data_i}\]
The “hat” over the data denotes that it’s our prediction rather than the actual value of the data.This means that the predicted value of the data for observation is equal to the value of the model for that observation. Once we have a prediction from the model, we can then compute the error:
That is, the error for any observation is the difference between the observed value of the data and the predicted value of the data from the model.
Models as Monsters
- The Golem of Prague
- The golem was a powerful clay robot
- Brought to life by writing emet (“truth”) on its forehead
- Obeyed commands literally
- Powerful, but no wisdom
- In some versions, Rabbi Judah Loew ben Bezalel built a golem to protect
- But he lost control, causing innocent deaths

Statistical golems
- Statistical (and scientific) models are our golems
- We build them from basic parts
- They are powerful—we can use them to understand the world and make predictions
- They are animated by “truth” (data), but they themselves are neither true nor false
- The model describes the golem, not the world
- The model doesn’t describe the world or tell us what scientific conclusion to draw—that’s on us
- We need to be careful about how we build, interpret, and apply models
Choosing a Statistical Model
- Cookbook approach
- Do Smarties make us smarties?
- Take 200 7-year-olds
- Randomly assign to 2 groups
- Control: Normal breakfast
- Treatment: Normal breakfast + 1 packet of Smarties
- Outcome: Age-appropriate general reasoning test
- Randomly assign to 2 groups
- Take 200 7-year-olds
- What statistical analysis do I run?
- Do Smarties make us smarties?
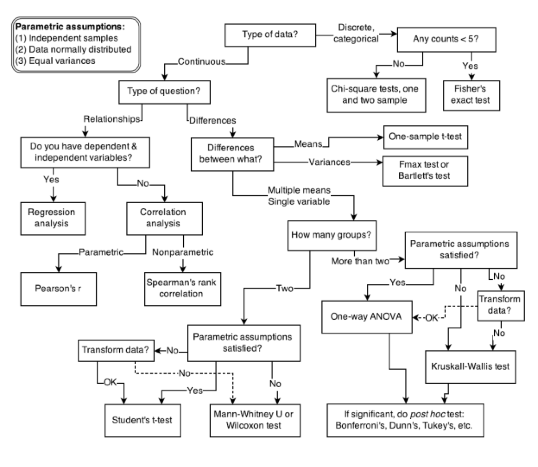
Choosing a Statistical Model
Cookbook approach
Every one of these tests is the same model
The general linear model (GLM)
- The cookbook approach makes it hard to think clearly about relationship between our question and the statistics
The General Linear Model
General mathematical framework
Regression all the way down
Highly flexible
- Can fit qualitative (categorical) and quantitative predictors
Easy to interpret
Helps understand interrelatedness to other models
Easy to build to more complex models
The General Linear Model
Modeling comparison approach
Think in terms of models and not tests
Model is determined by question, not data
What do alternative models say about the world?
Let’s build a model for this experiment
A simple model
- General reasoning scores
A Simple Model: Data
Building a Model - Notation
Small Roman letters
Individual observed data points
\(y_1\), \(y_2\), \(y_3\), \(y_4\), …, \(y_n\)
- The scores for person 1, person 2, person 3, etc.
\(y_i\)
- The score for the “ith” person
Big Roman letters
A “random variable”
The model for data we could observe, but haven’t yet
\(Y_1\)
- The model for person 1
- The yet-to-be-observed score of person 1
Building a Model - Notation
Greek letters
Population parameters
Unobservable parameters
μ
mu
- “mew” - Used to describe means
σ
Sigma
Used to describe a standard deviation

Building a Model - Notation
Roman letters
Sample specific statistics
\(\bar{X}\) - sample mean
s - standard deviation from the sample
Data estimates
\(b_0\)
\(e\)
A simple model
- Null or empty model
\[ Y_i = \beta_0 + \epsilon \]
\[ Y_i= b_0 + e \]
- Makes the same prediction for each observation
Figuring out \(b_0\)
- Goal of any model is to find an estimator that minimizes the error
- How we define error will determine the best estimator
Types of Errors
Count of Errors
- It simply counts the number of instances where the prediction was incorrect \[\text{Count} = \sum_{i=1}^{n} I(y_i \neq \hat{y}_i)\]
- Mode is best estimate for \(b_0\)
Sum of errors (residuals)
- The sum of the differences between observed values and predicted values. In an ideal case with no bias, this would be zero.
\[SE = \sum_{i=1}^{n} (y_i - \hat{y}_i)\]
Sum of absolute errors
- Measures the total absolute difference between observed and predicted values. It gives a sense of the average magnitude of errors without considering direction
\[SAE = \sum_{i=1}^{n} |y_i - \hat{y}_i|\]
- Median is best estimate for \(b_0\)
Sum of squares (SS)
This measures the total squared difference between observed and predicted values
Most commonly used in regression analysis (what we will be using)
\[SS = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\]
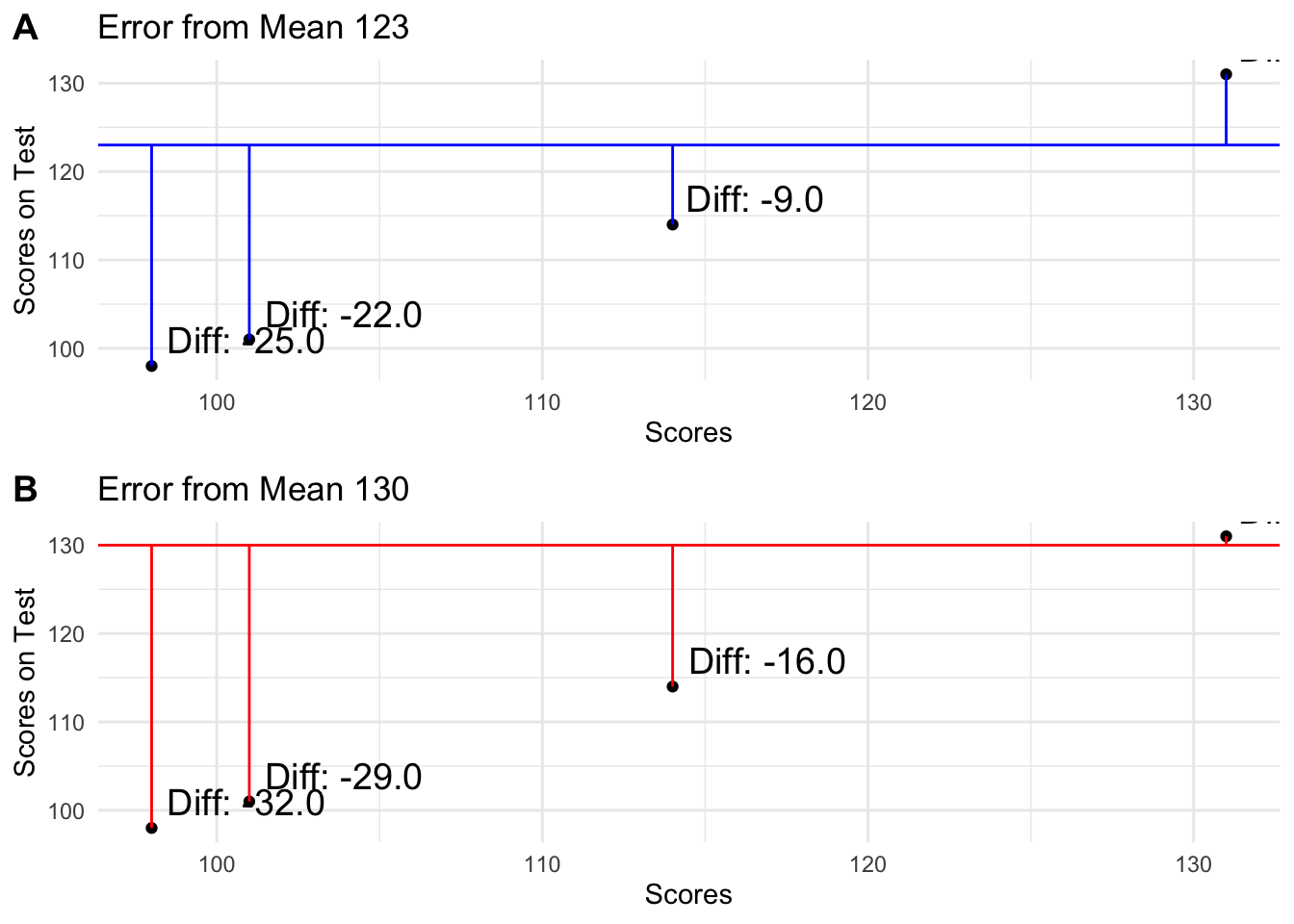
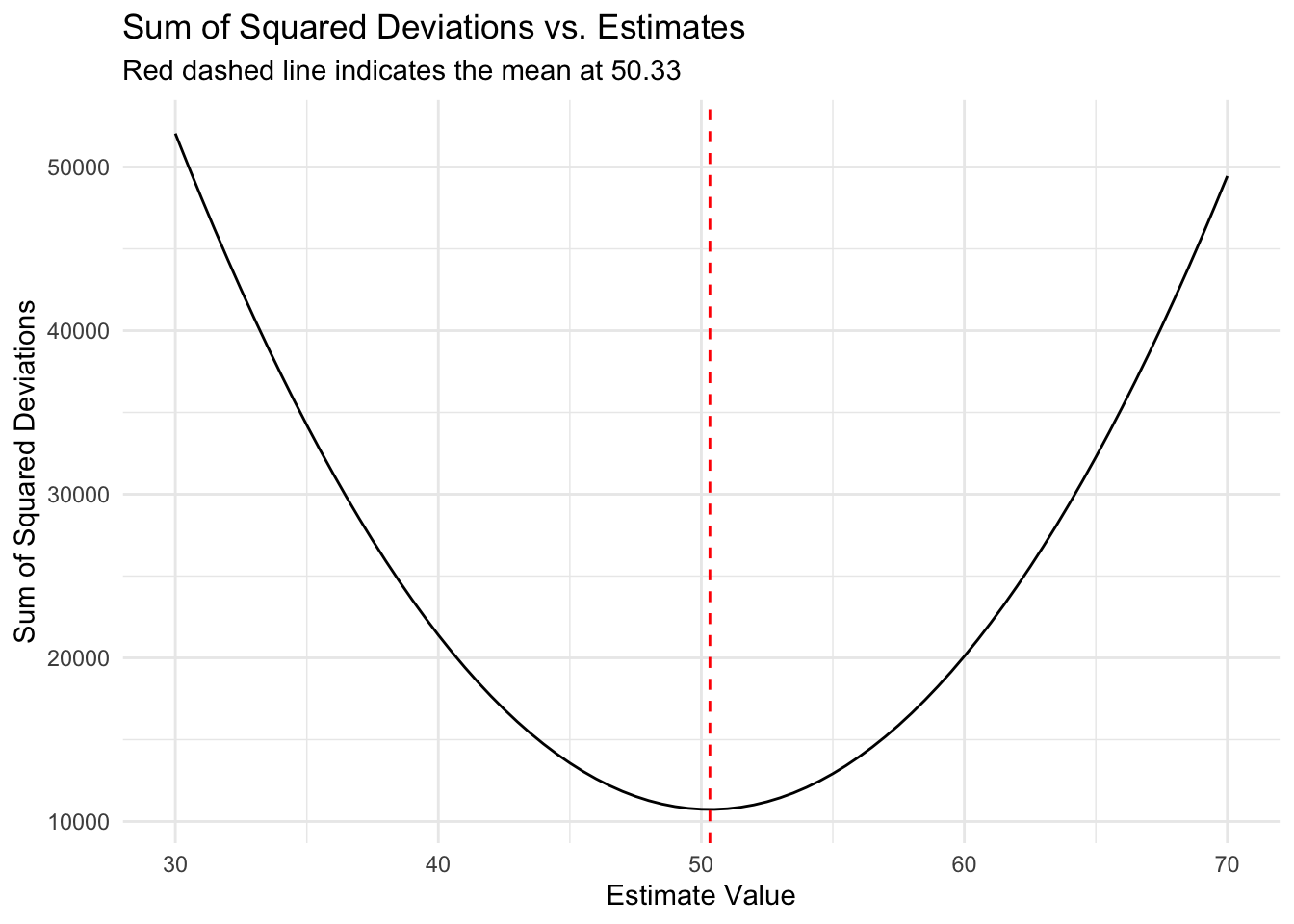
The mean
Mean is the best estimator of \(b_0\)
\[\frac{1}{n} \sum_{i=i}^{n} x_{i}\]
Mean has really nice proprieties\[SR = \sum_{i=1}^{n} (y_i - \hat{y}_i)\]
- SSR minimized at mean
SSR minimized at mean
Describing error
We should have some overall description of the accuracy of model’s predictions
SSR
Standard deviation
\[ s^2 = \text{MSE} = \frac{1}{n-p} \sum_{i=1}^{n} (Y_i - \hat{Y}_i)^2 \]
\[ \text{SD} = \sqrt{\text{MSE}} \]
Statistical Modeling: An Example
- Let’s look at general reasoning scores
Building a model - concrete example
Building a Model - Concrete example
\[ \hat{scores} = b_0 + e \]
- What is the overall mean of the dataset?
Building a Model - Concrete example
lmfunction in R can fit an empty model
- \(b_0\) = Intercept = Estimate = Mean
Building a Model - Concrete example
broomis a helper package that provides us with lots of useful functions to get things like residuals, predicted values, etc)
Building a model - Concrete example
- Can get SS a few different ways
Building a model - Concrete

Building a model - Concrete example
Building a model - concrete example
- Mean squared error (MSE)
Building a model - Concrete example
- Predictions from the model
A More Complex Model
- Do you think the empty model is a good model?
. . .
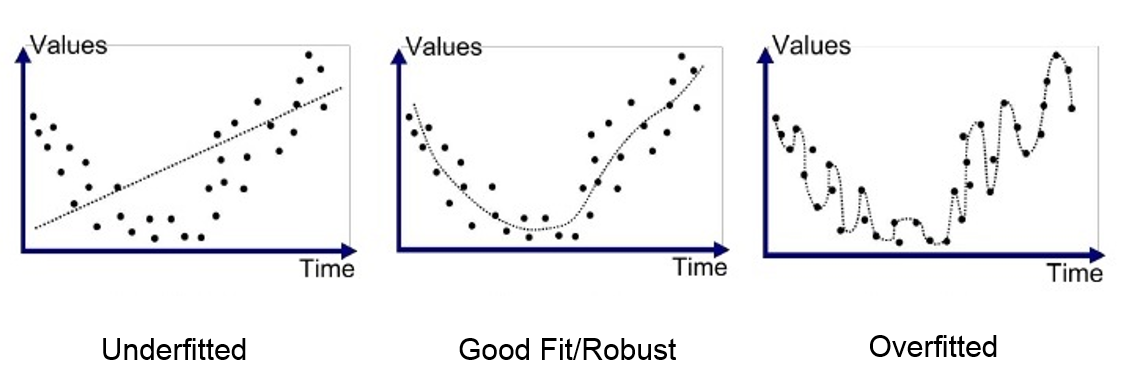
What Makes a Model “Good”
We want it to describe our data well
We want it to generalize to new datasets
- We want error to be as small as possible
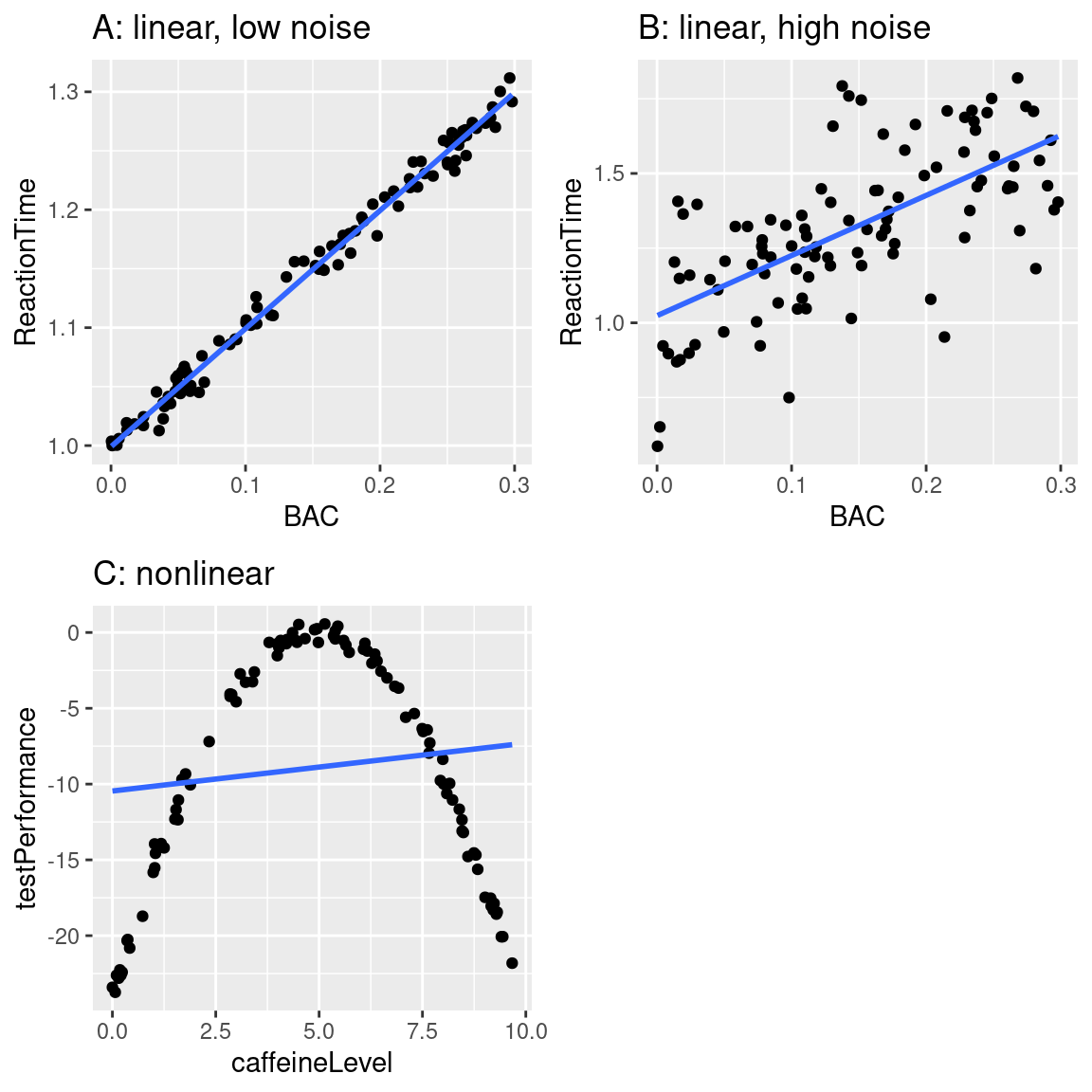
Can a Model Be Too Good?
Yes!
Overfitting
- A model with little to no error will not generalize to new datasets
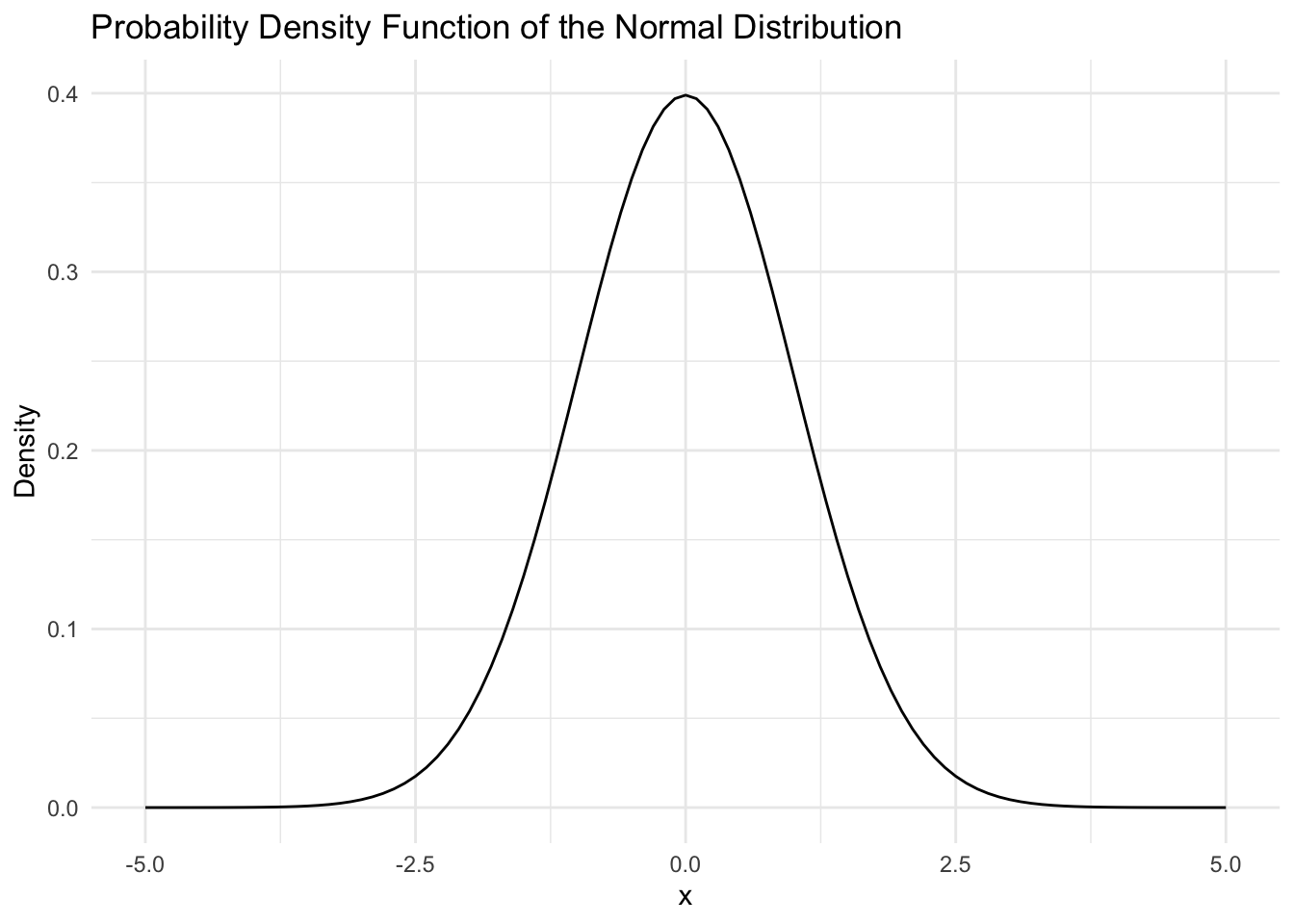
Normal distribution
- Error in linear models is assumed to distributed as normal
\[ \epsilon \sim N(\mu, \sigma) \]
Normal is called a Gaussian distribution
If we assume a variable is at least normally distributed can make many inferences!
Most of the statistical models assume normal distribution
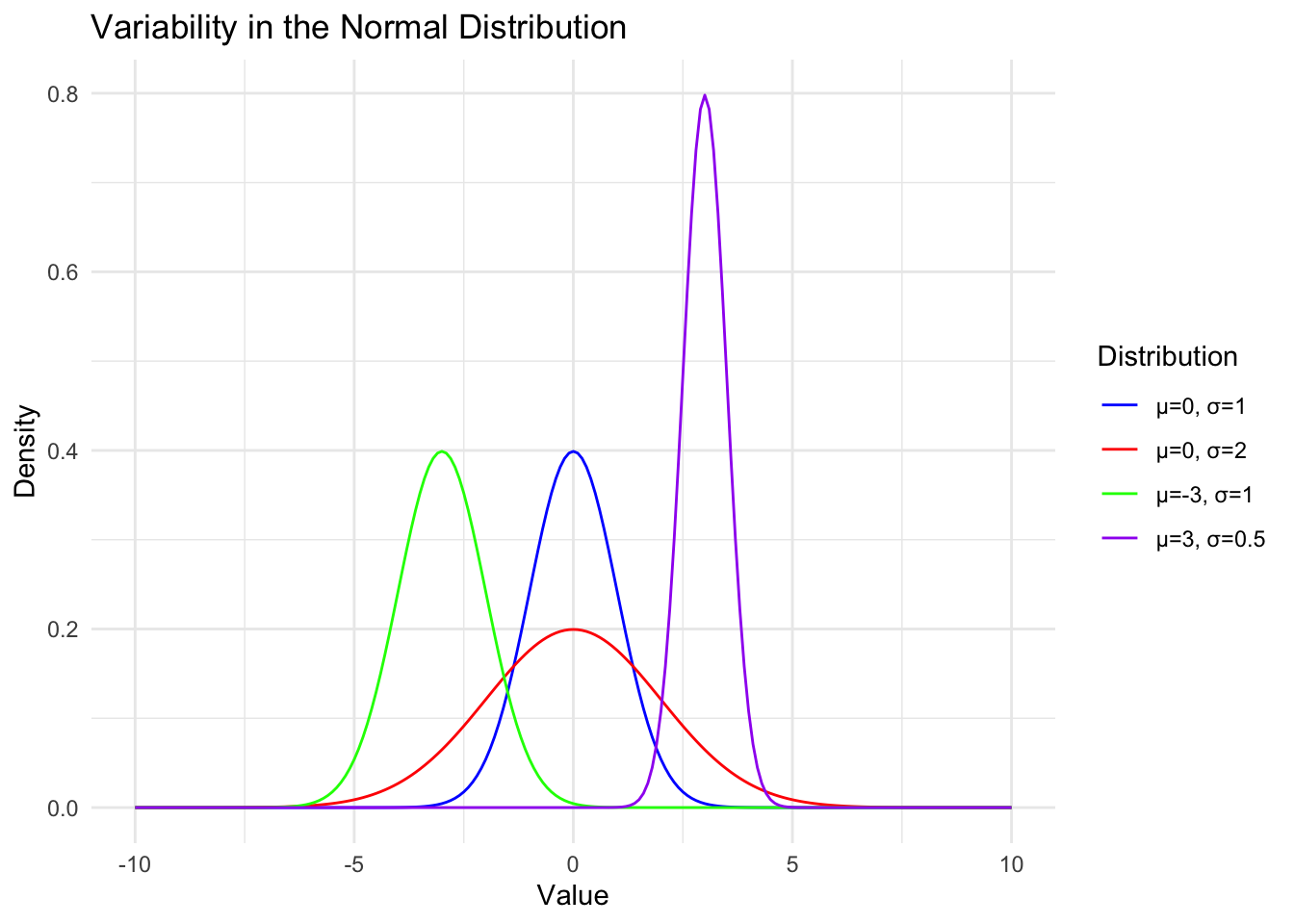
Normal distribution
Normal(μ, σ)
Parameters:
\(\mu\) = Mean
- Mean is the center of the distribution
\(\sigma\) Standard deviation
- Variance is average squared deviation from the mean
- \(\sigma = \sqrt(s^2)\)
- On average, how far is each point from the mean (spread)?
- \(\sigma = \sqrt(s^2)\)
- Variance is average squared deviation from the mean
Building a Model - Normal Distribution
Properties of a normal distribution
- Shape
- Unimodal
- Symmetric
- Asymptotic
- Shape
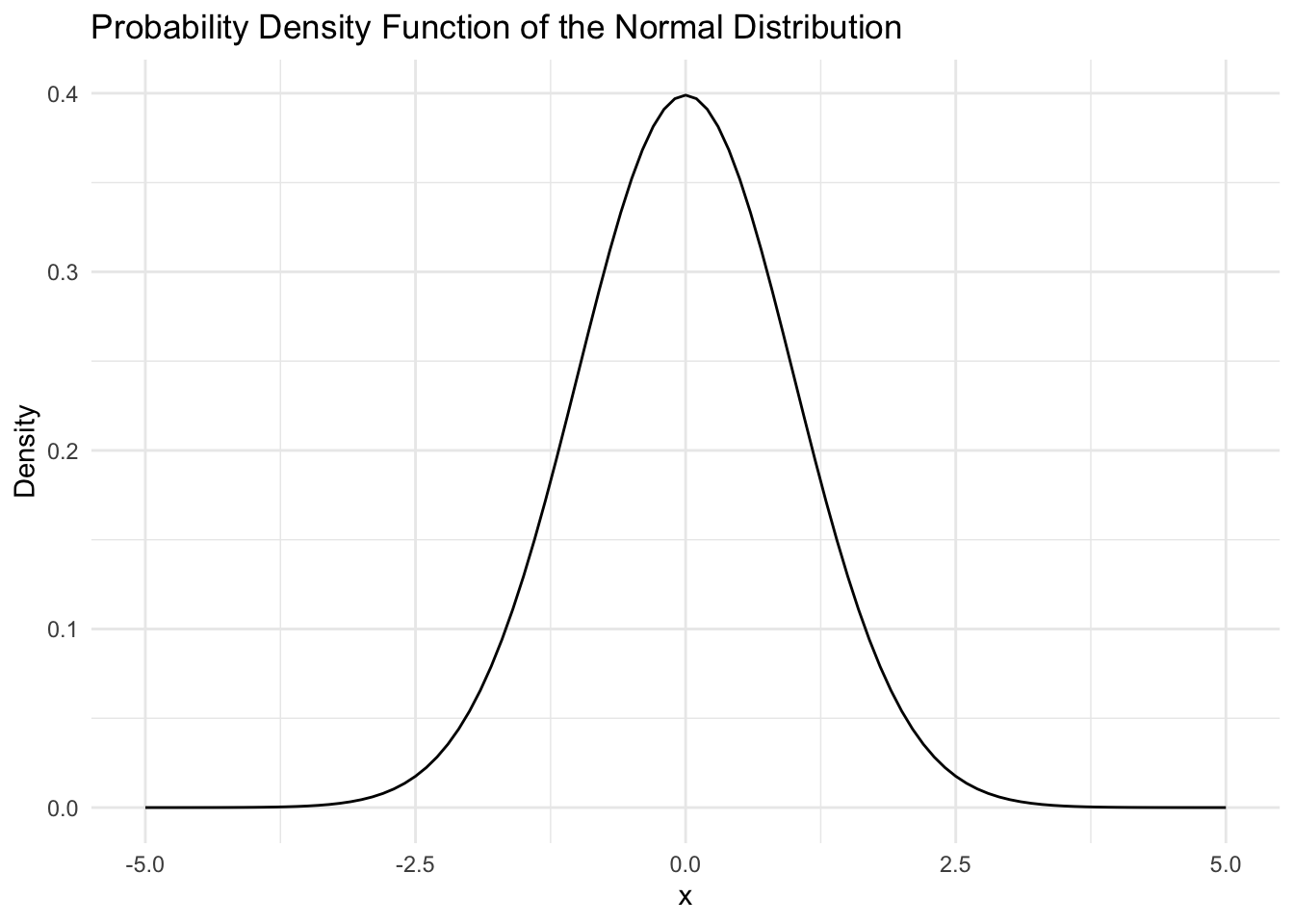
Building a Model - Normal Distribution
- The PDF of a normal distribution is given by:
\(f(x) = \frac{1}{\sqrt{2\pi \sigma}}\exp\left[-\frac{(x-\mu)^2}{2\sigma^2}\right]\)
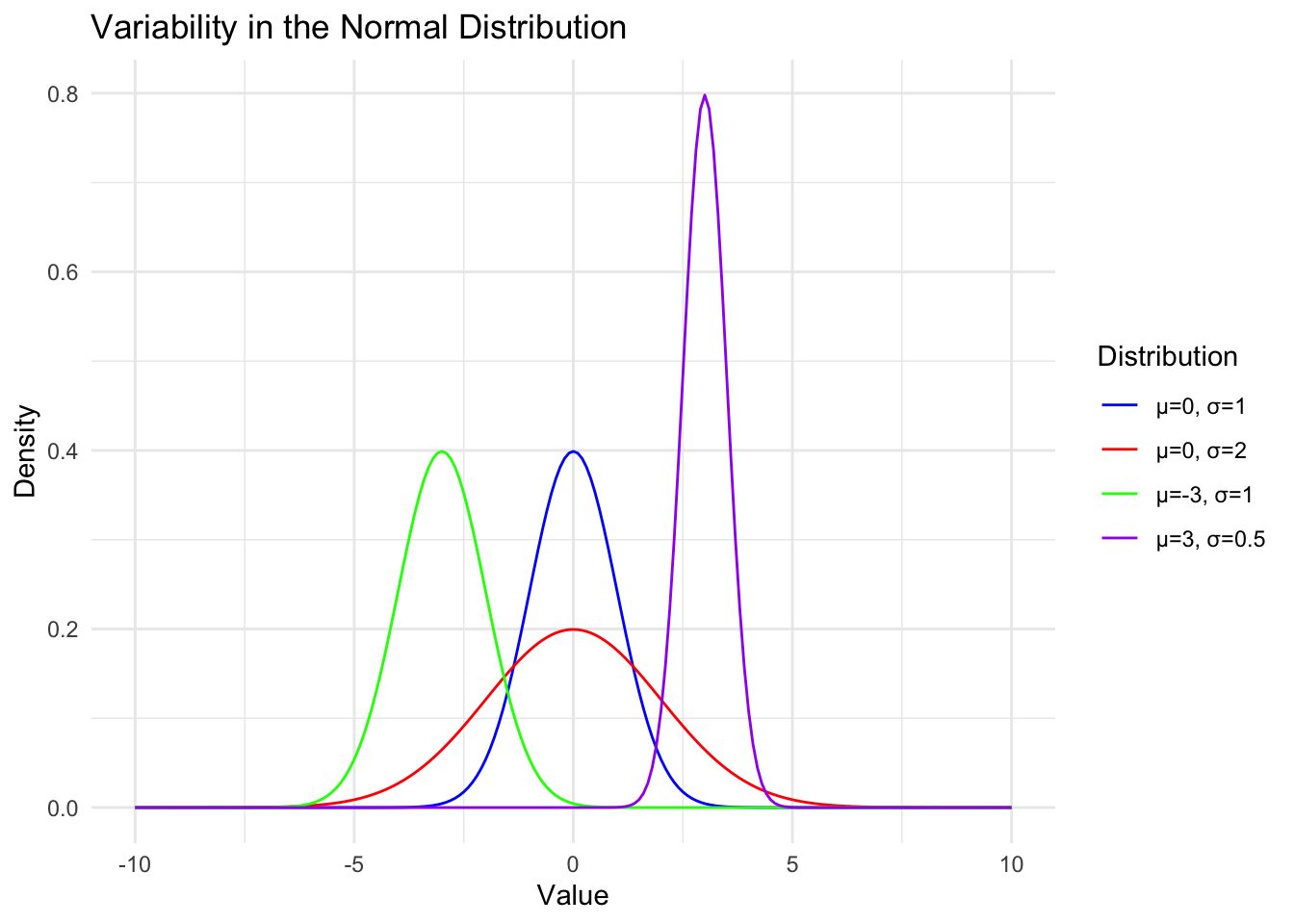
Normal Distribution
- Skew
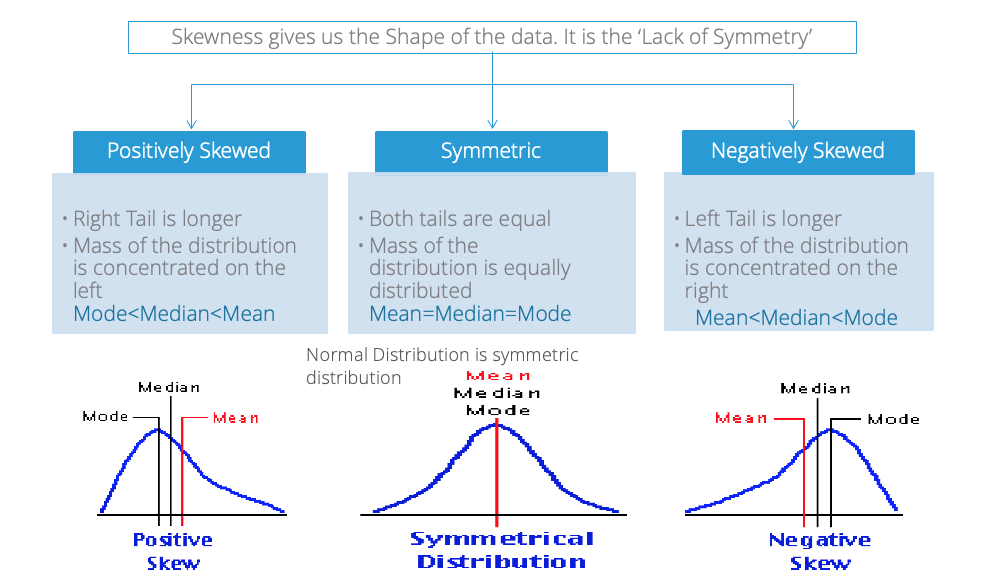
Normal Distribution
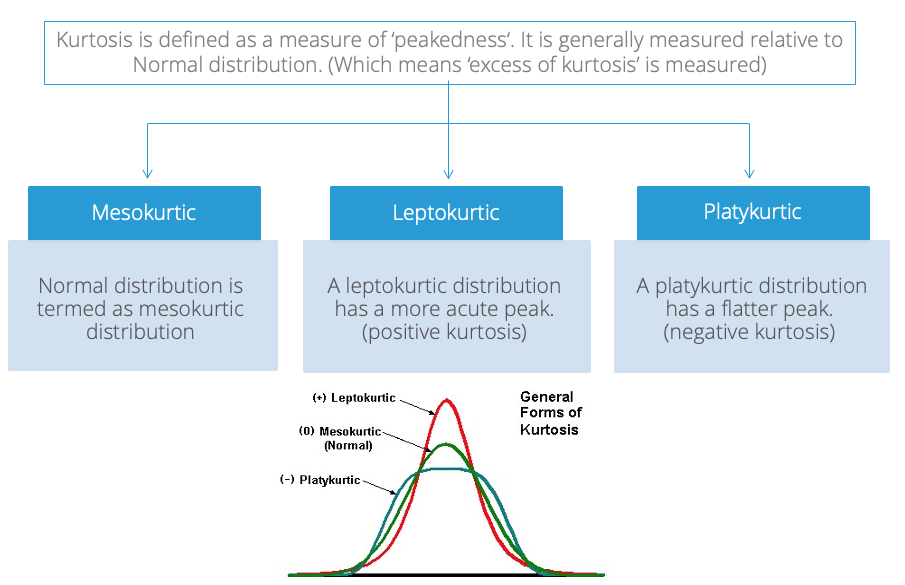
Normal Distribution
\(Y_1\) ∼ \(N(\mu, \sigma)\)
\(Y_1\) ∼ Normal(100, 15)
\(Y_2\) ∼ Normal(100, 15)
\(Y_n\) ∼ Normal(100, 15)
Or for all observations,
- \(Y_i\) ∼ Normal(100, 15)
Normal Distribution
Everyone’s score comes from the same distribution
The average score should be around 100
Scores should be spread out by 15
Scores should follow bell-shaped curve
Probability and Standard Normal Distribution: Z-Scores
\[Z(x) = \frac{x - \mu}{\sigma}\]- Z-score /standard score tells us how far away any data point is from the mean, in units of standard deviation
Standard Normal Distribution
- Properties of standard normal
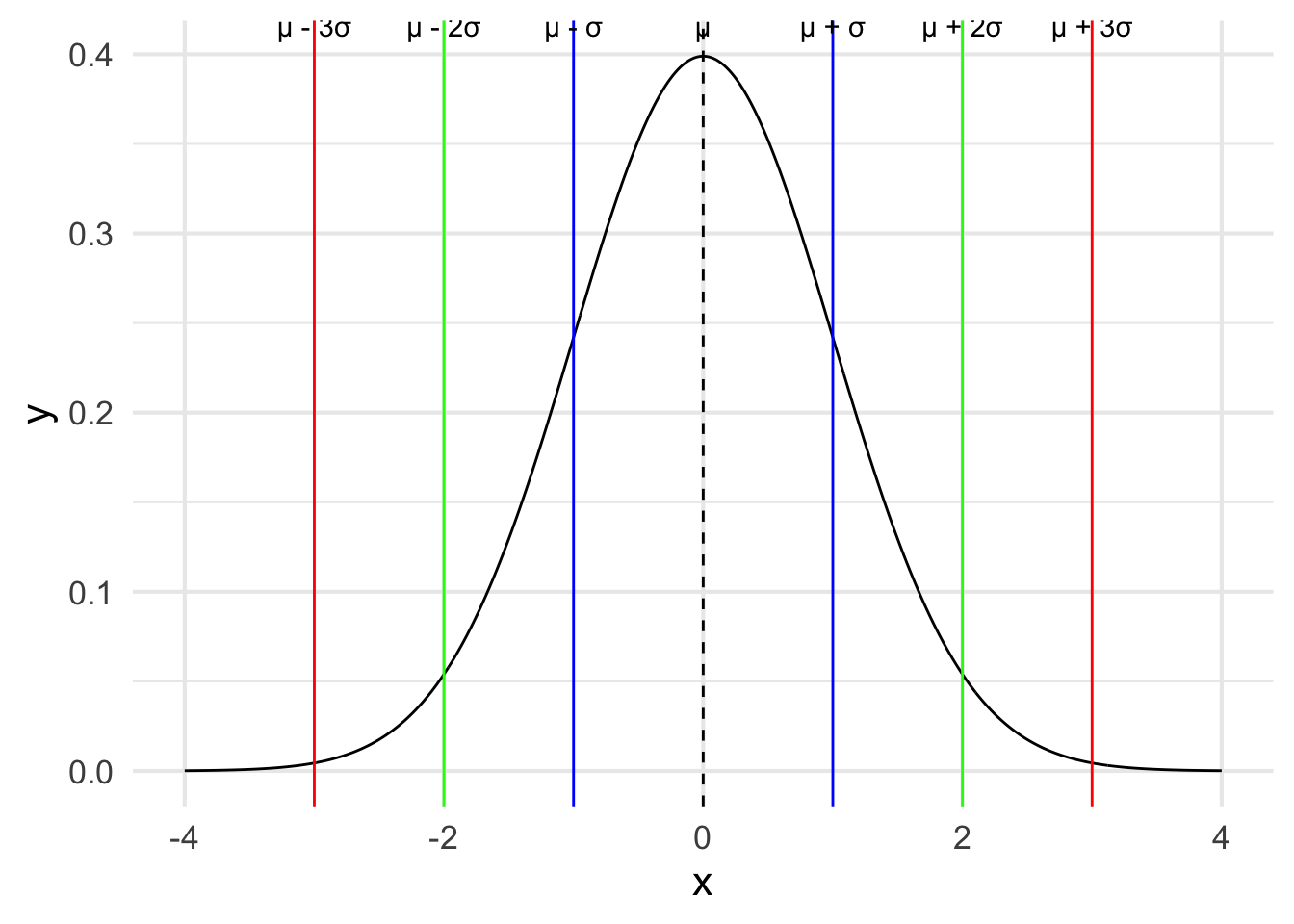
- Empirical Rule
- 68.27% of the data falls within one standard deviation (sigma) of the mean
- 95.45% falls within two sigma
- 99.73% falls within three sigma
- Empirical Rule
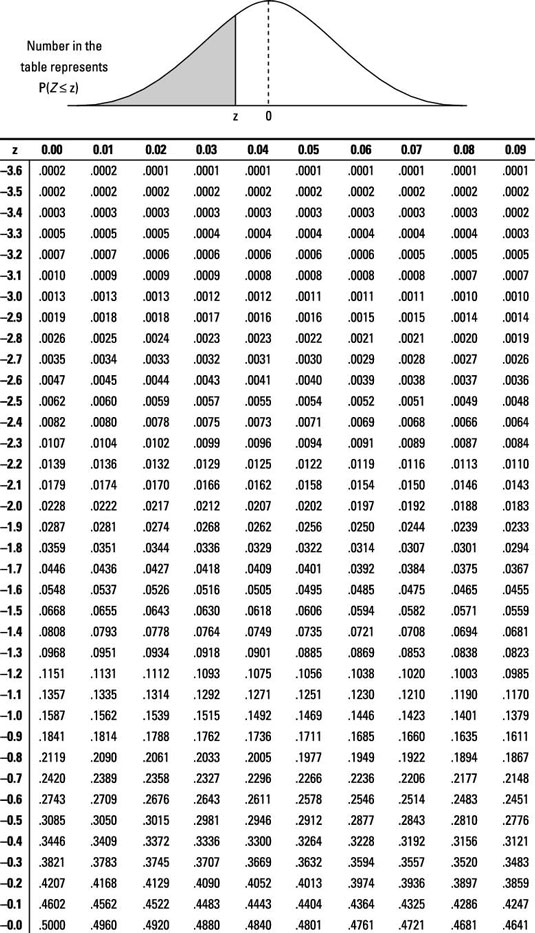
Z tables
- NO MORE TABLES
Using R
dnorm(): Z-score to density (height) (PDF)pnorm(): Z-score to area (CDF)qnorm(): area to Z-score
Using R
pnormfunction: Z-score to area (CDF)
\[ P(X <= x) \]
If you calculated a Z-score you can find the probability of a Z-score less than(lower.tail=TRUE) or greater than (lower.tail=FALSE) by using pnorm(Z).
Using R: pnorm
- What is the z-score?
- What percentage is below this z-score?
- Above
Using R: pnorm
- Calculate z-score
- Percentage below IQ score of 55?
- Percentage above IQ score of 55?
Using R: pnorm
- Percentage between IQ score of 120 and 159?
Package PnormGC
- Percentage between IQ score of 120 and 159?
Package PnormGC
What about \(P(X \leq 69)\)
Using R: qnorm
qnorm(): area to z-scores
What is the score for which 5% lies above?
Practice pnorm
Suppose that BMI measures for men age 60 in a Heart Study population is normally distributed with a mean (μ) = 29 and standard deviation (σ) = 6. You are asked to compute the probability that a 60 year old man in this population will have a BMI less than 30.
What is the z-score?
What is the probability a 60 year old man in this population will have a BMI between 30 and 40?
Practice: qnorm
Suppose that SAT scores are normally distributed, and that the mean SAT score is 1000, and the standard deviation of all SAT scores is 100. How high must you score so that only 10% of the population scores higher than you?
Z-scores in practice
- Standardization
- Scaling your measures so they are are comparable
- Does not change anything about the data!
Standardized Scores
A standardized score is a Z-score that has been transformed to have a \(\mu\) and \(\sigma\) different from standard normal
IQ
- \(\mu = 100\) \(\sigma = 15\)
SAT
- \(\mu =500\) \(\sigma = 100\)
T-score
- \(\mu = 50\) \(\sigma = 10\)
New score = new sd(Z) + New mean